Dataset
The dataset used for this study was collected using a questionnaire. The questionnaire was designed to collect data for the COVID-19 period, keeping in view all the essential attributes that are needed to identify students’ individual performance. The questionnaire was designed through Google Forms and was distributed among different universities in Pakistan to collect data from higher education students (bachelor’s, master’s, and doctoral degree students).
The data collected from student surveys are presented in
Table 2. Only 15 out of the thirty sampled questions were chosen as the best attributes for conducting the research necessary to achieve precision education. The total number of samples collected from higher education students was 4000. These responses were reduced to 2200 by selecting only those students who were enrolled in degrees of computer science and management science during the COVID-19 period. This sampled data included bachelor’s, master’s, and Ph.D. students in proportions of 60%, 30%, and 10%, respectively. Fifteen sample questions that were considered to be best were treated as the attributes to study the impacts of these 15 factors on the performance of students during the COVID-19 period. The primary attributes considered are related to on-site classes, medium of online classes, workload during online sessions, student satisfaction level, mentor feedback, availability of resources required for online classes, issues regarding lectures and practical work, preferred method of mentorship, experience of using digital platforms, and participation during lectures.
The sample questions used for surveys are presented in
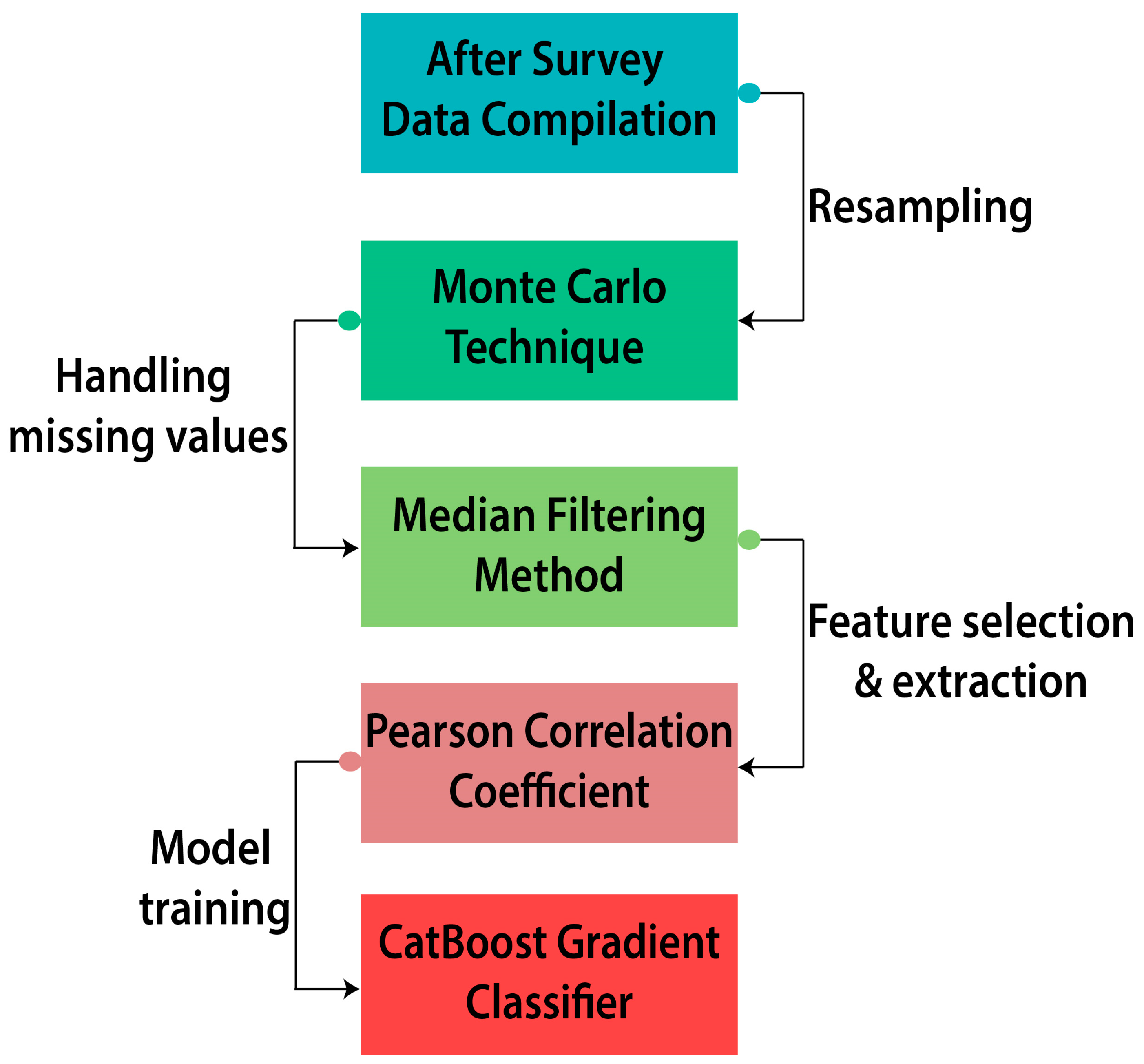
Table 3. Responses from students to these questions were later used as potential performance evaluation criteria for each degree student. Then, the proposed framework’s phases were followed. The Monte Carlo method was chosen to rebalance the data. Next, data were preprocessed to eliminate outliers and eliminate missing data. Using the label encoding technique, categorical data characteristics were converted to numeric values through preprocessing. This study’s model was trained using Google Collaboratory’s “Catboost classifier” for machine learning. Python’s Numpy and Pandas libraries were utilized to perform effective numerical operations on the data.
