
Using Social Networks to Estimate the Number of COVID-19 Cases: The Incident (Hidden COVID-19 Cases Network Estimation) Study Protocol

 , , ,
, , ,  , , ,
, , ,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.1.1. Procedures
2.1.2. Ethics
2.2. The Network Scale-Up Method in the Literature
2.2.1. NSUM Questionnaire
2.2.2. NSUM Assumption
2.2.3. NSUM Estimator
- (1)
- Estimate the average size of the personal network, , by asking how many people the respondent personally knows about the k known populations (e.g., the number of people who were married in 2019). This number will then be divided by the number of people who got married in 2019 in Italy (), where is the total size of subpopulation k.
- (2)
- Define the number of hidden COVID-19 cases present in each social network, for example, by asking the respondent how many people he/she knows with COVID-19.
- (3)
- Calculate the COVID-19 population size obtained by multiplying the estimated proportions of the population in each subpopulation by the general Italian population. For example, if a respondent knows 10 subjects with COVID-19 cases and has a personal network of 100 people and the total population is 1,000,000, the estimated number of hidden COVID-19 cases will be approximately calculated as: 10/100 × 1,000,000.
2.3. Bayesian NSUM Estimation
2.3.1. Extended Random Degree Model
2.3.2. Performance of the Modified Maltiel Estimators
2.4. Statistical Analysis
3. Results of the Simulation Study
Performances of the Modified Maltiel’s Estimators
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO Statement Regarding Cluster of Pneumonia Cases in Wuhan, China. Available online: https://www.who.int/china/news/detail/09-01-2020-who-statement-regarding-cluster-of-pneumonia-cases-in-wuhan-china (accessed on 16 April 2020).
- Cascella, M.; Rajnik, M.; Cuomo, A.; Dulebohn, S.C.; Di Napoli, R. Features, Evaluation and Treatment Coronavirus (COVID-19). In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2020. [Google Scholar]
- Li, R.; Pei, S.; Chen, B.; Song, Y.; Zhang, T.; Yang, W.; Shaman, J. Substantial Undocumented Infection Facilitates the Rapid Dissemination of Novel Coronavirus (SARS-CoV2). Science 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palatella, L.; Vanni, F.; Lambert, D. A Phenomenological Estimate of the True Scale of CoViD-19 from Primary Data. Chaos Solitons Fractals 2021, 146, 110854. [Google Scholar] [CrossRef] [PubMed]
- Nishiura, H.; Kobayashi, T.; Yang, Y.; Hayashi, K.; Miyama, T.; Kinoshita, R.; Linton, N.M.; Jung, S.; Yuan, B.; Suzuki, A.; et al. The Rate of Underascertainment of Novel Coronavirus (2019-NCoV) Infection: Estimation Using Japanese Passengers Data on Evacuation Flights. J. Clin. Med. 2020, 9, 419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, L.; Ruan, F.; Huang, M.; Liang, L.; Huang, H.; Hong, Z.; Yu, J.; Kang, M.; Song, Y.; Xia, J.; et al. SARS-CoV-2 Viral Load in Upper Respiratory Specimens of Infected Patients. N. Engl. J. Med. 2020. [Google Scholar] [CrossRef] [PubMed]
- Nishiura, H.; Kobayashi, T.; Suzuki, A.; Jung, S.-M.; Hayashi, K.; Kinoshita, R.; Yang, Y.; Yuan, B.; Akhmetzhanov, A.R.; Linton, N.M.; et al. Estimation of the Asymptomatic Ratio of Novel Coronavirus Infections (COVID-19). Int. J. Infect. Dis. 2020. [Google Scholar] [CrossRef]
- Mizumoto, K.; Kagaya, K.; Zarebski, A.; Chowell, G. Estimating the Asymptomatic Proportion of Coronavirus Disease 2019 (COVID-19) Cases on Board the Diamond Princess Cruise Ship, Yokohama, Japan, 2020. Eurosurveillance 2020, 25, 2000180. [Google Scholar] [CrossRef] [Green Version]
- Lavezzo, E.; Franchin, E.; Ciavarella, C.; Cuomo-Dannenburg, G.; Barzon, L.; Del Vecchio, C.; Rossi, L.; Manganelli, R.; Loregian, A.; Navarin, N.; et al. Suppression of a SARS-CoV-2 Outbreak in the Italian Municipality of Vo’. Nature 2020. [Google Scholar] [CrossRef]
- Bai, Y.; Yao, L.; Wei, T.; Tian, F.; Jin, D.-Y.; Chen, L.; Wang, M. Presumed Asymptomatic Carrier Transmission of COVID-19. JAMA 2020, 323, 1406–1407. [Google Scholar] [CrossRef] [Green Version]
- Wei, W.E. Presymptomatic Transmission of SARS-CoV-2—Singapore, January 23 March 16, 2020. MMWR Morb. Mortal. Wkly. Rep. 2020, 69. [Google Scholar] [CrossRef] [Green Version]
- Laboratory Testing for 2019 Novel Coronavirus (2019-NCoV) in Suspected Human Cases. Available online: https://www.who.int/publications-detail-redirect/10665-331501 (accessed on 2 July 2020).
