

Assessing the Nationwide COVID-19 Risk in Mexico through the Lens of Comorbidity by an XGBoost-Based Logistic Regression Model
Abstract
:1. Introduction
2. Materials and Methods
2.1. Available Data
2.2. Logistic Regression
2.3. XGBoost
3. Results
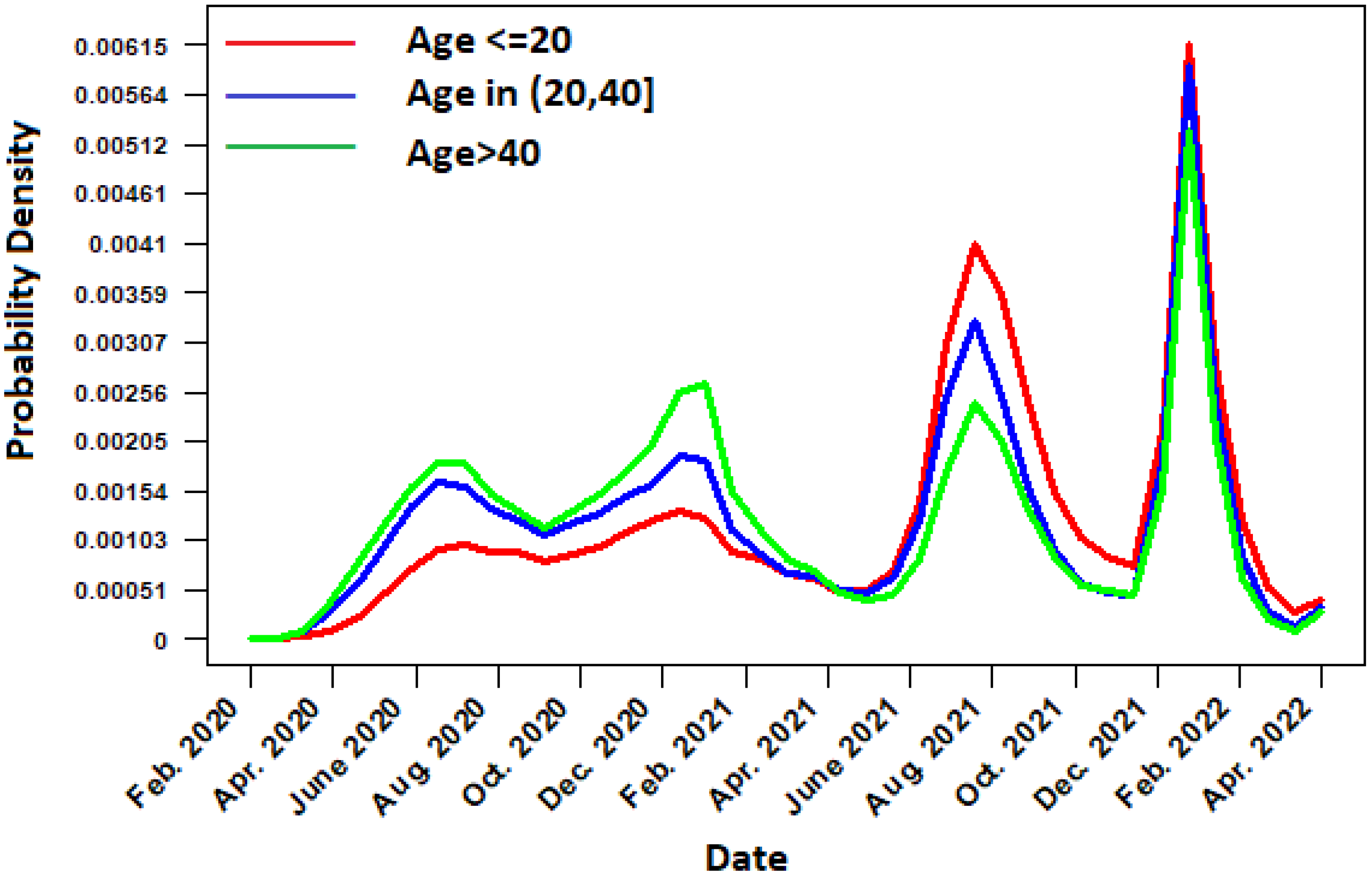
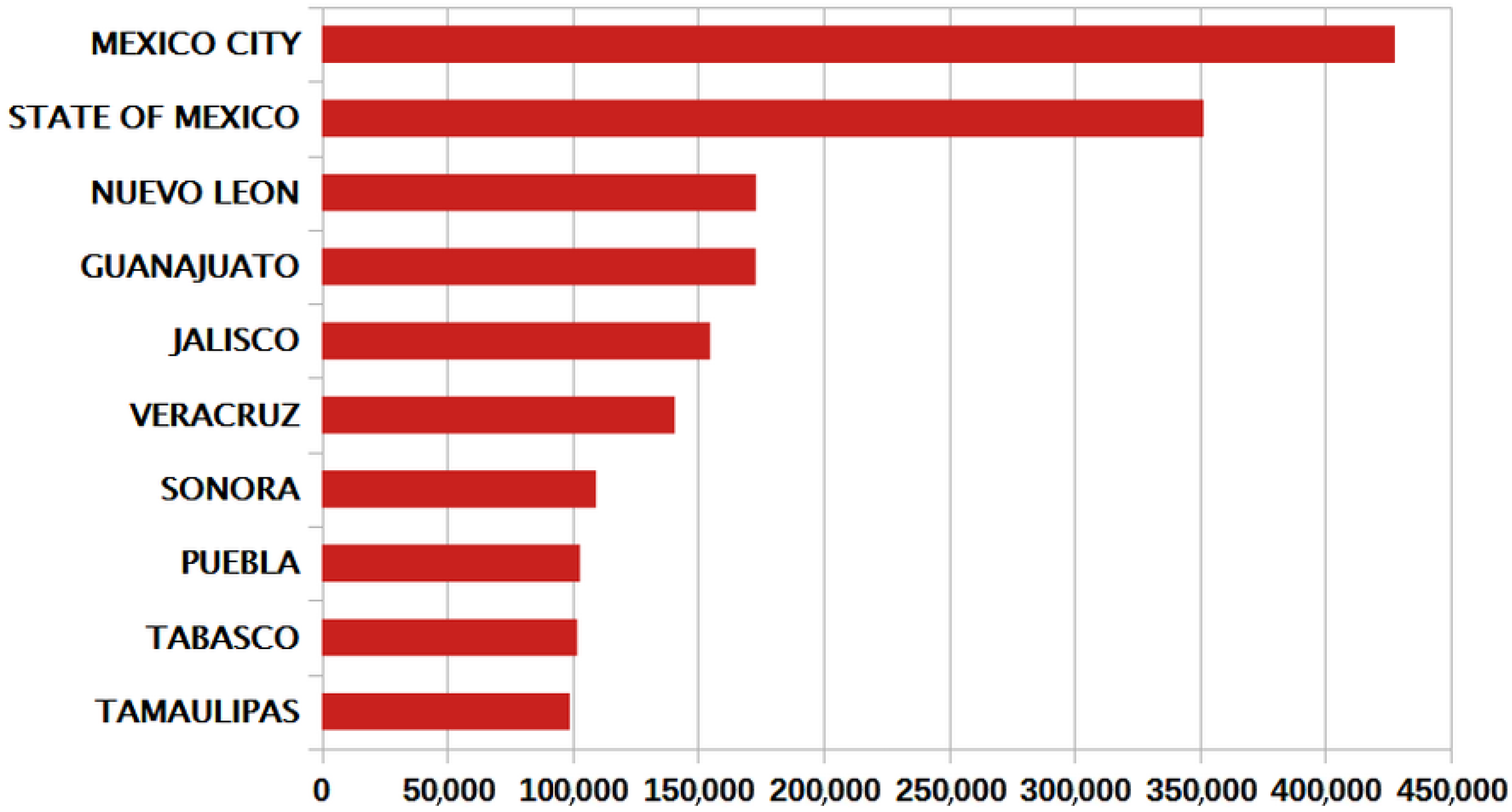
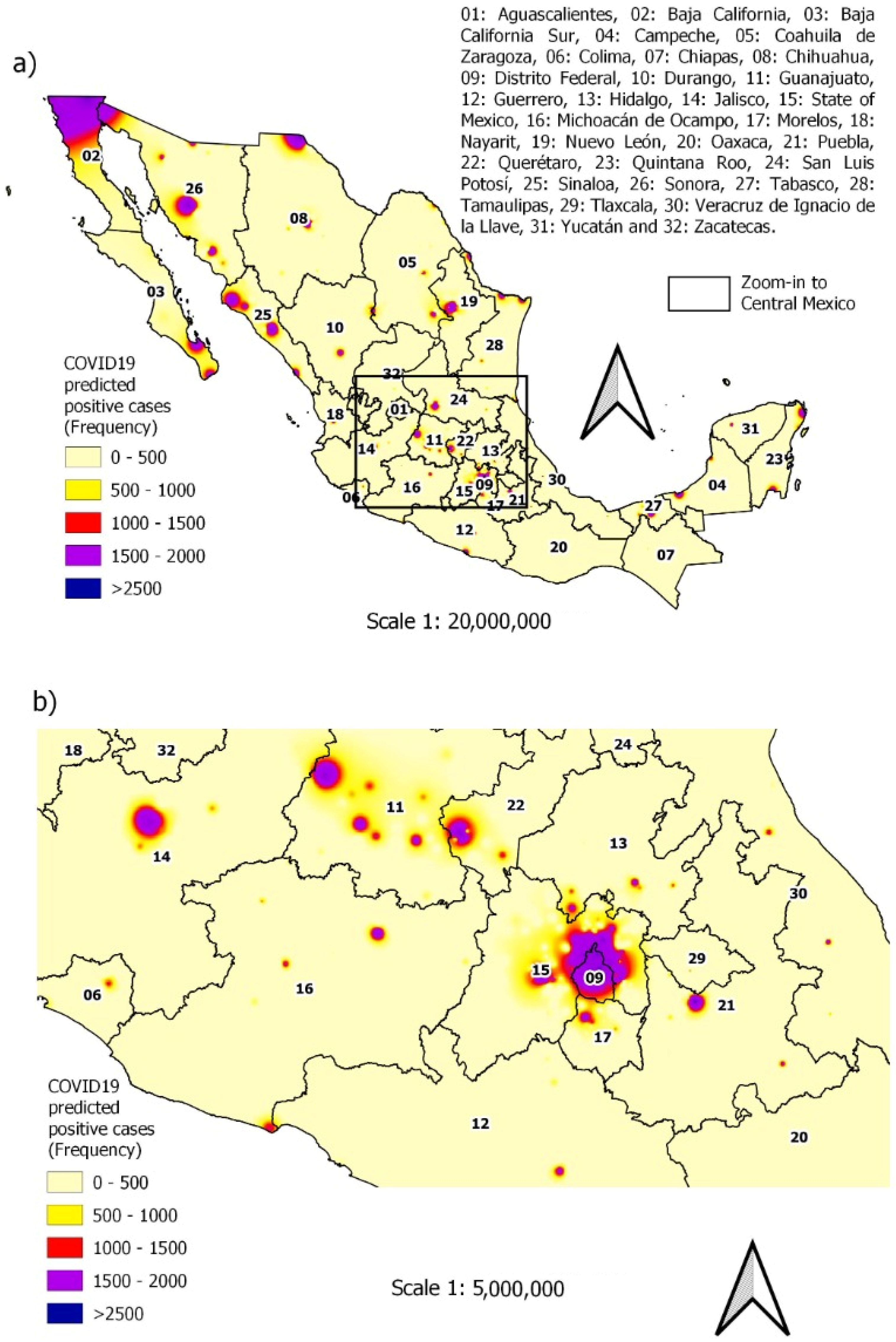
3.1. Spatiotemporal Distribution of Daily Cases
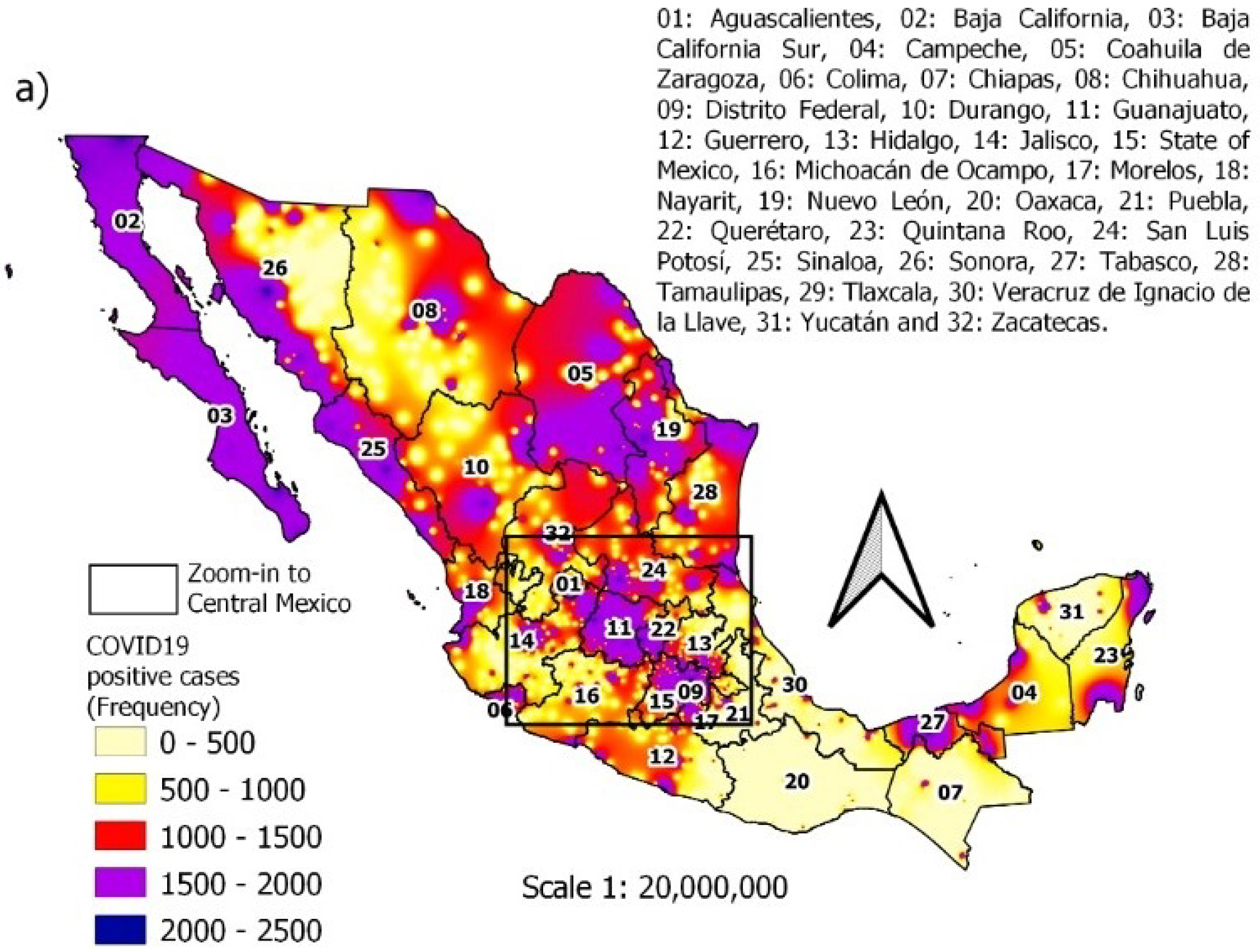
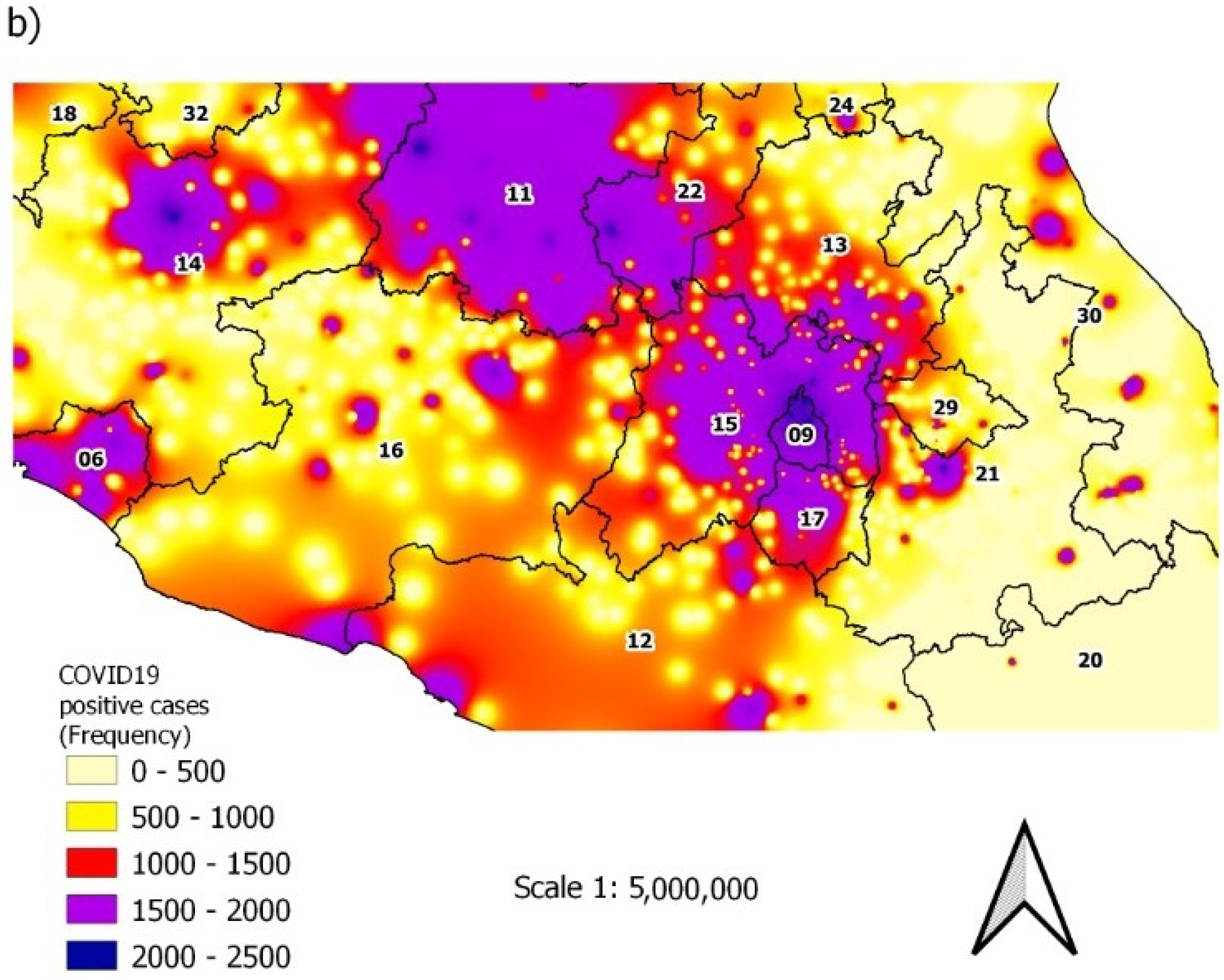
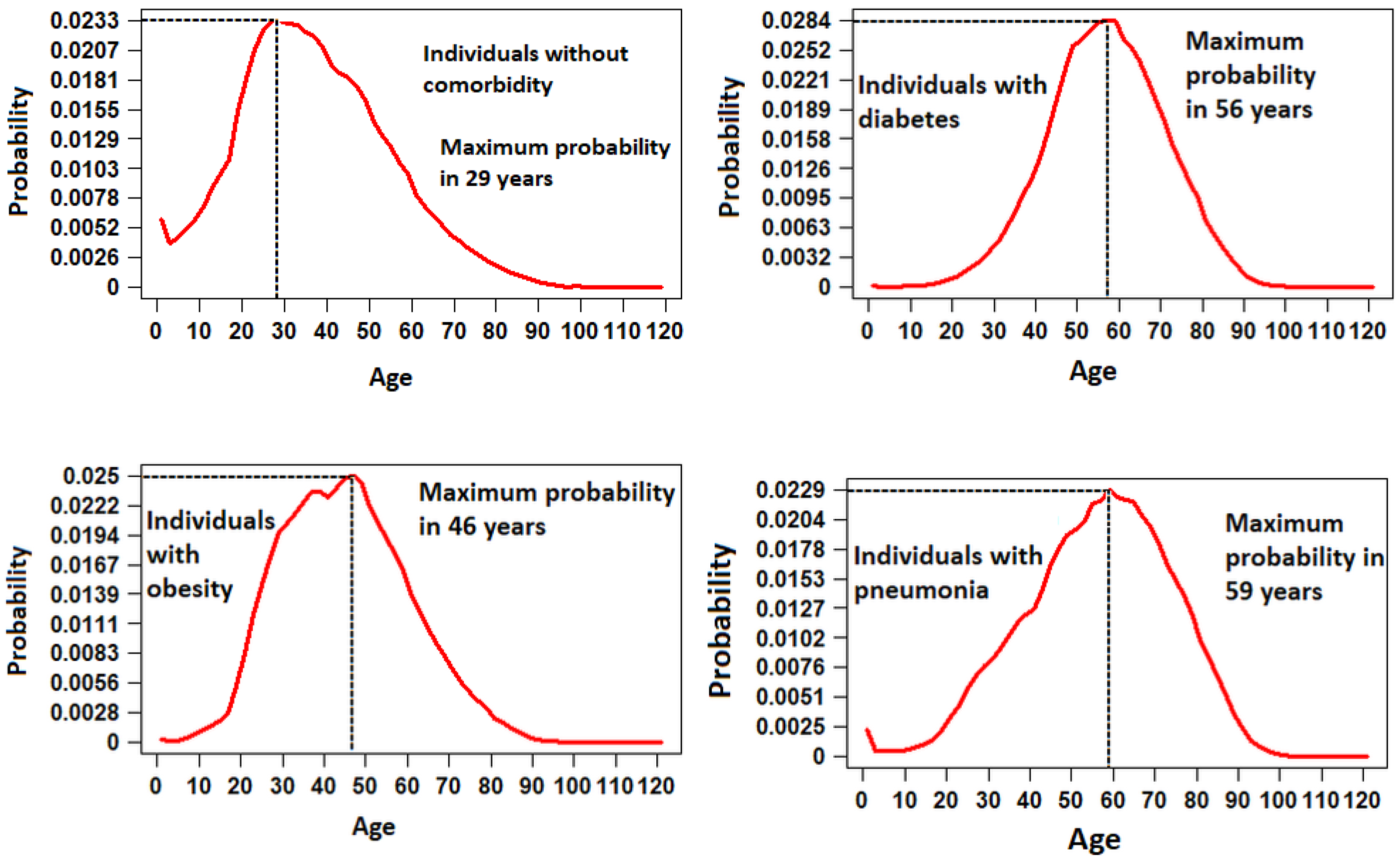
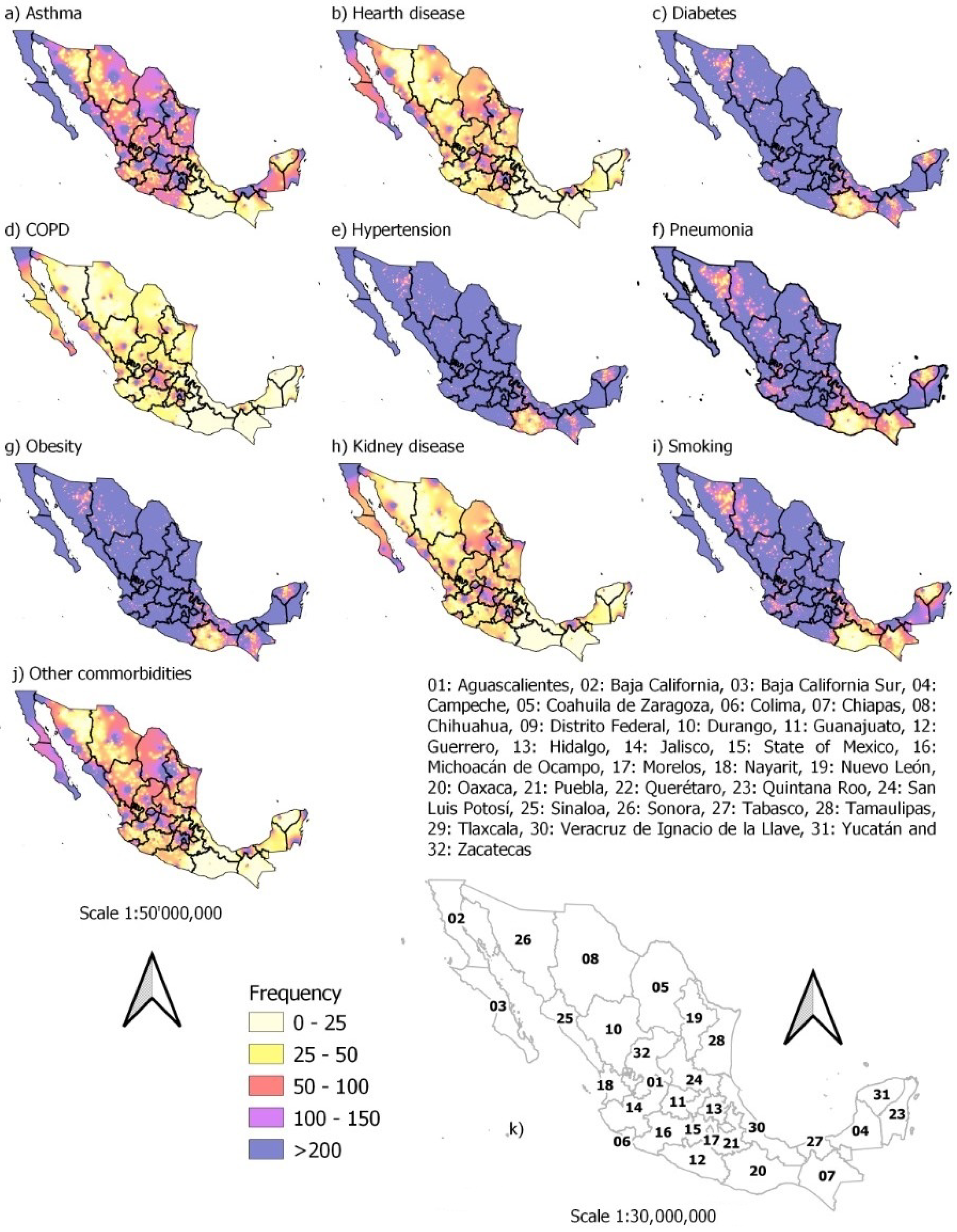
3.2. Spatiotemporal Distribution of Individuals with Comorbidities
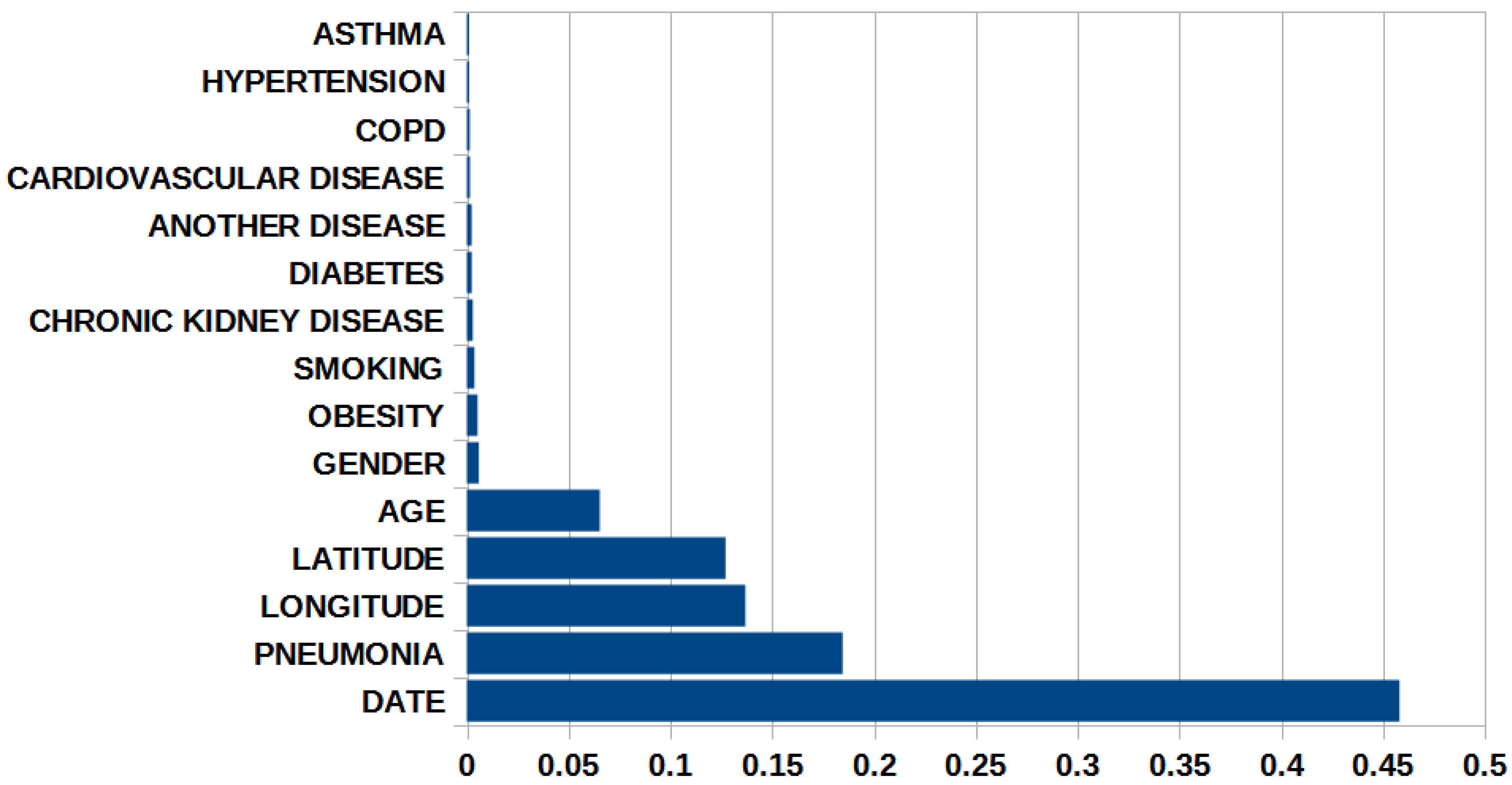
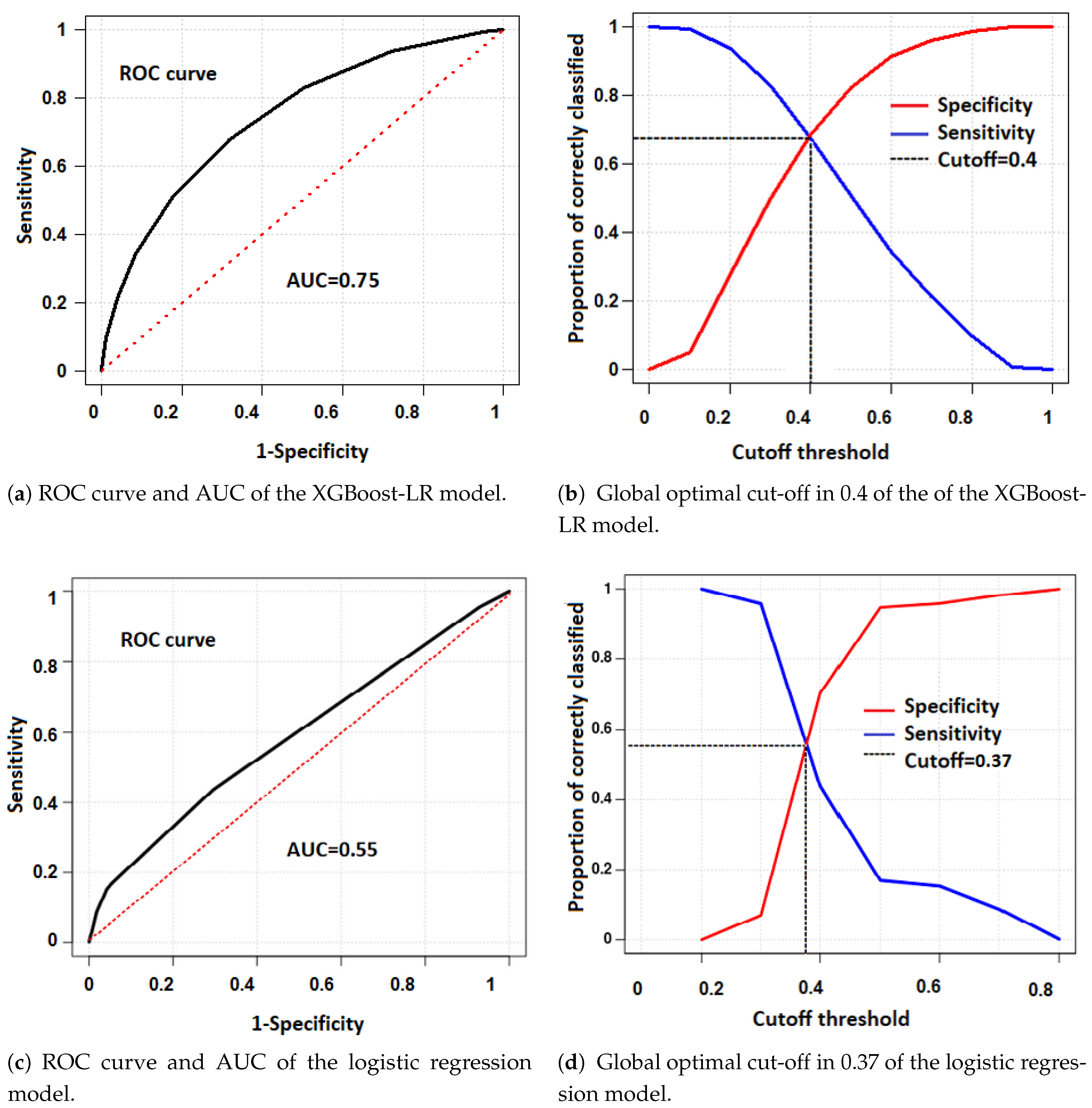
3.3. Classification Analysis with XGBoost-LR and Classic LR
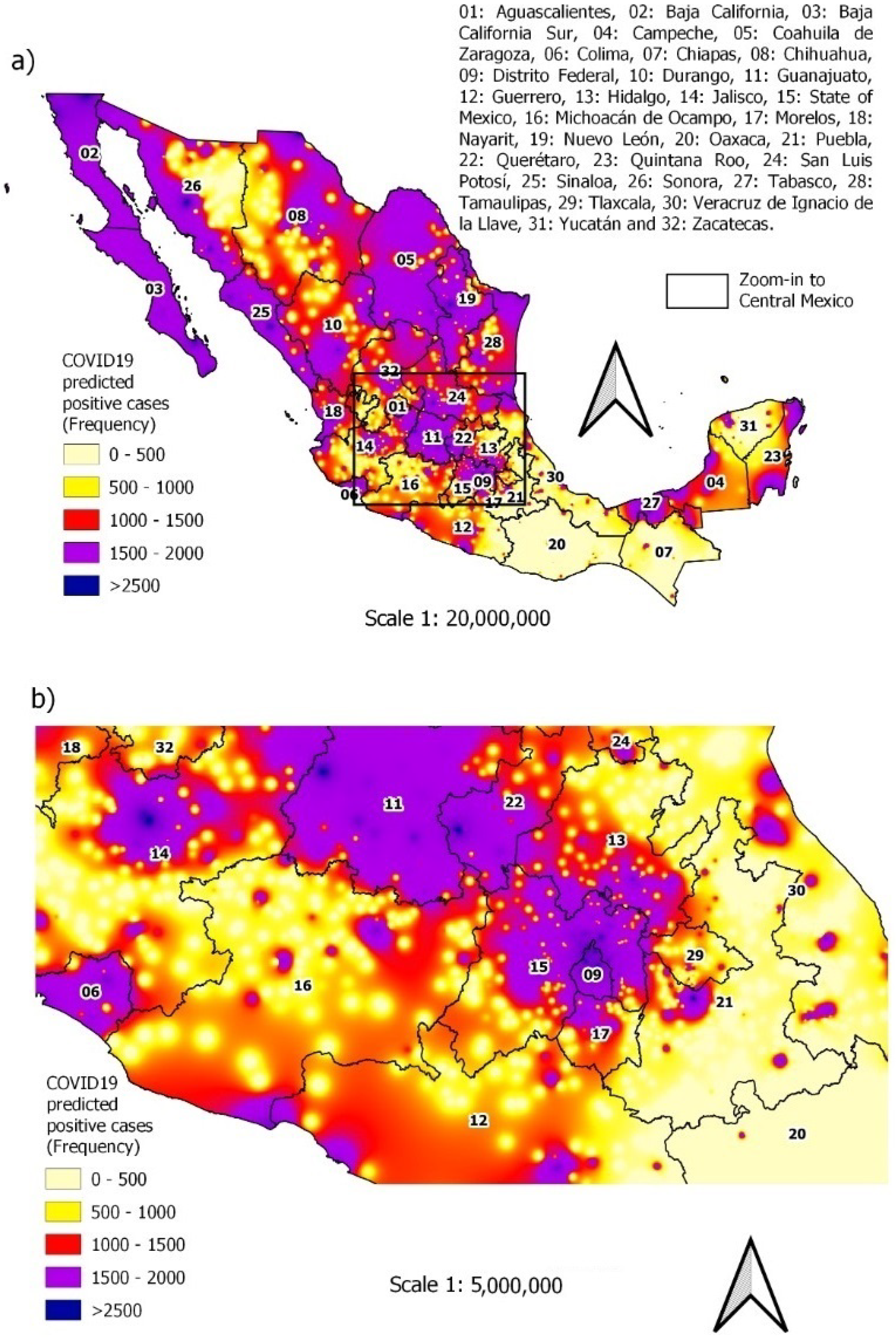
