

Identification of Genes Associated with the Impairment of Olfactory and Gustatory Functions in COVID-19 via Machine-Learning Methods

 , and
, and
Abstract
:1. Introduction
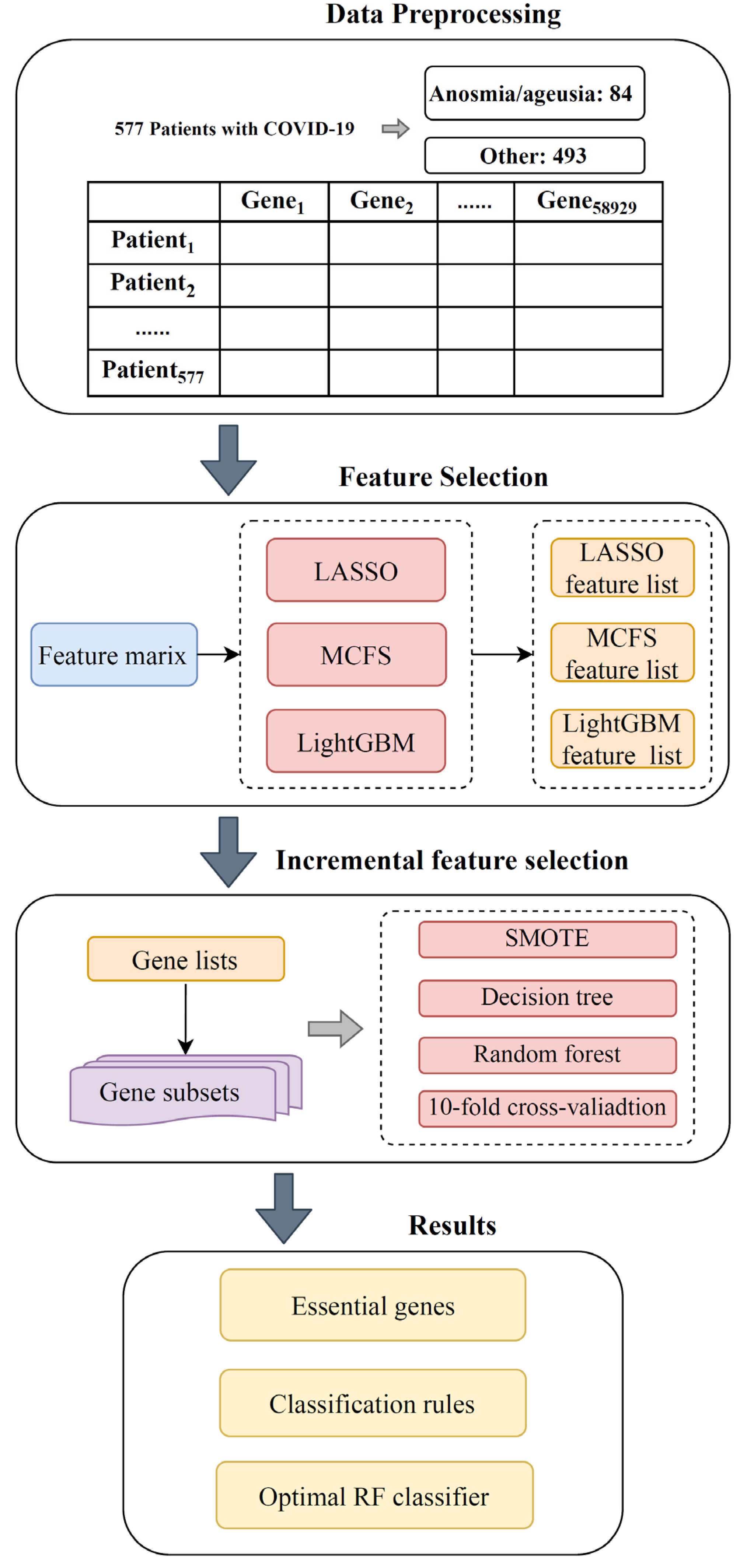
2. Materials and Methods
2.1. Data
2.2. Feature Selection Methods
2.3. Incremental Feature Selection
2.4. Synthetic Minority Oversampling Technique
2.5. Classification Algorithm
2.6. Performance Evaluation
3. Results
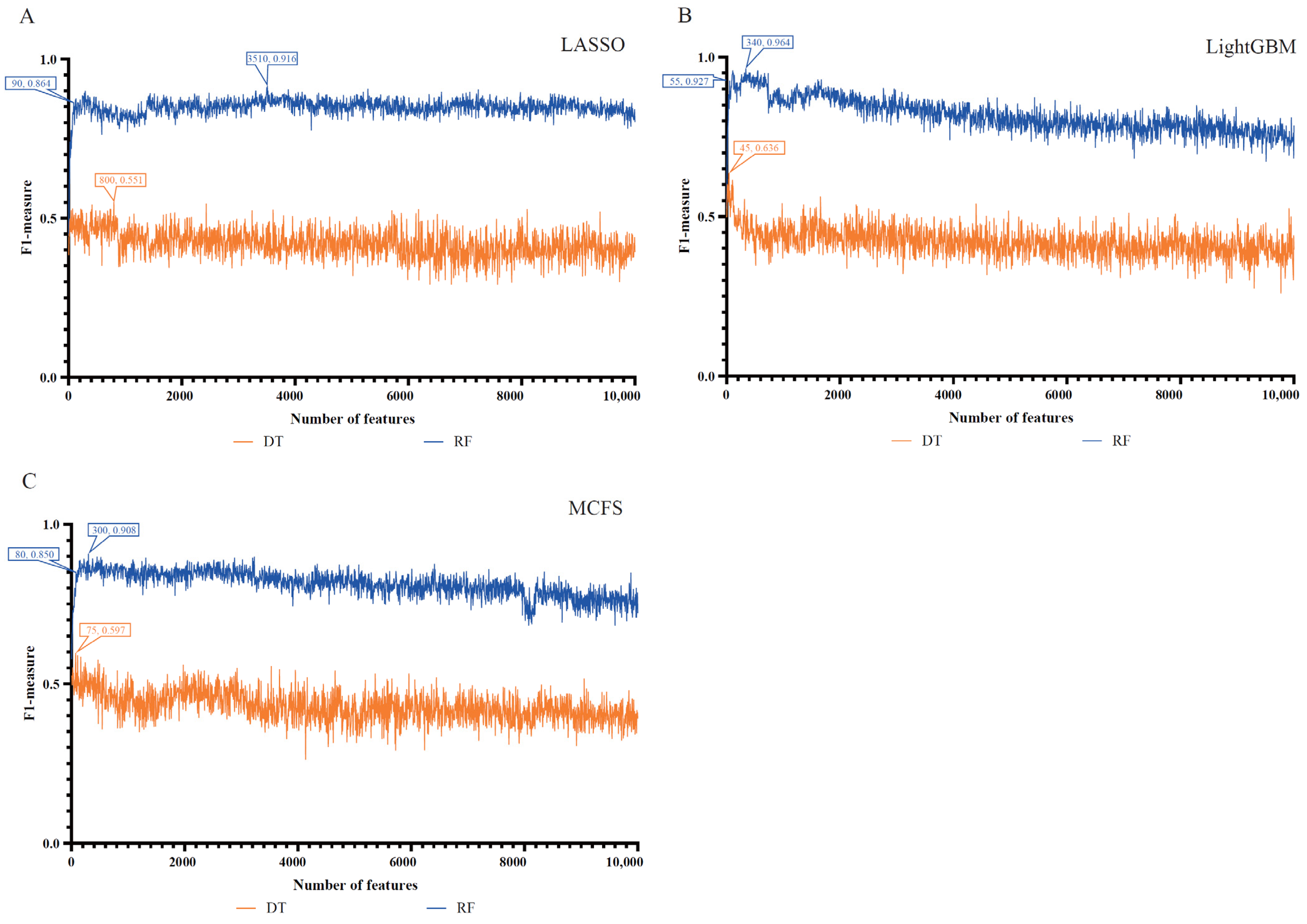
3.1. Feature Ranking Results
3.2. Results of Incremental Feature Selection
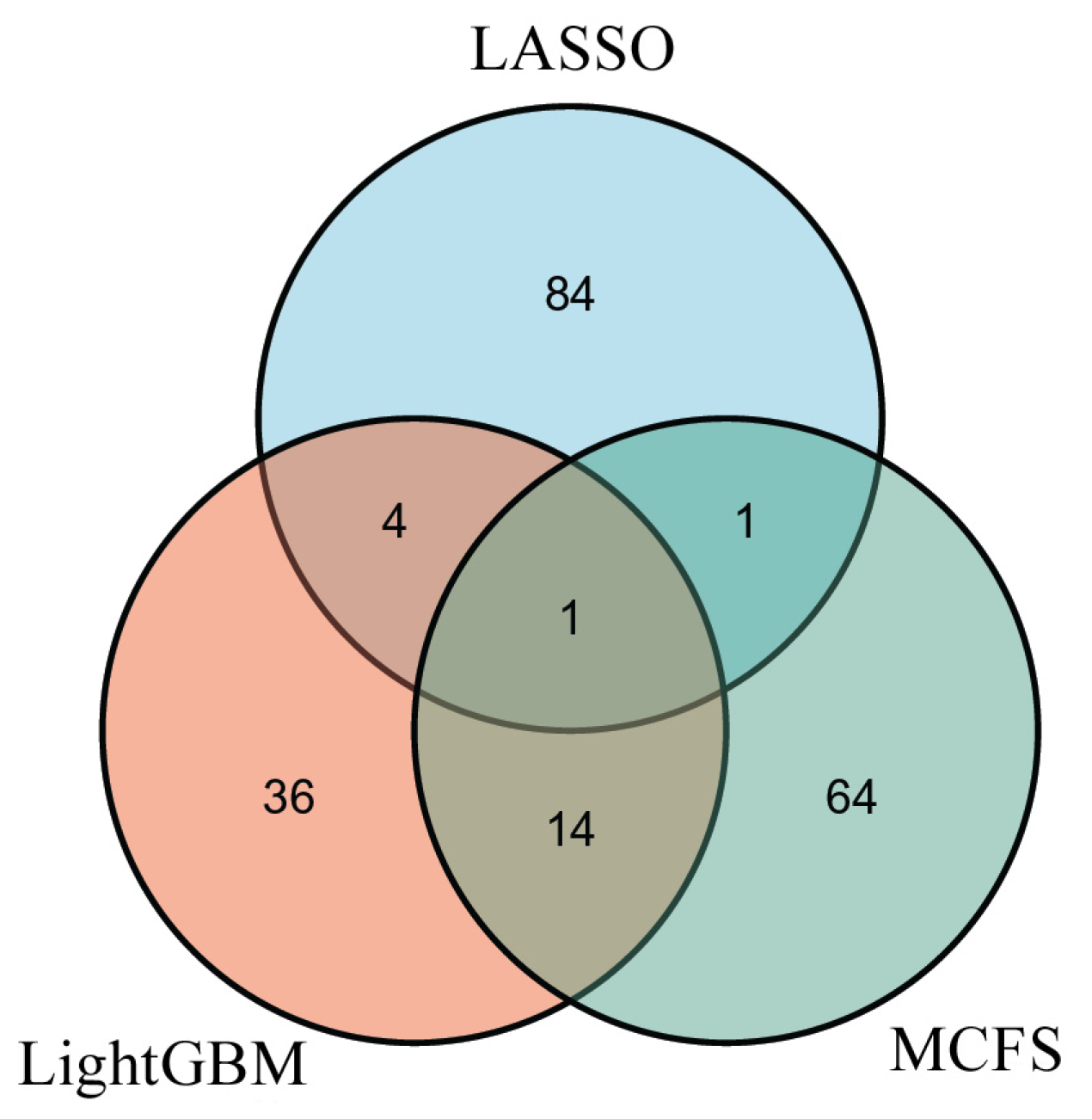
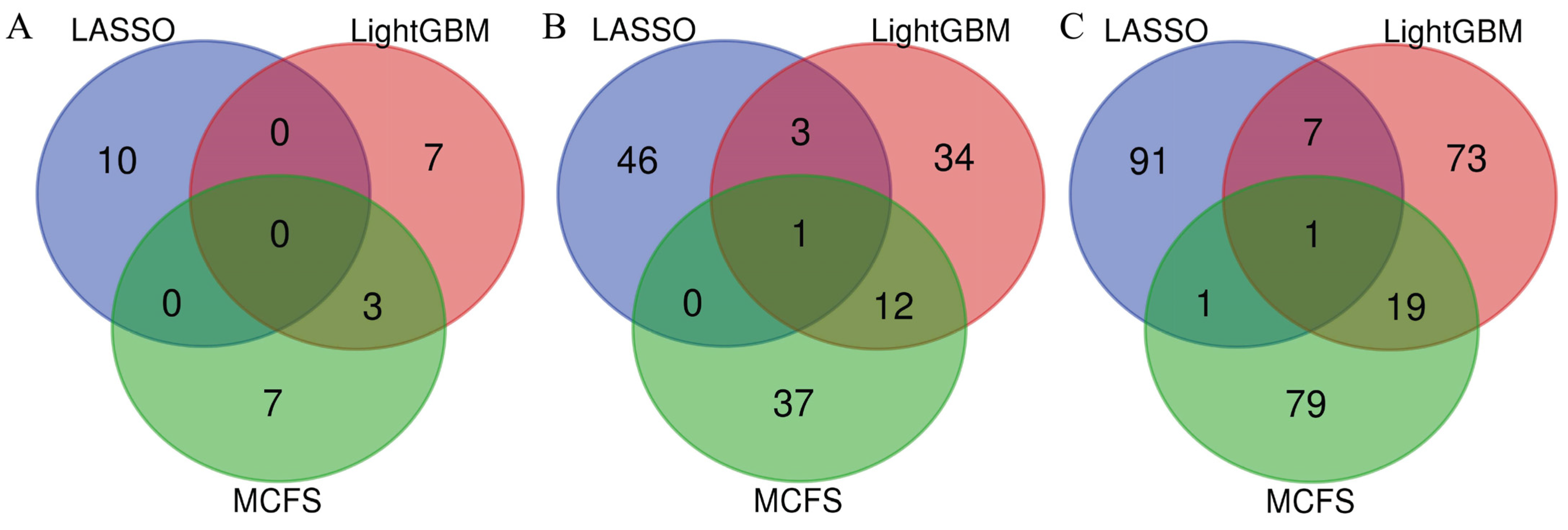
3.3. Intersection of Essential Features on Different Feature Lists
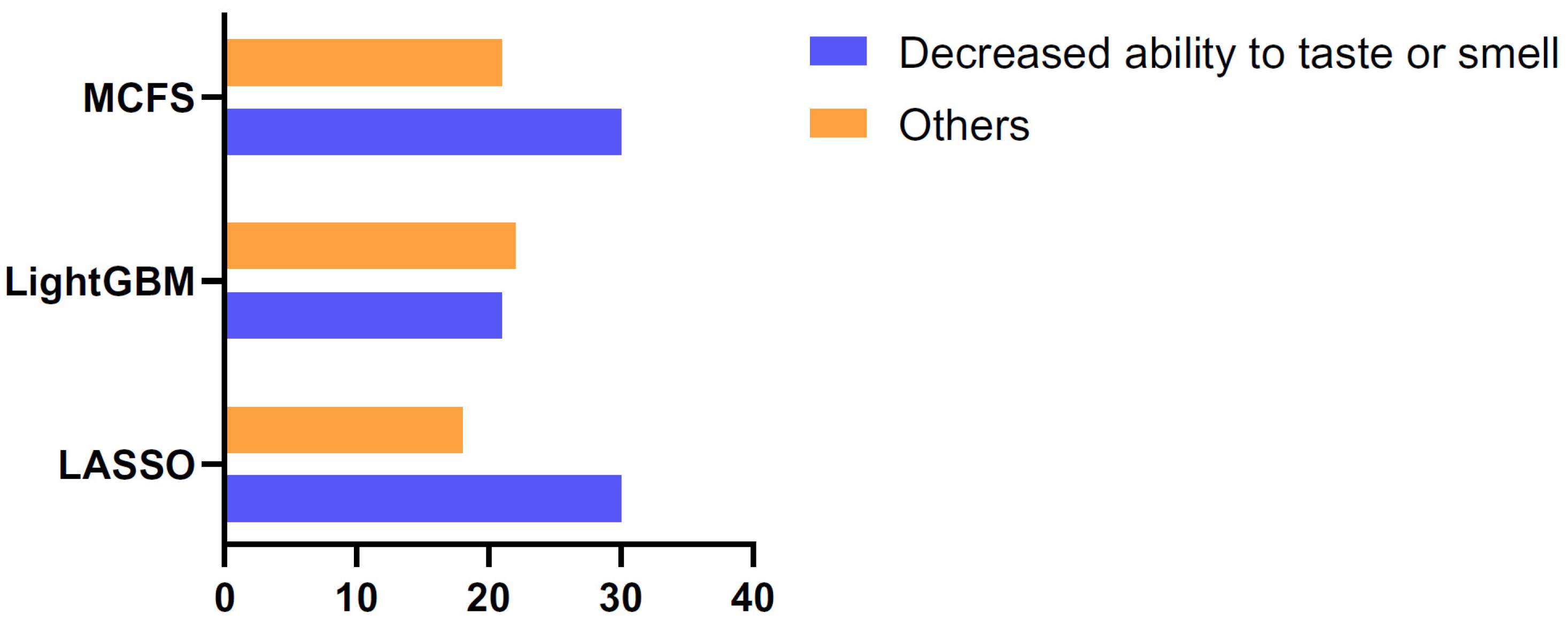
3.4. Classification Rules
4. Discussion
4.1. Relationships of Top Features in Different Lists
4.2. Biomarkers Predicted by One or More Feature Selection Methods
4.3. Quantitative Rules for COVID-19 Patient Clustering
4.4. Limitation of This Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, B.; Guo, H.; Zhou, P.; Shi, Z.-L. Characteristics of SARS-CoV-2 and COVID-19. Nat. Rev. Microbiol. 2021, 19, 141–154. [Google Scholar] [CrossRef] [PubMed]
- Baud, D.; Qi, X.; Nielsen-Saines, K.; Musso, D.; Pomar, L.; Favre, G. Real estimates of mortality following COVID-19 infection. Lancet Infect. Dis. 2020, 20, 773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Struyf, T.; Deeks, J.J.; Dinnes, J.; Takwoingi, Y.; Davenport, C.; Leeflang, M.M.; Spijker, R.; Hooft, L.; Emperador, D.; Domen, J. Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19. Cochrane Database Syst. Rev. 2022, 5, CD013665. [Google Scholar] [PubMed]