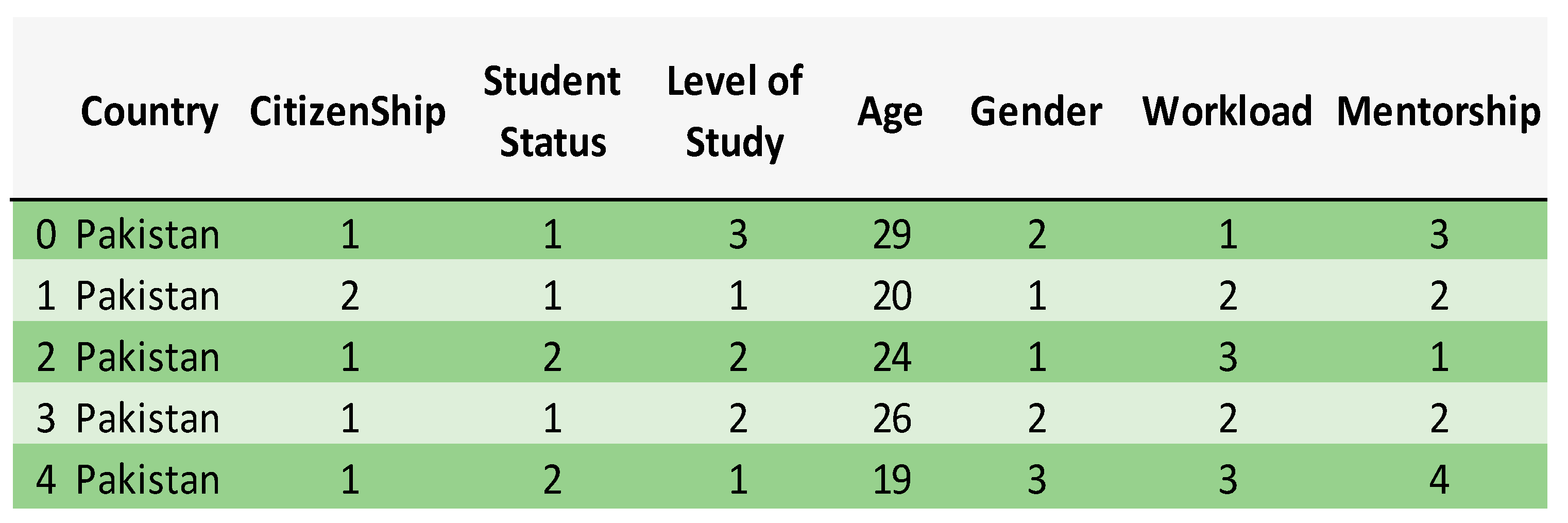
Figure 4 demonstrates a sample of the pre-processed data that was converted to numeric values by the Catboost classifier. One is a Pakistani national, while the other two are dual citizens with another country. This refers to students with dual nationalities who were studying in Pakistan during COVID-19. Regarding Student Status, 1 corresponds to full-time student status, while 2 corresponds to part-time student status. In the classification of students according to their level of education, levels 1, 2, and 3 correspond to bachelor’s, master’s, and doctoral degrees, respectively. For Gender, 1 corresponds to male students, 2 to female students, and 3 to students who did not wish to disclose their gender. Regarding Workload, 1, 2, and 3 correspond to increased, decreased, and average, respectively. For Mentorship 1, 2, 3, and 4 correspond to video-call, audio-call, e-mail, and social networking, respectively, i.e., the online mentorship methods used to instruct students.
The central tendency measure was used for imputing missing values in data. The median interpolation method was applied on a data frame for this purpose. The Pearson correlation technique was used to determine the relationship of features with one another to select the best of the features. Through this, feature selection was performed.
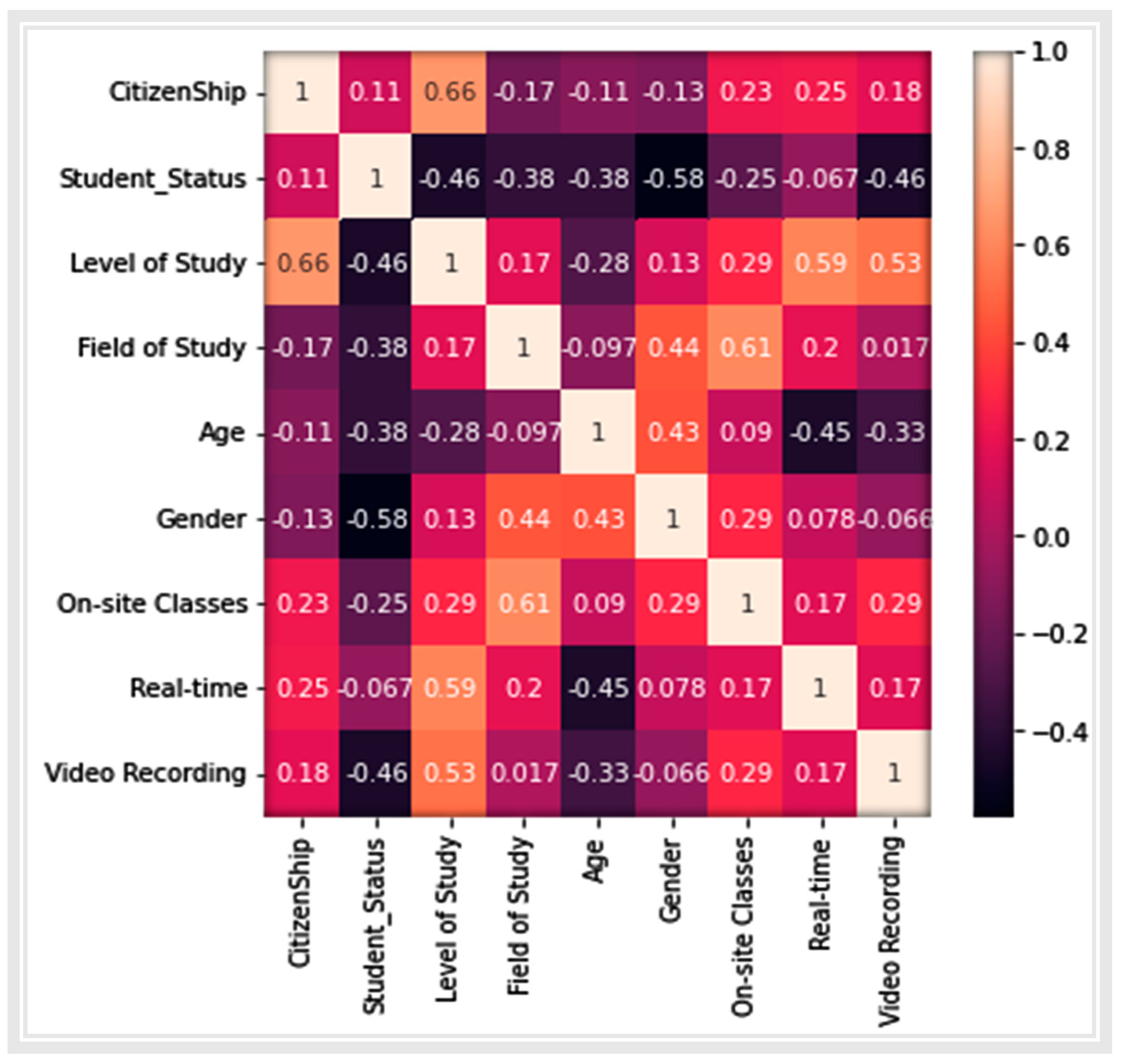
Figure 5 represents a matrix that shows the dependency of some of the features that accurately play a part in the prediction of students’ performance. The value calculated for each feature depicts the strength of the relationship that exists between these features.