3.4. Predicting New Cases
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| COVID-19 | `CO’ stands for corona, ‘VI’ for virus, ‘D’ for disease, and ‘19’ for 2019 |
| CONABIO | National Commission for the Knowledge and Use of Biodiversity |
| COPD | Chronic obstructive pulmonary disease |
| DGE | Directorate General for Epidemiology |
| ROC | Receiver Operating Characteristic |
| SARS-CoV-2 | Severe acute respiratory syndrome coronavirus 2 |
| WHO | World Health Organization |
References
- Johns Hopkins University; Center for Systems Science and Engineering (CSSE). COVID-19 Dashboard. Available online: https://coronavirus.jhu.edu/map.html (accessed on 10 March 2021).
- Suárez, V.; Quezada, M.S.; Ruiz, S.O.; De Jesús, E.R. Epidemiología de COVID-19 en México: Del 27 de febrero al 30 de abril de 2020. Rev. Clínica Española 2020, 220, 463–471. [Google Scholar] [CrossRef] [PubMed]
- Ena, J.; Wenzel, R. Un nuevo coronavirus emerge. Rev. Clínica Española 2020, 220, 115–116. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Modes of Transmission of Virus Causing COVID-19: Implications for Ipc Precaution Recommendations. Available online:https://www.who.int/news-room/commentaries/detail/modes-of-transmission-of-virus-causing-COVID-19-implications-for-ipc-precaution-recommendations (accessed on 1 December 2021).
- González-Villoria, A.M.; Zuñiga, R.A.A. Social vulnerability and its possible relation to the principal causes of morbidity and mortality in the Mexican state of Oaxaca. Int. J. Equity Health 2018, 17. [Google Scholar] [CrossRef] [PubMed]