- Larsen, J.R.; Martin, M.R.; Martin, J.D.; Kuhn, P.; Hicks, J.B. Modeling the onset of symptoms of COVID-19. Front. Public Health 2020, 8, 473. [Google Scholar] [CrossRef] [PubMed]
- Hopkins, C.; Surda, P.; Whitehead, E.; Kumar, B.N. Early recovery following new onset anosmia during the COVID-19 pandemic—An observational cohort study. J. Otolaryngol.-Head Neck Surg. 2020, 49, 26. [Google Scholar] [CrossRef] [PubMed]
- Boscolo-Rizzo, P.; Borsetto, D.; Fabbris, C.; Spinato, G.; Frezza, D.; Menegaldo, A.; Mularoni, F.; Gaudioso, P.; Cazzador, D.; Marciani, S.; et al. Evolution of altered sense of smell or taste in patients with mildly symptomatic COVID-19. JAMA Otolaryngol.–Head Neck Surg. 2020, 146, 729–732. [Google Scholar] [CrossRef]
- Glezer, I.; Bruni-Cardoso, A.; Schechtman, D.; Malnic, B. Viral infection and smell loss: The case of COVID-19. J. Neurochem. 2021, 157, 930–943. [Google Scholar] [CrossRef]
- Meunier, N.; Briand, L.; Jacquin-Piques, A.; Brondel, L.; Pénicaud, L. COVID 19-induced smell and taste impairments: Putative impact on physiology. Front. Physiol. 2021, 11, 625110. [Google Scholar] [CrossRef]
- Srinivasan, M. Taste dysfunction and long COVID-19. Front. Cell. Infect. Microbiol. 2021, 11, 716563. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Dramiński, M.; Rada-Iglesias, A.; Enroth, S.; Wadelius, C.; Koronacki, J.; Komorowski, J. Monte carlo feature selection for supervised classification. Bioinformatics 2007, 24, 110–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.A.; Setiono, R. Incremental feature selection. Appl. Intell. 1998, 9, 217–230. [Google Scholar] [CrossRef]