The value of correlation lies between −1 to +1. A value of +1 illustrates those values that have a positive linear relationship; 0 depicts no correlation; and −1 represents a total negative relationship between features. Potential features were thus selected using a correlation matrix. The students’ outcomes were affected by a combination of these factors. Some students were not affected at all by certain factors, while others were profoundly impacted by them.
Feature importance analysis is the most important aspect of machine learning because it enables researchers to determine the significant features that are useful for making predictions. Due to this analysis, it has become simple to determine how much each data feature contributes to the model’s final outcome.
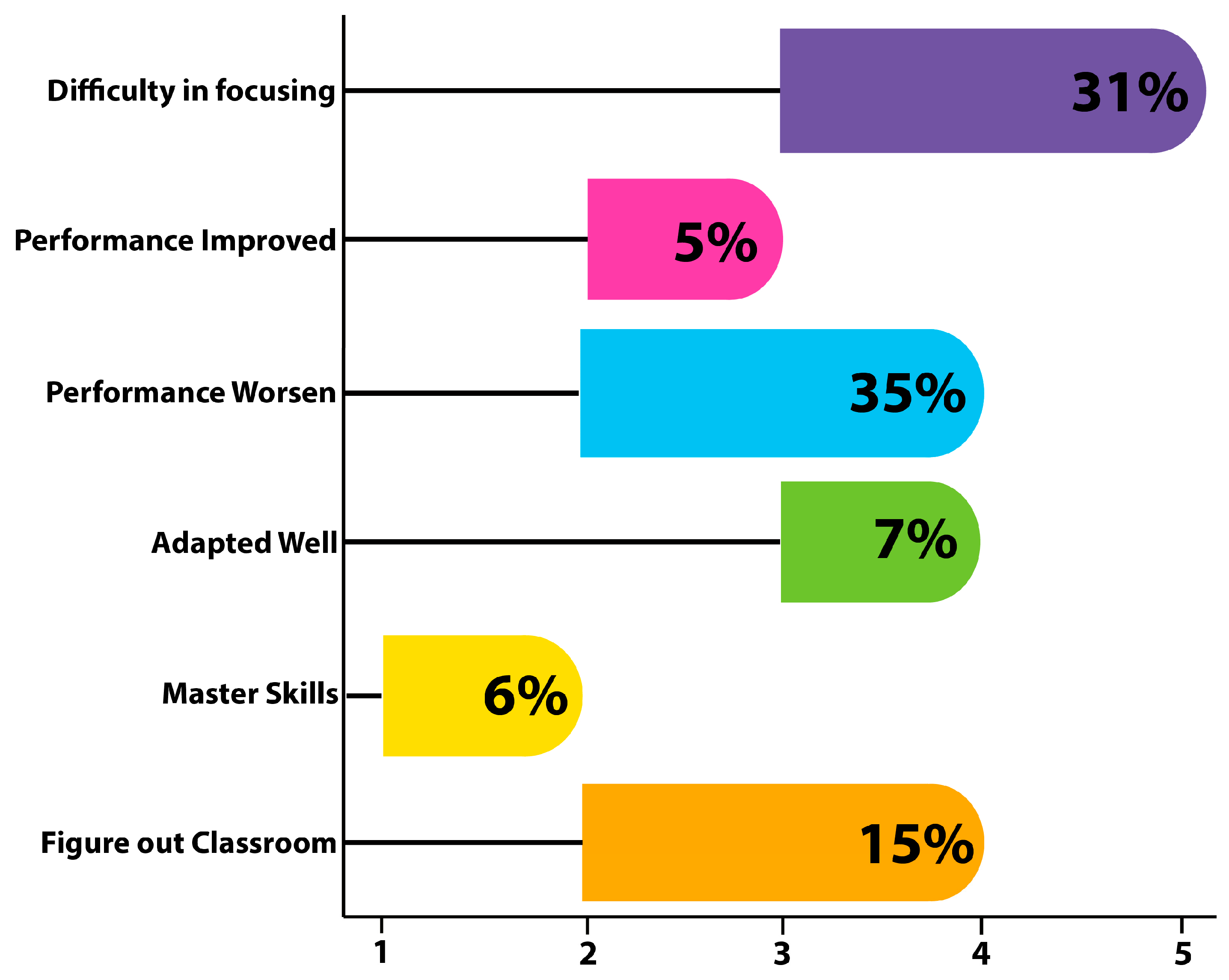
Figure 6 depicts the effect of a new learning and teaching environment on students’ final performance during an online session.