- Sosa-Rubí, S.G.; Seiglie, J.A.; Chivardi, C.; Manne-Goehler, J.; Meigs, J.B.; Wexler, D.J.; Wirtz, V.J.; Gómez-Dantés, O.; Serván-Mori, E. Incremental Risk of Developing Severe COVID-19 Among Mexican Patients with Diabetes Attributed to Social and Health Care Access Disadvantages. Diabetes Care 2020, 44, 373–380. [Google Scholar] [CrossRef] [PubMed]
- Gold, M.S.; Sehayek, D.; Gabrielli, S.; Zhang, X.; McCusker, C.; Ben-Shoshan, M. COVID-19 and comorbidities: A systematic review and meta-analysis. Postgrad. Med. 2020, 132, 749–755. [Google Scholar] [CrossRef] [PubMed]
- Qiu, P.; Zhou, Y.; Wang, F.; Wang, H.; Zhang, M.; Pan, X.; Zhao, Q.; Liu, J. Clinical characteristics, laboratory outcome characteristics, comorbidities, and complications of related COVID-19 deceased: A systematic review and meta-analysis. Aging Clin. Exp. Res. 2020, 32, 1869–1878. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Garduño, E. Obesity is the comorbidity more strongly associated for Covid-19 in Mexico. A case-control study. Obes. Res. Clin. Pract. 2020, 14, 375–379. [Google Scholar] [CrossRef] [PubMed]
- Seiglie, J.; Platt, J.; Cromer, S.J.; Bunda, B.; Foulkes, A.S.; Bassett, I.V.; Hsu, J.; Meigs, J.B.; Leong, A.; Putman, M.S.; et al. Diabetes as a Risk Factor for Poor Early Outcomes in Patients Hospitalized With COVID-19. Diabetes Care 2020, 43, 2938–2944. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Mi, S.; Luo, S.; Wang, Y.; Ren, B.; Cai, L.; Wu, M. Risk Factors for Mortality in 220 Patients with COVID-19 in Wuhan, China: A Single-Center, Retrospective Study. Ear Nose Throat J. 2020, 100, 140S–147S. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Althunayyan, S.; Alsofayan, Y.; Alotaibi, R.; Mubarak, A.; Arafat, M.; Assiri, A.; Jokhdar, H. Risk