- Soares-Schanoski, A.; Sauerwald, N.; Goforth, C.W.; Periasamy, S.; Weir, D.L.; Lizewski, S.; Lizewski, R.; Ge, Y.; Kuzmina, N.A.; Nair, V.D.; et al. Asymptomatic SARS-CoV-2 infection is associated with higher levels of serum il-17c, matrix metalloproteinase 10 and fibroblast growth factors than mild symptomatic COVID-19. Front. Immunol. 2022, 13, 821730. [Google Scholar] [CrossRef]
- Sauerwald, N.; Zhang, Z.; Ramos, I.; Nair, V.D.; Soares-Schanoski, A.; Ge, Y.; Mao, W.; Alshammary, H.; Gonzalez-Reiche, A.S.; van de Guchte, A.; et al. Pre-infection antiviral innate immunity contributes to sex differences in SARS-CoV-2 infection. Cell Syst. 2022, 13, 924–931.e924. [Google Scholar] [CrossRef]
- Breiman, L. Better subset regression using the nonnegative garrote. Technometrics 1995, 37, 373–384. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. ; Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 2; Morgan Kaufmann Publishers Inc.: Montreal, QC, Canada, 1995; pp. 1137–1143. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. Smote: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ren, J.; Zhou, X.; Guo, W.; Feng, K.; Huang, T.; VCai, Y.-D. Identification of methylation signatures and rules for sarcoma subtypes by machine learning methods. BioMed Res. Int. 2022, 2022, 5297235. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.; Ma, Q.; Ren, J.; Li, J.; Wang, F.; Huang, T.; Cai, Y.-D. Identification of smoking associated transcriptome aberration in blood with machine learning methods. BioMed Res. Int. 2023, 2023, 5333361. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Ding, S.; Wang, D.; Chen, L.; Feng, K.; Huang, T.; Li, Z.; Cai, Y.-D. Identification of cell markers and their expression patterns in skin based on single-cell rna-sequencing profiles. Life 2022, 12, 550. [Google Scholar] [CrossRef]