In
Figure 6, the Y-axis represents the factors and the X-axis represents the degree to which each factor has affected a student’s performance. In
Figure 6, a value of 4–5 indicates that difficulties in focusing during online sessions had a significant impact on 31% of students, followed by a decline in performance affecting 35% of scholars, adaptation to these environments affecting 7% of students, and mastery skills affecting 6% of students, indicating that these factors all had an effect to some degree during online sessions. The performance improvement plotted between 2 and 3 indicates that, during the entire online session, students’ performance improved marginally, affecting a total of 5% of students. During the lockdown period of COVID-19, students encountered a greater number of challenges relating to online study. Due to increased difficulty encountered by students during online sessions, performance was negatively impacted.
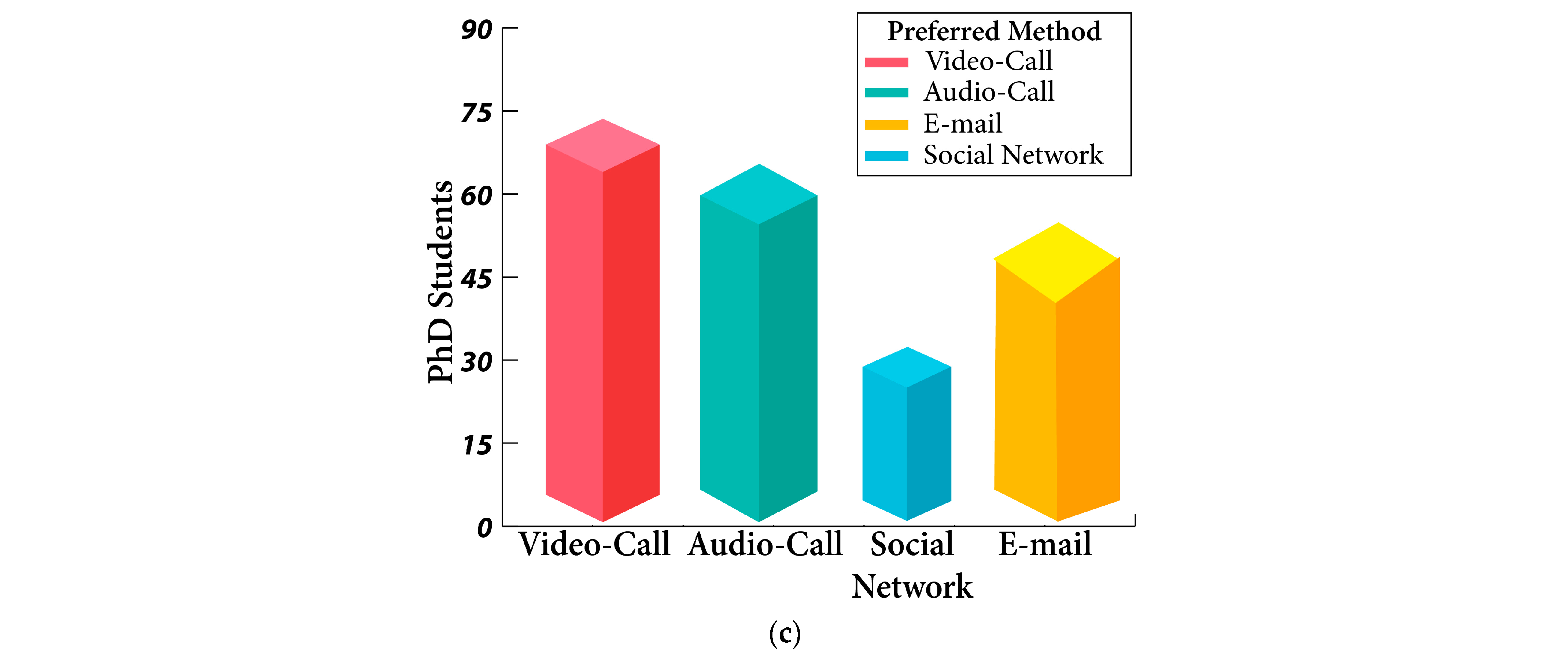
Figure 7 demonstrates the type of mentorship that was utilized to facilitate student learning.
Figure 7a indicates that video and audio calls were the most popular tutoring methods for bachelor’s students, while email and social media were the least popular.
Figure 7b demonstrates that video calls and social networks were the most popular tutoring platforms for master’s level students.
Figure 7c demonstrates that audio calls, followed by video calls, were utilized most frequently by teachers to guide and support PhD students.