- Evans, A.S. Viral Infections of Humans: Epidemiology and Control; Springer Science & Business Media: Berlin, Germany, 2013; ISBN 978-1-4684-4727-9. [Google Scholar]
- International Working Group for Disease Monitoring and Forecasting. Capture-Recapture and Multiple-Record Systems Estimation II: Applications in Human Diseases. Am. J. Epidemiol. 1995, 142, 1059–1068. [Google Scholar] [CrossRef]
- World Health Organization. Guidelines on Estimating the Size of Populations Most at Risk to HIV; World Health Organization: Geneva, Switzerland, 2010; ISBN 978-92-4-159958-0. [Google Scholar]
- Johnsen, E.C.; Killworth, P.D.; Robinson, S. Estimating the Size of an Average Personal Network and of an Event Subpopulation. Small World 1989, 159–175. [Google Scholar] [CrossRef]
- Bernard, H.R.; Johnsen, E.C.; Killworth, P.D.; Robinson, S. Estimating the Size of an Average Personal Network and of an Event Subpopulation: Some Empirical Results. Soc. Sci. Res. 1991, 20, 109–121. [Google Scholar] [CrossRef]
- Verdery, A.M.; Weir, S.; Reynolds, Z.; Mulholland, G.; Edwards, J.K. Estimating Hidden Population Sizes with Venue-Based Sampling. Epidemiology 2019, 30, 901–910. [Google Scholar] [CrossRef]
- Snidero, S.; Morra, B.; Corradetti, R.; Gregori, D. Use of the Scale-up Methods in Injury Prevention Research: An Empirical Assessment to the Case of Choking in Children. Soc. Netw. 2007, 29, 527–538. [Google Scholar] [CrossRef]
- Ezoe, S.; Morooka, T.; Noda, T.; Sabin, M.L.; Koike, S. Population Size Estimation of Men Who Have Sex with Men through the Network Scale-up Method in Japan. PLoS ONE 2012, 7, e31184. [Google Scholar] [CrossRef] [Green Version]
- Sadler, G.R.; Lee, H.-C.; Seung-Hwan Lim, R.; Fullerton, J. Recruiting Hard-to-Reach United States Population Sub-Groups via Adaptations of Snowball Sampling Strategy. Nurs. Health Sci. 2010, 12, 369–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biernacki, P.; Waldorf, D. Snowball Sampling: Problems and Techniques of Chain Referral Sampling. Sociol. Methods Res. 2016. [Google Scholar] [CrossRef]
- Jing, L.; Lu, Q.; Cui, Y.; Yu, H.; Wang, T. Combining the Randomized Response Technique and the Network Scale-up Method to Estimate the Female Sex Worker Population Size: An Exploratory Study. Public Health 2018, 160, 81–86. [Google Scholar] [CrossRef]
- Killworth, P.D.; McCarty, C.; Bernard, H.R.; Shelley, G.A.; Johnsen, E.C. Estimation of Seroprevalence, Rape, and Homelessness in the United States Using a Social Network Approach. Eval. Rev. 1998, 22, 289–308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, W.; Bao, S.; Lin, W.; Wu, G.; Zhang, W.; Hladik, W.; Abdul-Quader, A.; Bulterys, M.; Fuller, S.; Wang, L. Estimating the Size of HIV Key Affected Populations in Chongqing, China, Using the Network Scale-up Method. PLoS ONE 2013, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teo, A.K.J.; Prem, K.; Chen, M.I.C.; Roellin, A.; Wong, M.L.; La, H.H.; Cook, A.R. Estimating the Size of Key Populations for HIV in Singapore Using the Network Scale-up Method. Sex. Transm. Infect. 2019, 95, 602–607. [Google Scholar] [CrossRef] [Green Version]