- Huang, F.; Fu, M.; Li, J.; Chen, L.; Feng, K.; Huang, T.; Cai, Y.-D. Analysis and prediction of protein stability based on interaction network, gene ontology, and kegg pathway enrichment scores. BBA—Proteins Proteom. 2023, 1871, 140889. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Chen, L. Pmptce-hnea: Predicting metabolic pathway types of chemicals and enzymes with a heterogeneous network embedding algorithm. Curr. Bioinform. 2023. [Google Scholar] [CrossRef]
- Wu, C.; Chen, L. A model with deep analysis on a large drug network for drug classification. Math. Biosci. Eng. 2023, 20, 383–401. [Google Scholar] [CrossRef] [PubMed]
- Ran, B.; Chen, L.; Li, M.; Han, Y.; Dai, Q. Drug-drug interactions prediction using fingerprint only. Comput. Math. Methods Med. 2022, 2022, 7818480. [Google Scholar] [CrossRef]
- Powers, D. Evaluation: From precision, recall and f-measure to roc., informedness, markedness & correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Tang, S.; Chen, L. Iatc-nfmlp: Identifying classes of anatomical therapeutic chemicals based on drug networks, fingerprints and multilayer perceptron. Curr. Bioinform. 2022, 17, 814–824. [Google Scholar]
- Matthews, B. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochim. Et Biophys. Acta (BBA)-Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Cunningham, F.; Achuthan, P.; Akanni, W.; Allen, J.; Amode, M.R.; Armean, I.M.; Bennett, R.; Bhai, J.; Billis, K.; Boddu, S. Ensembl 2019. Nucleic Acids Res. 2019, 47, D745–D751. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, D.; Li, Y.; Shen, B. A novel erythroid differentiation related gene edrf1 upregulating globin gene expression in hel cells. Chin. Med. J. 2002, 115, 1701–1705. [Google Scholar] [PubMed]