factors associated with worse outcomes in COVID-19: A retrospective study in Saudi Arabia. East. Mediterr. Health J. 2020, 26, 1371–1380. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Y.; Ma, Y.; Ruan, L.; Li, D.; Lu, C.; Huang, L. Comparing different machine learning techniques for predicting COVID-19 severity. Infect. Dis. Poverty 2022, 11, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Parra-Bracamonte, G.M.; Lopez-Villalobos, N.; Parra-Bracamonte, F.E. Clinical characteristics and risk factors for mortality of patients with COVID-19 in a large data set from Mexico. Ann. Epidemiol. 2020, 52, 93–98.e2. [Google Scholar] [CrossRef] [PubMed]
- Carrillo-Vega, M.F.; Salinas-Escudero, G.; García-Peña, C.; Gutiérrez-Robledo, L.M.; Parra-Rodríguez, L. Early estimation of the risk factors for hospitalization and mortality by COVID-19 in Mexico. PLoS ONE 2020, 15, e0238905. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3149–3157. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ma, J.; Yu, Z.; Qu, Y.; Xu, J.; Cao, Y. Application of the XGBoost Machine Learning Method in PM2.5 Prediction: A Case Study of Shanghai. Aerosol Air Qual. Res. 2020, 20, 128–138. [Google Scholar] [CrossRef]
- Lu, Y.; Fu, X.; Guo, E.; Tang, F. XGBoost Algorithm-Based Monitoring Model for Urban Driving Stress: Combining Driving Behaviour, Driving Environment, and Route Familiarity. IEEE Access 2021, 9, 21921–21938. [Google Scholar] [CrossRef]
- Instituto Nacional de Estadística, Geografía e Informática. Población. 2020. Available online: http://cuentame.inegi.org.mx/poblacion/habitantes.aspx?tema=p (accessed on 20 March 2021).