- Feehan, D.M.; Umubyeyi, A.; Mahy, M.; Hladik, W.; Salganik, M.J. Quantity Versus Quality: A Survey Experiment to Improve the Network Scale-up Method. Am. J. Epidemiol. 2016, 183, 747–757. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jafari Khounigh Ali, A.; Haghdoost, A.A.; SalariLak, S.; Zeinalzadeh, A.H.; Yousefi-Farkhad, R.; Mohammadzadeh, M.; Holakouie-Naieni, K. Size Estimation of Most-at-Risk Groups of HIV/AIDS Using Network Scale-up in Tabriz, Iran. J. Clin. Res. Gov. 2014, 3, 21–26. [Google Scholar]
- Maltiel, R.; Raftery, A.E.; McCormick, T.H.; Baraff, A.J. Estimating Population Size Using the Network Scale Up Method. Ann. Appl. Stat. 2015, 9, 1247–1277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salganik, M.J.; Fazito, D.; Mello, M.B. Estimating the Number of Heavy Drug Users in Curitiba, Brazil Using Multiple Methods. Technical Report; UNAIDS: New York, NY, USA, 2010. [Google Scholar]
- Shokoohi, M.; Baneshi, M.R.; Haghdoost, A.-A. Size Estimation of Groups at High Risk of HIV/AIDS Using Network Scale Up in Kerman, Iran. Int. J. Prev. Med. 2012, 3, 471–476. [Google Scholar]
- Wang, J.; Yang, Y.; Zhao, W.; Su, H.; Zhao, Y.; Chen, Y.; Zhang, T.; Zhang, T. Application of Network Scale up Method in the Estimation of Population Size for Men Who Have Sex with Men in Shanghai, China. PLoS ONE 2015, 10, e0143118. [Google Scholar] [CrossRef]
- Maghsoudi, A.; Baneshi, M.R.; Neydavoodi, M.; Haghdoost, A. Network Scale-Up Correction Factors for Population Size Estimation of People Who Inject Drugs and Female Sex Workers in Iran. PLoS ONE 2014, 9. [Google Scholar] [CrossRef]
- Ahmadi-Gohari, M.; Zolala, F.; Iranpour, A.; Baneshi, M.R. Twelve-Hour before Driving Prevalence of Alcohol and Drug Use among Heavy Vehicle Drivers in South East of Iran Using Network Scale Up. Addict Health 2019, 11, 256–261. [Google Scholar] [CrossRef]
- Narouee, S.; Shati, M.; Nasehi, M.; Dadgar, F. The Size Estimation of Injection Drug Users (IDUs) Using the Network Scale-up Method (NSUM) in Iranshahr, Iran. Med. J. Islam. Repub. Iran 2019, 33, 158. [Google Scholar] [CrossRef]
- Nikfarjam, A.; Shokoohi, M.; Shahesmaeili, A.; Haghdoost, A.A.; Baneshi, M.R.; Haji-Maghsoudi, S.; Rastegari, A.; Nasehi, A.A.; Memaryan, N.; Tarjoman, T. National Population Size Estimation of Illicit Drug Users through the Network Scale-up Method in 2013 in Iran. Int. J. Drug Policy 2016, 31, 147–152. [Google Scholar] [CrossRef]
- Zahedi, R.; Noroozi, A.; Hajebi, A.; Haghdoost, A.A.; Baneshi, M.R.; Sharifi, H.; Mirzazadeh, A. Self-Reported and Network Scale-Up Estimates of Substance Use Prevalence among University Students in Kerman, Iran. J. Res. Health Sci. 2018, 18, e00413. [Google Scholar]
- Kadushin, C.; Killworth, P.D.; Bernard, H.R.; Beveridge, A.A. Scale-up Methods as Applied to Estimates of Heroin Use. J. Drug Issues 2006, 36, 417–440. [Google Scholar] [CrossRef]