- Wang, D.; Li, Y.; Shen, B. Initial function analysis of a novel erythroid differentiation related geneedrf1. Sci. China Ser. C Life Sci. 2001, 44, 489–496. [Google Scholar] [CrossRef] [PubMed]
- Stateman, W.A.; Henkin, R.I.; Knöppel, A.B.; Flegel, W.A. Erythrocyte membrane antigen frequencies in patients with type ii congenital smell loss. Am. J. Otolaryngol. 2015, 36, 146–152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zazhytska, M.; Kodra, A.; Hoagland, D.A.; Frere, J.; Fullard, J.F.; Shayya, H.; McArthur, N.G.; Moeller, R.; Uhl, S.; Omer, A.D.; et al. ; Non-cell-autonomous disruption of nuclear architecture as a potential cause of COVID-19-induced anosmia. Cell 2022, 185, 1052–1064.e1012. [Google Scholar] [CrossRef]
- Brann, D.H.; Tsukahara, T.; Weinreb, C.; Lipovsek, M.; Van den Berge, K.; Gong, B.; Chance, R.; Macaulay, I.C.; Chou, H.-J.; Fletcher, R.B.; et al. Non-neuronal expression of SARS-CoV-2 entry genes in the olfactory system suggests mechanisms underlying COVID-19-associated anosmia. Sci. Adv. 2020, 6, eabc5801. [Google Scholar] [CrossRef]
- Duncheng, W.; Shuhua, M.; Shengqi, W.; Beifen, S. Antisense edrf1 gene inhibited gata-1 transcription factor DNA-binding activity in k562 cells. Sci. China Ser. C Life Sci. 2002, 45, 289–297. [Google Scholar]
- Ho, M.; Thompson, B.; Fisk, J.N.; Nebert, D.W.; Bruford, E.A.; Vasiliou, V.; Bunick, C.G. Update of the keratin gene family: Evolution, tissue-specific expression patterns, and relevance to clinical disorders. Hum. Genom. 2022, 16, 1. [Google Scholar] [CrossRef]