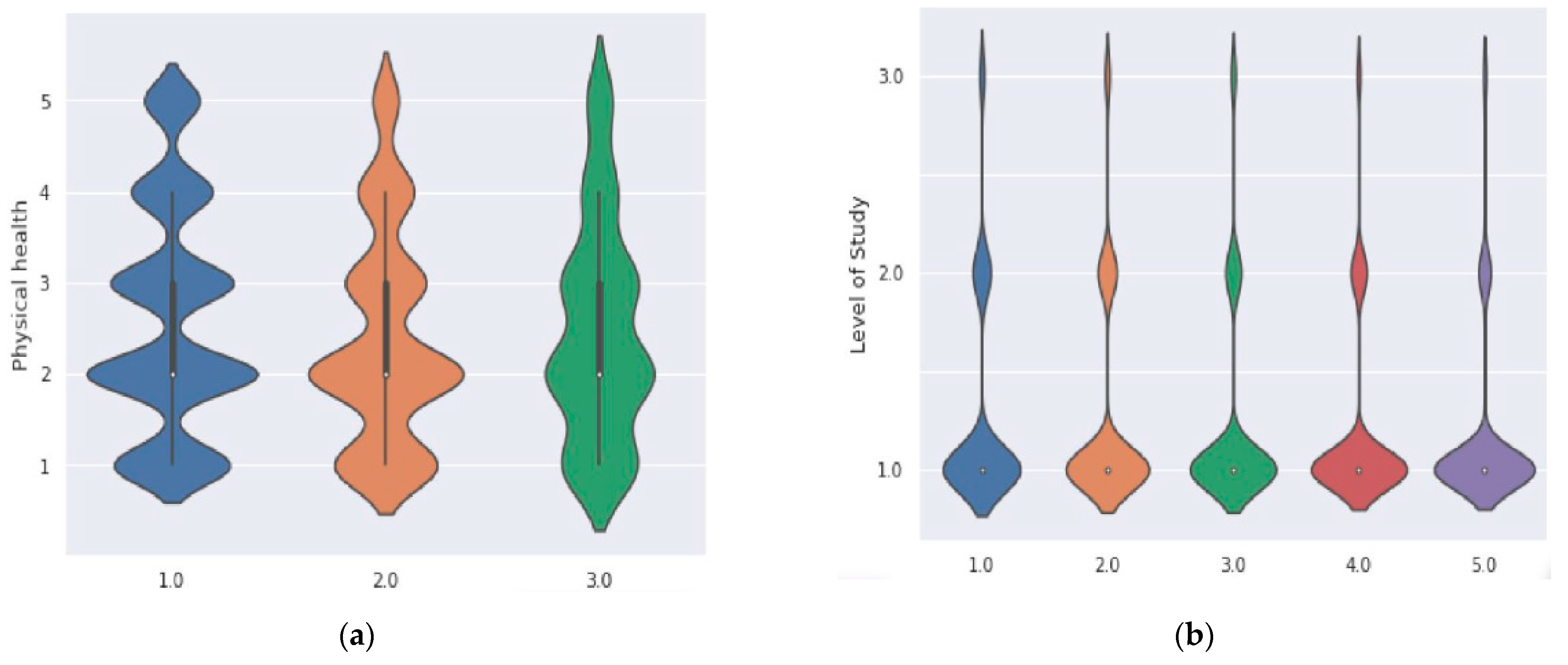
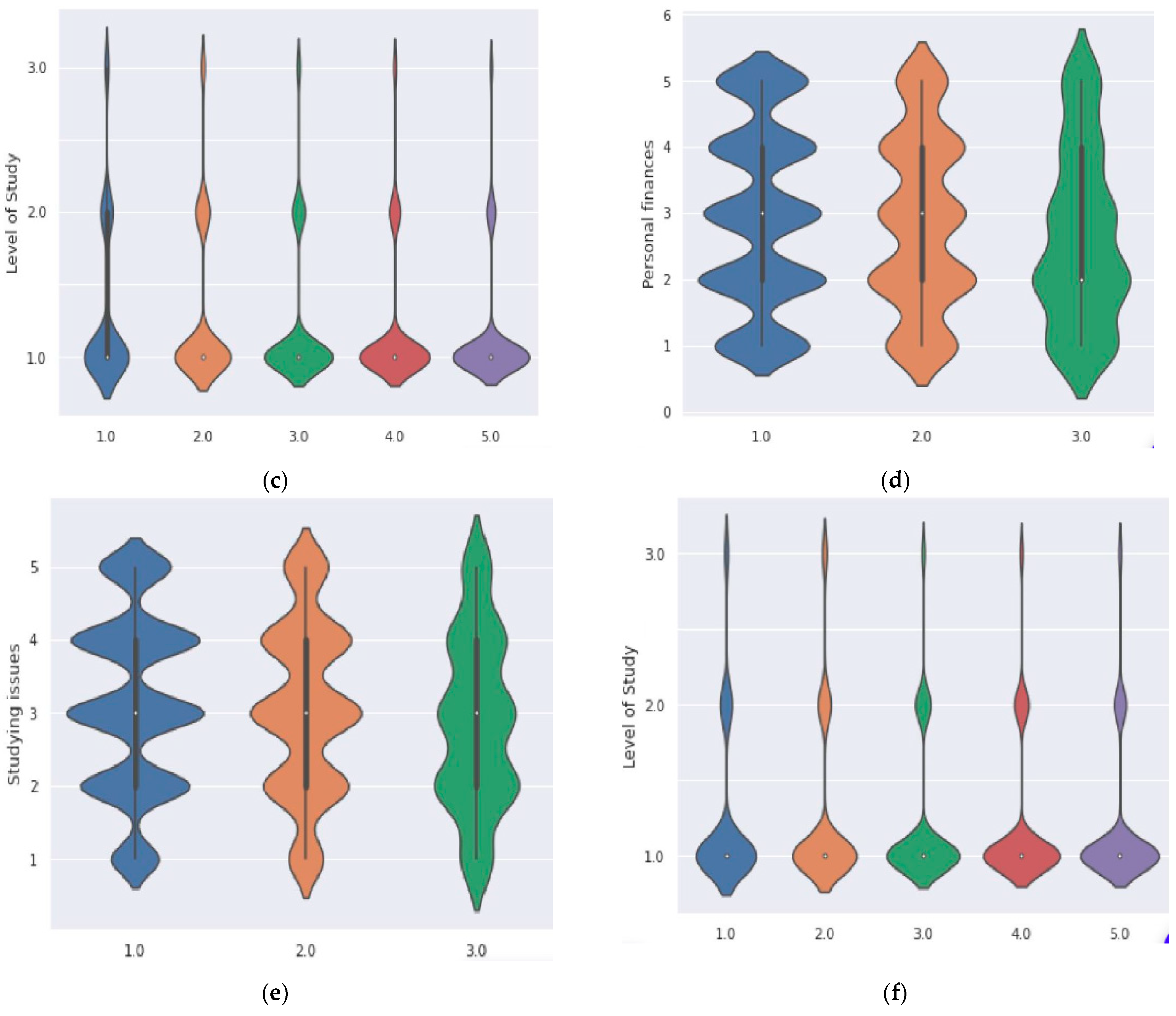
Figure 8 depicts a data visualization of how personal circumstances (physical health, mental health, future education, personal finances, studying issues, and professional career) affected each group of studies (1 corresponds to bachelor’s, 2 to masters, and 3 to doctoral).