- Nikfarjam, A.; Hajimaghsoudi, S.; Rastegari, A.; Haghdoost, A.A.; Nasehi, A.A.; Memaryan, N.; Tarjoman, T.; Baneshi, M.R. The Frequency of Alcohol Use in Iranian Urban Population: The Results of a National Network Scale Up Survey. Int. J. Health Policy Manag. 2016, 6, 97–102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heydari, Z.; Baneshi, M.R.; Sharifi, H.; Zamanian, M.; Haji-Maghsoudi, S.; Zolala, F. Evaluation of the Treatment Failure Ratio in Individuals Receiving Methadone Maintenance Therapy via the Network Scale up Method. Int. J. Drug Policy 2019, 73, 36–41. [Google Scholar] [CrossRef] [PubMed]
- Mohebbi, E.; Baneshi, M.R.; Haji-maghsoodi, S.; Haghdoost, A.A. The Application of Network Scale Up Method on Estimating the Prevalence of Some Disabilities in the Southeast of Iran. J. Res. Health Sci. 2014, 14, 272–275. [Google Scholar] [PubMed]
- Rastegari, A.; Baneshi, M.R.; Haji-maghsoudi, S.; Nakhaee, N.; Eslami, M.; Malekafzali, H.; Haghdoost, A.A. Estimating the Annual Incidence of Abortions in Iran Applying a Network Scale-up Approach. Iran. Red Crescent Med. J. 2014, 16. [Google Scholar] [CrossRef] [Green Version]
- Zamanian, M.; Zolala, F.; Haghdoost, A.A.; Haji-Maghsoudi, S.; Heydari, Z.; Baneshi, M.R. Methodological Considerations in Using the Network Scale Up (NSU) for the Estimation of Risky Behaviors of Particular Age-Gender Groups: An Example in the Case of Intentional Abortion. PLoS ONE 2019, 14. [Google Scholar] [CrossRef] [Green Version]
- Snidero, S.; Soriani, N.; Baldi, I.; Zobec, F.; Berchialla, P.; Gregori, D. Scale-up Approach in CATI Surveys for Estimating the Number of Foreign Body Injuries in the Aero-Digestive Tract in Children. Int. J. Environ. Res. Public Health 2012, 9, 4056–4067. [Google Scholar] [CrossRef] [Green Version]
- Carletti, G.; Soriani, N.; Mattiazzi, M.; Gregori, D. A Social Network Approach to the Estimation of Perceived Quality of Health Care. Open Nurs. J. 2017, 11, 219–231. [Google Scholar] [CrossRef]
- Paniotto, V.; Petrenko, T.; Kupriyanov, O.; Pakhok, O. Estimating the Size of Populations with High Risk for HIV Using the Network Scale-up Method; Kiev International Institute of SociologyO: Kiev, Ukraine, 2009. [Google Scholar]
- World Health Organization. 2010-Guidelines on Estimating the Size of Populations m.Pdf; WHO: Geneva, Switzerland, 2010. [Google Scholar]
- McCormick, T.H.; Salganik, M.J.; Zheng, T. How Many People Do You Know?: Efficiently Estimating Personal Network Size. J. Am. Stat. Assoc. 2010, 105, 59–70. [Google Scholar] [CrossRef] [Green Version]
- Haghdoost, A.; Ahmadi Gohari, M.; Mirzazadeh, A.; Zolala, F.; Baneshi, M.R. A Review of Methods to Estimate the Visibility Factor for Bias Correction in Network Scale-up Studies. Epidemiol. Health 2018, 40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sajjadi, H.; Jorjoran Shushtari, Z.; Shati, M.; Salimi, Y.; Dejman, M.; Vameghi, M.; Karimi, S.; Mahmoodi, Z. An Indirect Estimation of the Population Size of Students with High-Risk Behaviors in Select Universities of Medical Sciences: A Network Scale-up Study. PLoS ONE 2018, 13, e0195364. [Google Scholar] [CrossRef] [PubMed]