- Ting, C.; Aspal, M.; Vaishampayan, N.; Huang, S.; Wang, F.; Farver, C.; Zemans, R. Ineffectual alveolar regeneration in COVID-19 ards: Persistence of keratin-8 positive transitional cells. In Tp105. Tp105 Basic Mechanisms of Lung Infections: From SARS-CoV-2 to Influenza; American Thoracic Society: New York, NY, USA, 2021; p. A4163. [Google Scholar]
- Hawkes, C.H. Smell, taste and COVID-19: Testing is essential. QJM Int. J. Med. 2021, 114, 83–91. [Google Scholar] [CrossRef]
- Bhatta, S.; Sharma, D.; Sharma, S.; Maharjan, L.; Bhattachan, S.; Shah, M.K.; Singhal, A.; Ghanpur, A.D.; Ganesuni, D.; Saindani, S.J. Smell and taste disturbance in COVID-19 patients: A prospective multicenteric review. Indian J. Otolaryngol. Head Neck Surg. 2021, 74, 2978–2984. [Google Scholar] [CrossRef]
- Shirvaliloo, M. Epigenomics in COVID-19; the link between DNA methylation, histone modifications and SARS-CoV-2 infection. Epigenomics 2021, 13, 745–750. [Google Scholar] [CrossRef] [PubMed]
- Kronsbein, H.C.; Jastorff, A.M.; Maccarrone, G.; Stalla, G.; Wurst, W.; Holsboer, F.; Turck, C.W.; Deussing, J.M. Crhr1-dependent effects on protein expression and posttranslational modification in att-20 cells. Mol. Cell. Endocrinol. 2008, 292, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Özkan, H.; Öztürk, D.G.; Korkmaz, G. Transcriptional factor repertoire of breast cancer in 3d cell culture models. Cancers 2022, 14, 1023. [Google Scholar] [CrossRef] [PubMed]
- Schonfeld, E. Single Cell Genetic Analysis of COVID-19: A Deep Learning Approach. 2022. Available online: https://www.researchsquare.com/article/rs-1754568/latest.pdf (accessed on 4 October 2022).