Figure 8a depicts the physical health for each level of study, where 1 corresponds to no effect, 2 to a small effect, and 3 to a strong effect. Therefore, ascending from 1 to 5 represents an increase in the intensity of effectiveness. In this manner, the figure demonstrates that the effects of these factors vary for each student. Regarding physical health, bachelor’s degree students were most affected, followed by master’s degree students, and then doctoral degree students. Each group’s mental health is depicted in
Figure 8b. From 1 to 5, the intensity of its effectiveness increases. The mental health of bachelor’s students was most affected, while that of doctoral students was least affected. The impact of future education, personal finances, studying issues, and professional career are shown in
Figure 8c–f, one for each level of study. The effectiveness of each factor on these students is quantified on a scale from 1 to 5.
After feature selection, supervised learning was adapted to train the model. Out of the 2200 responses collected, data were split between training and testing phases with a proportions of 70% and 30%, respectively. Using that 70% of the data, the model was trained successfully using the Catboost algorithm. The model attained accuracy of 96.8% in achieving precision education for students.
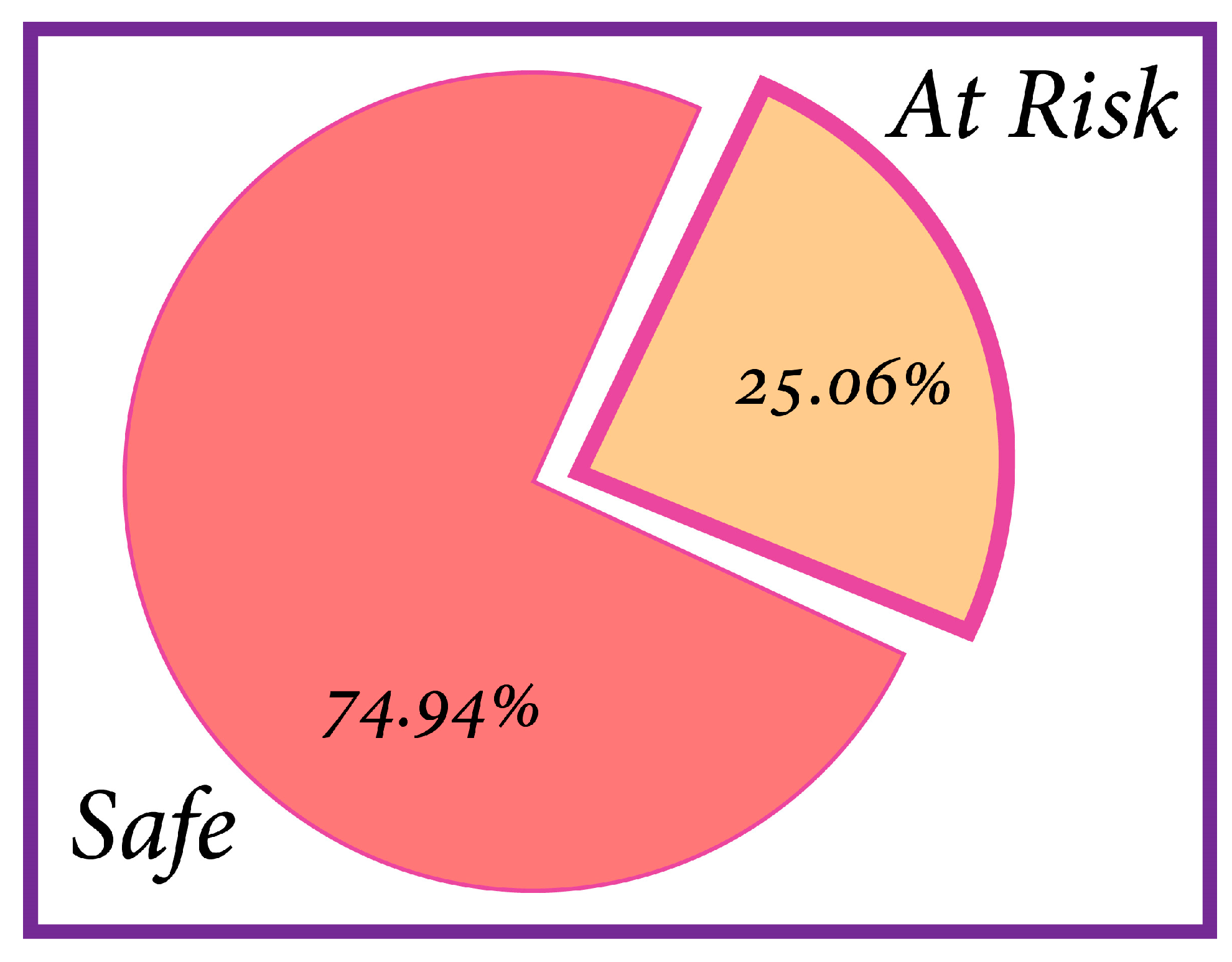
Figure 9 illustrates the pictorial view of the whole dataset, in which 74.94% of students have the safe label and 25.06% students are shown to be at risk of failure.
Validation of the model’s performance revealed 96.2% precision, 94.6% recall, and 92.6% F-measure for the safe class. For the at-risk classification, the achieved precision, recall, and F-measure were 97.4%, 96.1%, and 96.6%, respectively.