- Habecker, P.; Dombrowski, K.; Khan, B. Improving the Network Scale-Up Estimator: Incorporating Means of Sums, Recursive Back Estimation, and Sampling Weights. PLoS ONE 2015, 10, e0143406. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haghdoost, A.A.; Baneshi, M.R.; Haji-Maghsoodi, S.; Molavi-Vardanjani, H.; Mohebbi, E. Application of a Network Scale-up Method to Estimate the Size of Population of Breast, Ovarian/Cervical, Prostate and Bladder Cancers. Asian Pac. J. Cancer Prev. 2015, 16, 3273–3277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kazemzadeh, Y.; Shokoohi, M.; Baneshi, M.R.; Haghdoost, A.A. The Frequency of High-Risk Behaviors Among Iranian College Students Using Indirect Methods: Network Scale-Up and Crosswise Model. Int. J. High Risk Behav. Addict. 2016, 5. [Google Scholar] [CrossRef] [Green Version]
- Moradinazar, M.; Najafi, F.; Baneshi, M.R.; Haghdoost, A.A. Size Estimation of Under-Reported Suicides and Suicide Attempts Using Network Scale up Method. Bull Emerg. Trauma 2019, 7, 99–104. [Google Scholar] [CrossRef]
- Narouee, S.; Shatti, M.; Didevar, M.; Nasehi, M. Estimating Social Network Size Using Network Scale-up Method (NSUM) in Iranshahr, Sistan and Baluchestan Province, Iran. Med. J. Islam. Repub. Iran 2020, 34, 35. [Google Scholar] [CrossRef]
- Shokoohi, M.; Baneshi, M.R.; Haghdoost, A.A. Estimation of the Active Network Size of Kermanian Males. Addict. Health 2010, 2, 81–88. [Google Scholar]
- Vardanjani, H.M.; Baneshi, M.R.; Haghdoost, A. Total and Partial Prevalence of Cancer Across Kerman Province, Iran, in 2014, Using an Adapted Generalized Network Scale-Up Method. Asian Pac. J. Cancer Prev. 2015, 16, 5493–5498. [Google Scholar] [CrossRef]
- Zamanian, M.; Baneshi, M.R.; Haghdoost, A.A.; Mokhtari-Sorkhani, T.; Amiri, F.; Zolala, F. Estimating the Size and Age-Gender Distribution of Women’s Active Social Networks. Addict. Health 2016, 8, 170–178. [Google Scholar] [PubMed]
- Zamanian, M.; Zolala, F.; Haghdoost, A.A.; Baneshi, M.R. Estimating The Annual Abortion Rate in Kerman, Iran: Comparison of Direct, Network Scale-Up, and Single Sample Count Methods. Int. J. Fertil. Steril. 2019, 13, 209–214. [Google Scholar] [CrossRef]
- Gulati, A.; Pomeranz, C.; Qamar, Z.; Thomas, S.; Frisch, D.; George, G.; Summer, R.; DeSimone, J.; Sundaram, B. A Comprehensive Review of Manifestations of Novel Coronaviruses in the Context of Deadly COVID-19 Global Pandemic. Am. J. Med. Sci. 2020. [Google Scholar] [CrossRef]
- Istat.It. Available online: https://www.istat.it/ (accessed on 16 April 2020).
- Bernard, H.R.; Johnsen, E.C.; Killworth, P.D.; McCarty, C.; Shelley, G.A.; Robinson, S. Comparing Four Different Methods for Measuring Personal Social Networks. Soc. Netw. 1990, 12, 179–215. [Google Scholar] [CrossRef]
- Killworth, P.D.; Johnsen, E.C.; McCarty, C.; Shelley, G.A.; Bernard, H.R. A Social Network Approach to Estimating Seroprevalence in the United States. Soc. Netw. 1998, 20, 23–50. [Google Scholar] [CrossRef]
- Maltiel, R.; Baraff, A.J. NSUM: Network Scale Up Method; R package version, 1. 2015. Available online: https://cran.r-project.org/web/packages/NSUM/NSUM.pdf (accessed on 16 april 2020).