- Jha Bhaskar, A.; Fadda, A.; Merce, C.; Mugo, E.; Droll, D.; Clayton, C. Depletion of the trypanosome pumilio domain protein puf2 or of some other essential proteins causes transcriptome changes related to coding region length. Eukaryot. Cell 2014, 13, 664–674. [Google Scholar]
- de Groot, N.; Groen, R.; Orie, V.; Bruijnesteijn, J.; de Groot, N.G.; Doxiadis, G.G.; Bontrop, R.E. Analysis of macaque btn3a genes and transcripts in the extended mhc: Conserved orthologs of human γδ t cell modulators. Immunogenetics 2019, 71, 545–559. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rank, A.; Tzortzini, A.; Kling, E.; Schmid, C.; Claus, R.; Löll, E.; Burger, R.; Römmele, C.; Dhillon, C.; Müller, K. One year after mild COVID-19: The majority of patients maintain specific immunity, but one in four still suffer from long-term symptoms. J. Clin. Med. 2021, 10, 3305. [Google Scholar] [CrossRef]
- Macías, Á.M. The intestinal perspective of COVID-19: Nos2 and aoc1 genes as epidemiological factors, and a homeopathic approach to their functional improvement. Homœopathic Links 2020, 33, 196–221. [Google Scholar] [CrossRef]
- González-Martínez, D.; Kim, S.-H.; Hu, Y.; Guimond, S.; Schofield, J.; Winyard, P.; Vannelli, G.B.; Turnbull, J.; Bouloux, P.-M. Anosmin-1 modulates fibroblast growth factor receptor 1 signaling in human gonadotropin-releasing hormone olfactory neuroblasts through a heparan sulfate-dependent mechanism. J. Neurosci. 2004, 24, 10384–10392. [Google Scholar] [CrossRef] [Green Version]
- Cohn, Z.J.; Kim, A.; Huang, L.; Brand, J.; Wang, H. Lipopolysaccharide-induced inflammation attenuates taste progenitor cell proliferation and shortens the life span of taste bud cells. BMC Neurosci. 2010, 11, 72. [Google Scholar] [CrossRef] [Green Version]
- Starling, G.P.; Philips, B.A.; Ganesh, S.; King, J.S. Katnip is required to maintain microtubule function and lysosomal delivery to autophagosomes and phagosomes. Mol. Biol. Cell. 2023, 34, ar12. [Google Scholar] [CrossRef]
- Gahl, W.A.; Reed, G.F.; Thoene, J.G.; Schulman, J.D.; Rizzo, W.B.; Jonas, A.J.; Denman, D.W.; Schlesselman, J.J.; Corden, B.J.; Schneider, J.A. Cysteamine therapy for children with nephropathic cystinosis. N. Engl. J. Med. 1987, 316, 971–977. [Google Scholar] [CrossRef] [PubMed]
- Khani, E.; Khiali, S.; Beheshtirouy, S.; Entezari-Maleki, T. Potential pharmacologic treatments for COVID-19 smell and taste loss: A comprehensive review. Eur. J. Pharmacol. 2021, 912, 174582. [Google Scholar] [CrossRef] [PubMed]
- de Melo, G.D.; Lazarini, F.; Levallois, S.; Hautefort, C.; Michel, V.; Larrous, F.; Verillaud, B.; Aparicio, C.; Wagner, S.; Gheusi, G. COVID-19–related anosmia is associated with viral persistence and inflammation in human olfactory epithelium and brain infection in hamsters. Sci. Transl. Med. 2021, 13, eabf8396. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Chen, G. The roles of vitamin a in the regulation of carbohydrate, lipid, and protein metabolism. J. Clin. Med. 2014, 3, 453–479. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diego, V.P.; Rainwater, D.L.; Wang, X.-L.; Cole, S.A.; Curran, J.E.; Johnson, M.P.; Jowett, J.B.; Dyer, T.D.; Williams, J.T.; Moses, E.K. Genotype× adiposity interaction linkage analyses reveal a locus on chromosome 1 for lipoprotein-associated phospholipase a2, a marker of inflammation and oxidative stress. Am. J. Hum. Genet. 2007, 80, 168–177. [Google Scholar] [CrossRef] [Green Version]