- Dobson, A.J.; Barnett, A.G. An Introduction to Generalized Linear Models, 4th ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar] [CrossRef]
- Treviño, J.A. Demografía, comorbilidad y condiciones médicas de los pacientes hospitalizados por COVID-19 en México. Middle Atl. Rev. Lat. Am. Stud. 2020, 4, 49. [Google Scholar] [CrossRef]
- Salinas-Aguirre, J.; Sánchez-García, C.; Rodríguez-Sanchez, R.; Rodríguez-Muñoz, L.; Díaz-Castaño, A.; Bernal-Gómez, R. Características clínicas y comorbilidades asociadas a mortalidad en pacientes con COVID-19 en Coahuila (México). Rev. Clínica Española 2022, 222, 288–292. [Google Scholar] [CrossRef] [PubMed]
- Juárez, M.V.S. COVID-19 en México: Análisis de su comportamiento espacio—Temporal a partir de los Condicionantes Socio espaciales de la Salud. Pers. Soc. 2021, 35, 15. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Units | Input Data Source 1,2 | |
|---|---|---|---|---|
| 1 | Date | − | Days | DGE |
| 2 | Gender | 0: Male, 1: Female | − | DGE |
| 3 | Age | − | Years | GDE |
| 4 | Asthma | 0: No, 1: Yes | − | DGE |
| 5 | Diabetes | 0: No, 1: Yes | − | DGE |
| 6 | Cardiovascular disease | 0: No, 1: Yes | − | DGE |
| 7 | COPD | 0: No, 1: Yes | − | DGE |
| 8 | Hypertension | 0: No, 1: Yes | − | DGE |
| 9 | Obesity | 0: No, 1: Yes | − | DGE |
| 10 | Chronic kidney disease | 0: No, 1: Yes | − | DGE |
| 11 | Smoking | 0: No, 1: Yes | − | DGE |
| 12 | Pneumonia | 0: No, 1: Yes | − | DGE |
| 13 | Other disease | 0: No, 1: Yes | − | DGE |
| 14 | Longitude | X UTM coordinate | m | CONABIO |
| 15 | Latitude | Y UTM coordinate | m | CONABIO |
| Variable | Yes | No |
|---|---|---|
| Hypertension | 19.00% | 81.00% |
| Pneumonia | 9.00% | 91.00% |
| Obesity | 15.50% | 84.50% |
| Diabetes | 14.17% | 85.83% |
| Smoking | 10.02% | 89.98% |
| Asthma | 3.77% | 96.23% |
| Chronic kidney failure | 1.88% | 98.12% |
| Cardiovascular disease | 1.94% | 98.06% |
| Other disease | 2.6% | 97.40% |
| COPD | 1.32% | 98.68% |
| Variable | Yes | No |
|---|---|---|
| Hypertension | 21.62% | 78.38% |
| Pneumonia | 15.62% | 84.38% |
| Obesity | 17.67% | 82.33% |
| Diabetes | 16.53% | 83.47% |
| Smoking | 8.98% | 91.02% |
| Asthma | 3.37% | 96.63% |
| Chronic kidney failure | 1.93% | 98.07% |
| Cardiovascular disease | 1.95% | 98.05% |
| Other disease | 2.78% | 97.22% |
| COPD | 1.37% | 98.63% |
| Model | Sensitivity | Specificity | Accuracy |
|---|---|---|---|
| XGBoost | 66.11% | 70.11% | 68.50% |
| Multivariate logistic regression | 43.63% | 70.49% | 59.69% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Venancio-Guzmán, S.; Aguirre-Salado, A.I.; Soubervielle-Montalvo, C.; Jiménez-Hernández, J.d.C. Assessing the Nationwide COVID-19 Risk in Mexico through the Lens of Comorbidity by an XGBoost-Based Logistic Regression Model. Int. J. Environ. Res. Public Health 2022, 19, 11992. https://doi.org/10.3390/ijerph191911992
Venancio-Guzmán S, Aguirre-Salado AI, Soubervielle-Montalvo C, Jiménez-Hernández JdC. Assessing the Nationwide COVID-19 Risk in Mexico through the Lens of Comorbidity by an XGBoost-Based Logistic Regression Model. International Journal of Environmental Research and Public Health. 2022; 19(19):11992. https://doi.org/10.3390/ijerph191911992
Chicago/Turabian StyleVenancio-Guzmán, Sonia, Alejandro Ivan Aguirre-Salado, Carlos Soubervielle-Montalvo, and José del Carmen Jiménez-Hernández. 2022. "Assessing the Nationwide COVID-19 Risk in Mexico through the Lens of Comorbidity by an XGBoost-Based Logistic Regression Model" International Journal of Environmental Research and Public Health 19, no. 19: 11992. https://doi.org/10.3390/ijerph191911992