- Team, R.C. R: A Language and Environment for Statistical Computing. 2013. Available online: http://softlibre.unizar.es/manuales/aplicaciones/r/fullrefman.pdf (accessed on 16 april 2020).
- Rastegari, A.; Haji-Maghsoudi, S.; Haghdoost, A.; Shatti, M.; Tarjoman, T.; Baneshi, M.R. The Estimation of Active Social Network Size of the Iranian Population. Glob. J. Health Sci. 2013, 5, 217–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alleva, G.; Arbia, G.; Falorsi, P.D.; Zuliani, A. A Sample Approach to the Estimation of the Critical Parameters of the SARS-CoV-2 Epidemics: An Operational Design with a Focus on the Italian Health System. arXiv 2004, arXiv:2004.06068. [Google Scholar]
- Noh, J.; Danuser, G. Estimation of the Fraction of COVID-19 Infected People in U.S. States and Countries Worldwide. PLoS ONE 2021, 16. [Google Scholar] [CrossRef] [PubMed]


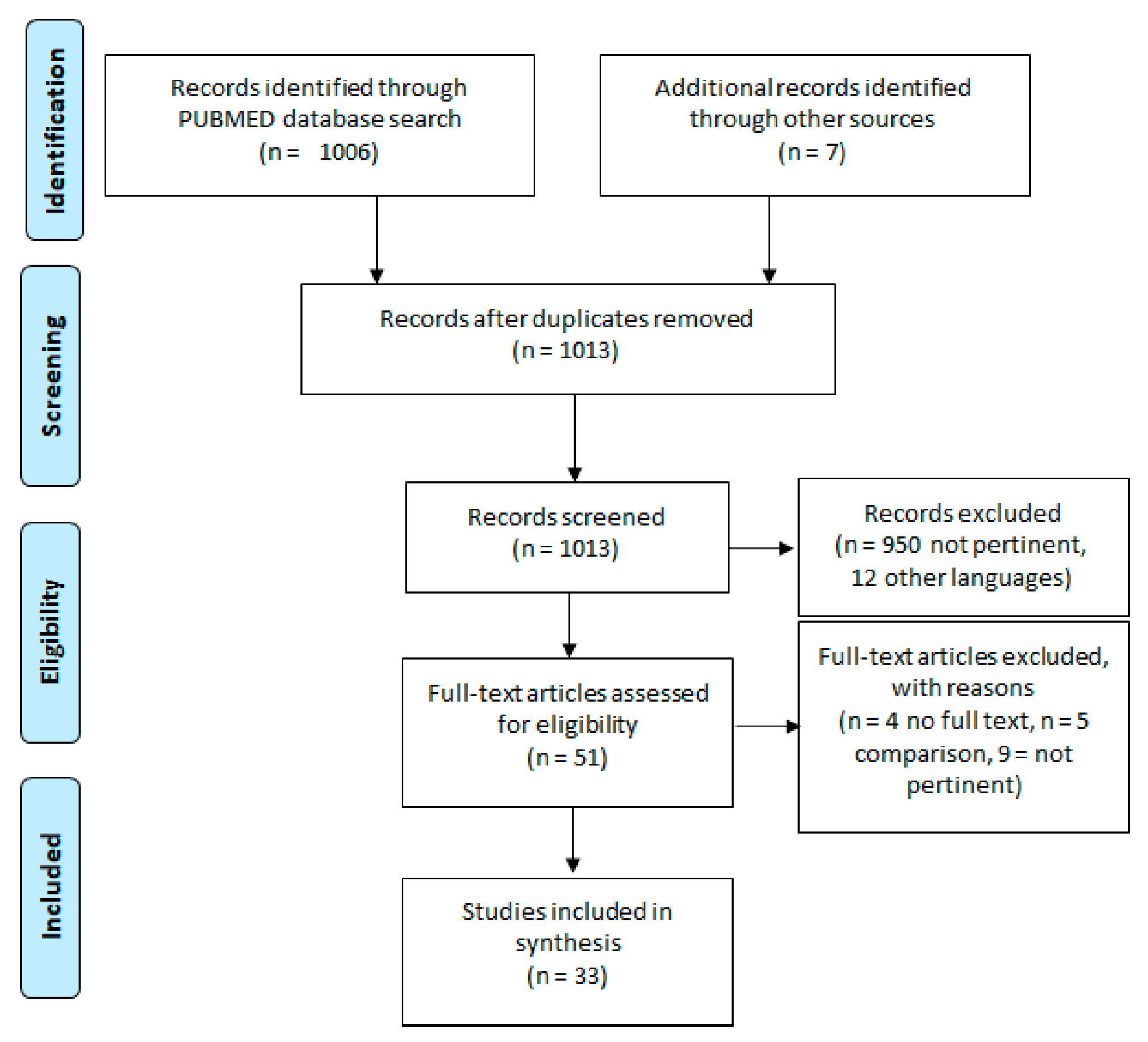{kind=link}
| Author | Year * | N Known Population | Hidden Population | N Respondents | Method | Adjustment | Place |
|---|---|---|---|---|---|---|---|
| Ahmadi [34] | 2019 | 1 | Drug/alcohol users before driving | 363 | NSUM | Iran | |
| Bernard [17] | 1991 | 6 | Deaths in earthquake | NSUM | Mexico | ||
| Carletti [45] | 2017 | 20 | Oncological patients | 299 | NSUM | Italy | |
| Ezoe [20] | 2012 | 3 | Men who have sex with men | NSUM | Transmission Error | Japan | |
| Feehan [27] | 2016 | 22 | Populations at risk for HIV/AIDS | 4669 | Blended Scale-up | Rwanda | |
| Guo [25] | 2013 | 3 | Populations at risk for HIV/AIDS | 2957 | NSUM | China | |
| Habecker [51] | 2015 | 18 | Moved to Nebraska in US during last 2 years, do not approve of interracial dating, heroin users | 618 | Mean Of Sums NSUM | United States | |
| Haghdoost [52] | 2015 | ** | Population of breast, ovarian/cervical, prostate, and bladder cancers | 3052 | NSUM | Iran | |
| Heydari [40] | 2019 | 25 | Treatment failure | 2550 | NSUM | Iran | |
| Jafari [28] | 2014 | 29 | Populations at risk for HIV/AIDS | 500 | NSUM | Transmission Bias, Barrier Effects | Iran |
| Jing [23] | 2018 | 48 | Female sex worker | RRT, NSUM | Response Bias | China | |
| Kadushin [38] | 2006 | 3 | Heroin users | NSUM | United States | ||