- Malishkevich, A.; Leyk, J.; Goldbaum, O.; Richter-Landsberg, C.; Gozes, I. Adnp/adnp2 expression in oligodendrocytes: Implication for myelin-related neurodevelopment. J. Mol. Neurosci. 2015, 57, 304–313. [Google Scholar] [CrossRef]
- Wang, Y.T.; Lim, Y.; McCall, M.N.; Huang, K.-T.; Haynes, C.M.; Nehrke, K.; Brookes, P.S. Cardioprotection by the mitochondrial unfolded protein response requires atf5. Am. J. Physiol.-Heart Circ. Physiol. 2019, 317, H472–H478. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | LASSO Feature List | LightGBM Feature List | MCFS Feature List |
|---|---|---|---|
| 1 | ENSG00000254624.1 (OR4R3P) | ENSG00000225611.1 (CCDC13-AS2) | ENSG00000171360.3 (KRT38) |
| 2 | ENSG00000223379.1 (Lnc-SPATA31A7-1) | ENSG00000259515.1 (Antisense to CDC42BPB) | ENSG00000149798.5 (CDC42EP2) |
| 3 | ENSG00000168528.12 (SERINC2) | ENSG00000104973.18 (MED25) | ENSG00000124549.14 (BTN2A3P) |
| 4 | ENSG00000278931.1 (ANKRD20A3 Pseudogene) | ENSG00000010361.13 (FUZ) | ENSG00000230526.1 (Lnc-CDH23-3) |
| 5 | ENSG00000203581.7 (OR1F2P) | ENSG00000163032.11 (VSNL1) | ENSG00000225611.1 (CCDC13-AS2) |
| 6 | ENSG00000234134.1 (EDRF1-AS1) | ENSG00000236496.2 (GPS2P1) | ENSG00000010361.13 (FUZ) |
| 7 | ENSG00000229596.3 (MYL12BP3) | ENSG00000149798.5 (CDC42EP2) | ENSG00000092054.13 (MYH7) |
| 8 | ENSG00000261707.1 (Lnc-ADAMTS18-3) | ENSG00000101544.9 (ADNP2) | ENSG00000131370.16 (SH3BP5) |
| 9 | ENSG00000229190.1 (Lnc-HACD1-2) | ENSG00000259674.1 (RPL7AP75) | ENSG00000158710.14 (TAGLN2) |
| 10 | ENSG00000183562.3 (Lnc-SLC22A18-2) | ENSG00000165406.16 (MARCHF8) | ENSG00000264204.2 (AGAP7P) |
| Feature Lists | Number of Features | F1 Measure | MCC a | ACC b |
|---|---|---|---|---|
| LASSO feature list | 90 | 0.864 | 0.841 | 0.960 |
| 3510 | 0.916 | 0.902 | 0.976 | |
| LightGBM feature list | 55 | 0.927 | 0.915 | 0.979 |
| 340 | 0.964 | 0.958 | 0.990 | |
| MCFS feature list | 80 | 0.850 | 0.825 | 0.957 |
| 300 | 0.908 | 0.893 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, J.; Zhang, Y.; Guo, W.; Feng, K.; Yuan, Y.; Huang, T.; Cai, Y.-D. Identification of Genes Associated with the Impairment of Olfactory and Gustatory Functions in COVID-19 via Machine-Learning Methods. Life 2023, 13, 798. https://doi.org/10.3390/life13030798
Ren J, Zhang Y, Guo W, Feng K, Yuan Y, Huang T, Cai Y-D. Identification of Genes Associated with the Impairment of Olfactory and Gustatory Functions in COVID-19 via Machine-Learning Methods. Life. 2023; 13(3):798. https://doi.org/10.3390/life13030798
Chicago/Turabian StyleRen, Jingxin, Yuhang Zhang, Wei Guo, Kaiyan Feng, Ye Yuan, Tao Huang, and Yu-Dong Cai. 2023. "Identification of Genes Associated with the Impairment of Olfactory and Gustatory Functions in COVID-19 via Machine-Learning Methods" Life 13, no. 3: 798. https://doi.org/10.3390/life13030798