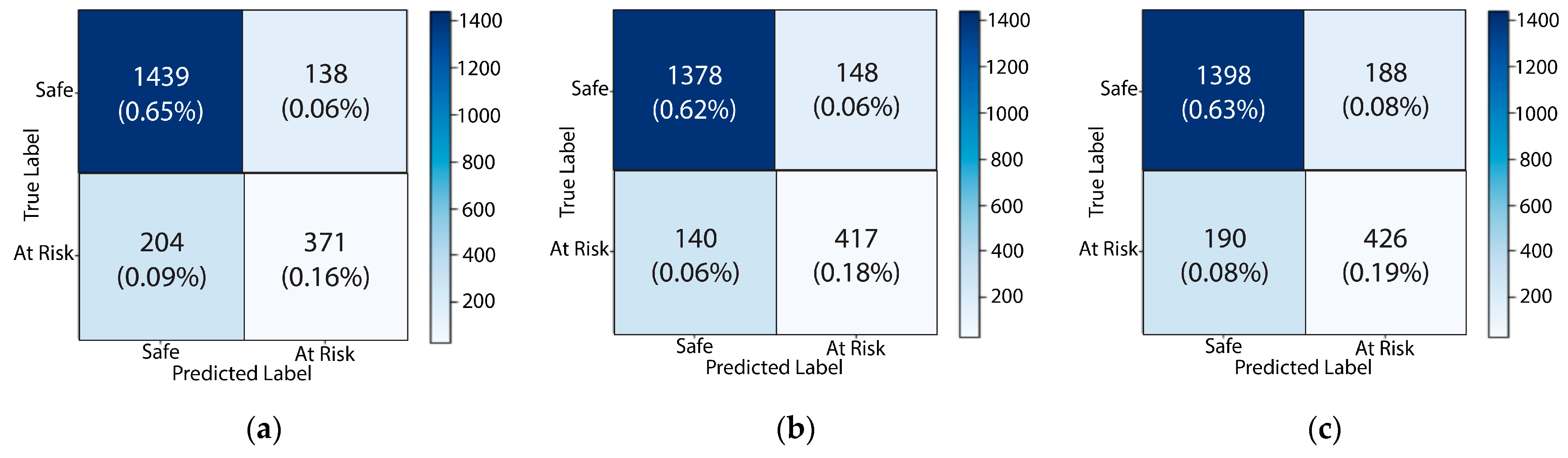
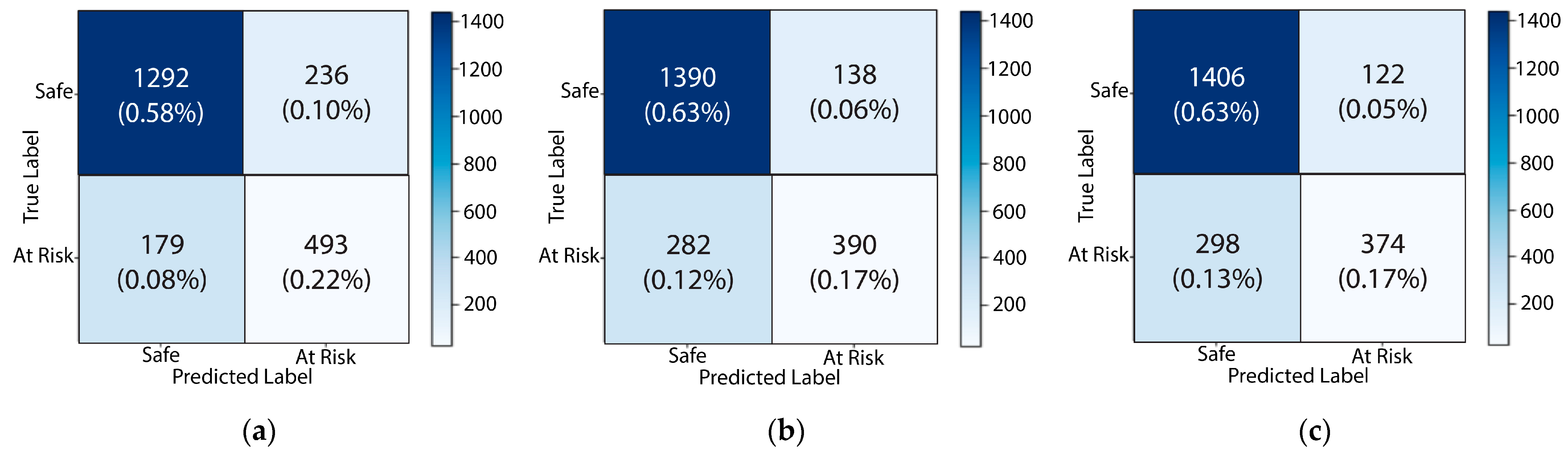
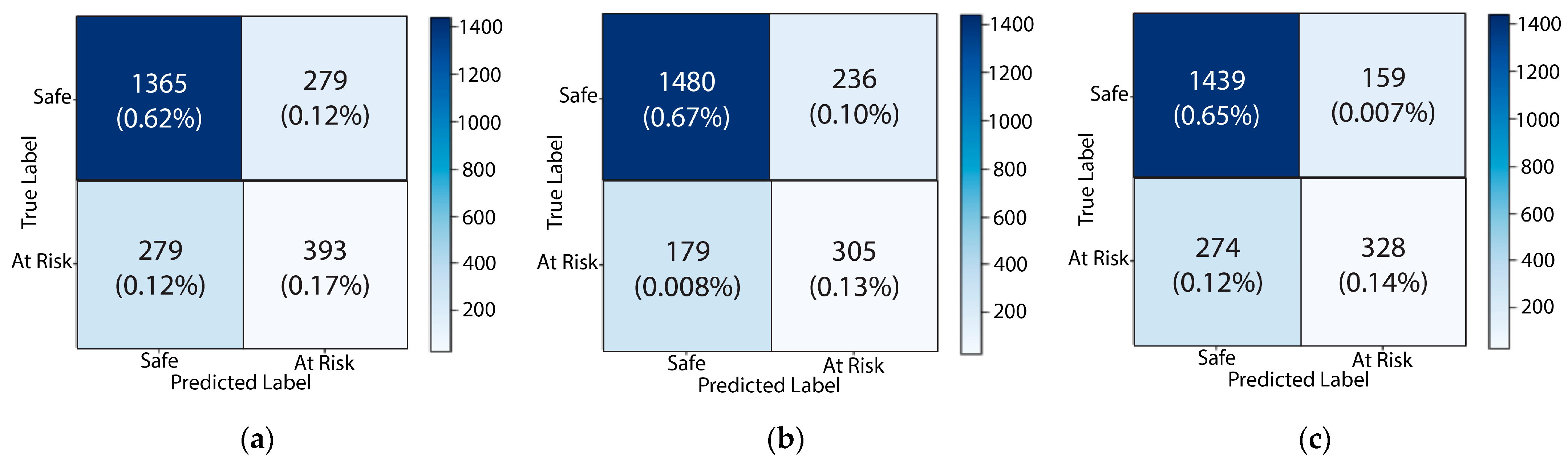
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 plot the confusion matrices for each of the individual attributes (Q1–Q15) that influenced the performance of students. In these matrices, 0 corresponds to the safe class and 1 corresponds to the at-risk class.