| Kazemzadeh [53] | 2016 | ** | High-risk behaviors | 563 | CM, NSUM | Iran | |
| Killworth [24] | 1998 | 24 | HIV prevalence, women who have been raped, the homeless | 1554 | NSUM | United States | |
| Maghsoudi [33] | 2014 | 20 | Injection drug users, female sex workers | 600 | NSUM | Barrier Effect | Iran |
| Maltiel [29] | 2015 | 29 | Populations at risk for HIV/AIDS | 500 | Bayesian NSUM | Transmission Bias, Barrier Effects | Brazil |
| Mccormick [48] | 2010 | 12 | Personal network size | 1370 | Latent Non-Random Mixing Model NSUM | Transmission Bias, Barrier Effects, And Recall Bias. | Brazil |
| Mohebbi [41] | 2014 | ** | People with disabilities | 3052 | NSUM | Iran | |
| Moradinazar [54] | 2019 | ** | Suicides and suicide attempts | 500 | NSUM | Iran | |
| Narouee [35] | 2019 | ** | Injection drug users | 1000 | NSUM | Barrier Effect | Iran |
| Narouee [55] | 2020 | Rural area | 1000 | MLE—NSUM | |||
| Nikfarjam [39] | 2017 | ** | Alcohol use | 12,000 | NSUM | Transmission Bias, Barrier Effects | Iran |
| Nikfarjam [36] | 2016 | ** | Illicit drug users | 7535 | NSUM | Iran | |
| Rastegari [42] | 2014 | ** | Abortions | 12,960 | NSUM | Transmission Bias, Barrier Effects | Iran |
| Sajjadi [50] | 2018 | 6 | Students with high-risk behaviors | 801 | NSUM | Transmission Bias, Barrier Effects | Iran |
| Salganik [30] | 2011 | 20 | Populations at risk for HIV/AIDS | NSUM, GSU | Transmission Bias, Barrier Effects | Brazil | |
| Shokoohi [56] | 2010 | 6 | Network | 500 | NSUM | Iran | |
| Shokoohi [31] | 2012 | ** | Populations at risk for HIV/AIDS | 500 | NSUM | Iran | |
| Snidero [44] | 2012 | 33 | Foreign body injuries | 1081 | NSUM | Italy | |
| Teo [26] | 2019 | 24 | Populations at risk for HIV/AIDS | 199 | Bayesian NSUM | Singapore | |
| Vardanjani [57] | 2015 | ** | Cancer | 195 | Generalized NSUM | Iran | |
| Wang [32] | 2015 | 22 | Men who have sex with men | 3097 | NSUM | China | |
| Zahedi [37] | 2018 | ** | Drug users | 2157 | NSUM | Barrier Effect | Iran |
| Zamanian [58] | 2016 | 25 | Age-gender distribution of women | 1275 | NSUM | Iran | |
| Zamanian [59] | 2019 | 25 | Abortion | 1500 | NSUM | Barrier Effect | Iran |
| Sub-Population of Known Size | Population Size | Reference Year | Source |