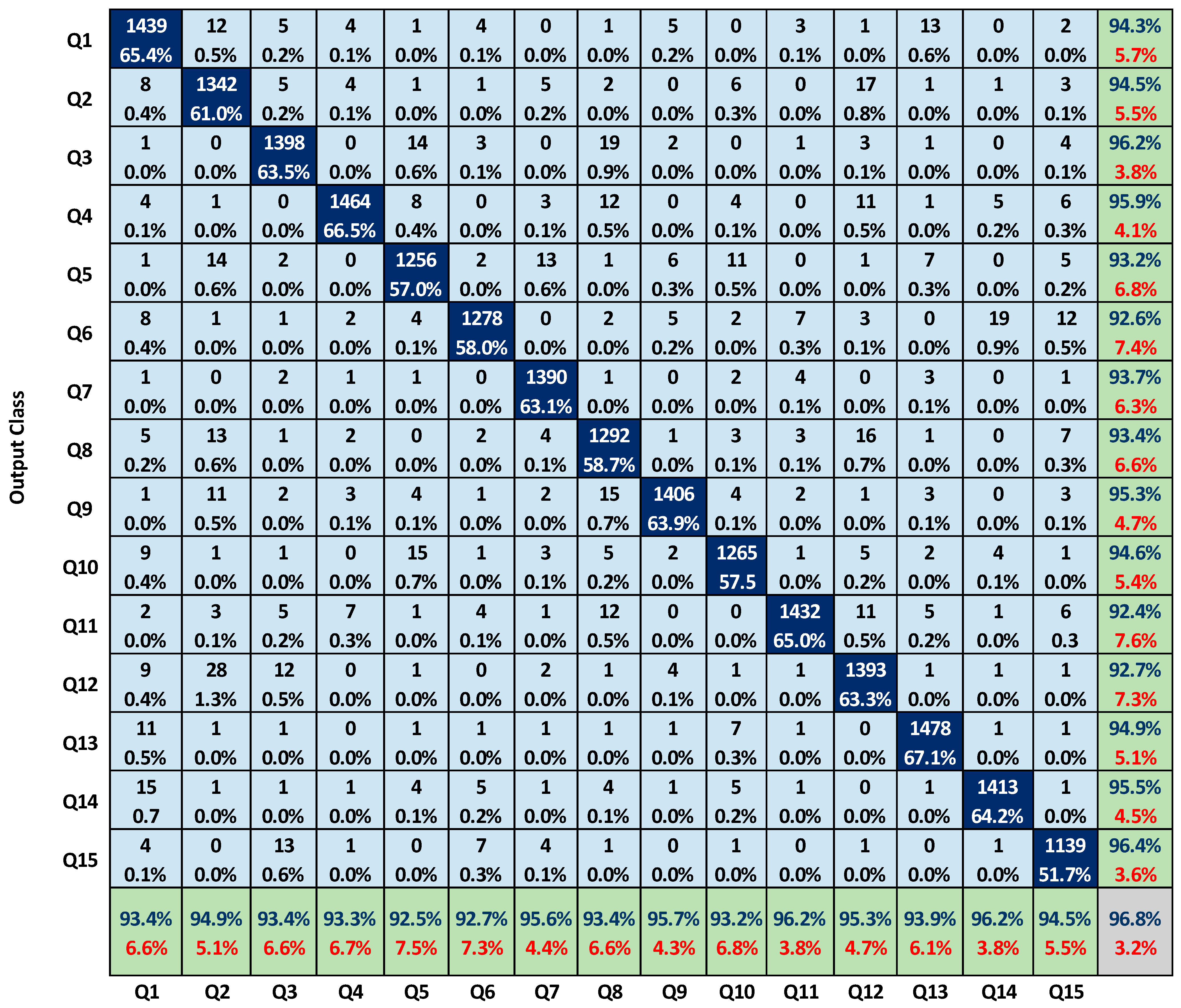
As shown in
Figure 15, the full confusion matrix takes into account all the factors that affect students’ performance in the pursuit of precision education. The attribute-by-attribute evaluation of the trained model is represented by a full confusion matrix for all survey questions. Overall, a 96.8% accuracy rate was achieved, with a 3.2% error rate. In green cells, the achieved precision and error rates are displayed for each of the 15 attributes used to correctly predict the output class. The remaining color blocks show, respectively: the highest weighted factor for each question (in dark blue); the maximum accuracy (and error rate) achieved (in grey); and the analyzed weightage percentage (in light blue) with the relating error of each attribute.
Table 4 represents a comparison of the accuracy achieved by previous studies, as well as the error rate and methodology used to conduct each study, with those of our study. As shown in the table, the accuracy values achieved by the models of other studies are comparatively lower than that of the CatBoost model of this study. Hence, it is shown that the CatBoost model is more efficient than the models of existing studies. The experimental results demonstrate that the Catboost classifier is optimal for precision education, as the F-measure is 92.6% for the safe class and 96.6% for the at-risk class, as shown in
Table 5 for the precision, recall, F-measure, and ROC area of both classes. This classifier accurately predicted student performance with the provided data and features. Thus, this research enabled the development of a generalizable model capable of predicting the early academic performance of students, so that those who are at risk of dropping out may receive appropriate interventions, especially during the lock-down period of COVID-19.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}