|---|---|---|---|
| People who separated | 99,611 | 2016 | Demographic model |
| Foreign residents | 5,255,503 *** | 2019 | Demographic model |
| Victims of car accidents with injuries | 3334 | 2018 | Demographic model |
| People who graduated | 8530 ** | 2018 | MIUR |
| People working part-time | 3,689,153 *** | 2019 | Demographic model |
| Three-member families | 4954 | 2019 | AVQ |
| Cohabiting couples | 14,110 | 2019 | AVQ |
| People who married | 195,778 | 2018 | Demographic model |
| Children born | 440,780 | 2018 | Demographic model |
| People above 14 with smoking habits | 10,122 | 2017 | AVQ |
| People using the mass media (newspapers, magazines, TV, radio, etc.) | 86,142 * | 2017 | AVQ |
| People who attend places of worship | 14,264 | 2018 | AVQ |
| People who walk to work | 2750 | 2018 | AVQ |
| People who go to school by bus | 8743 | 2018 | AVQ |
| Three-year-olds and above who used a PC and Internet | 62,232 | 2017 | AVQ |
| Study Size | Maltiel’s Method | Modified Maltiel’s Method | |||||
|---|---|---|---|---|---|---|---|
| Benchmark Prevalence | Prevalence% | 95% CI Length | Bias | Prevalence% | 95% CI Length | Bias | |
| 1000 | 1.37 | 1.324 | 0.056 | −0.056 | 1.561 | 0.074 | 0.191 |
| 1500 | 1.37 | 1.327 | 0.044 | −0.053 | 1.57 | 0.056 | 0.200 |
| 2000 | 1.37 | 1.329 | 0.038 | −0.051 | 1.567 | 0.044 | 0.197 |
| 2500 | 1.37 | 1.329 | 0.031 | −0.051 | 1.566 | 0.038 | 0.196 |
| 3000 | 1.37 | 1.33 | 0.025 | −0.05 | 1.574 | 0.032 | 0.204 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ocagli, H.; Azzolina, D.; Lorenzoni, G.; Gallipoli, S.; Martinato, M.; Acar, A.S.; Berchialla, P.; Gregori, D.; on behalf of the INCIDENT Study Group. Using Social Networks to Estimate the Number of COVID-19 Cases: The Incident (Hidden COVID-19 Cases Network Estimation) Study Protocol. Int. J. Environ. Res. Public Health 2021, 18, 5713. https://doi.org/10.3390/ijerph18115713
Ocagli H, Azzolina D, Lorenzoni G, Gallipoli S, Martinato M, Acar AS, Berchialla P, Gregori D, on behalf of the INCIDENT Study Group. Using Social Networks to Estimate the Number of COVID-19 Cases: The Incident (Hidden COVID-19 Cases Network Estimation) Study Protocol. International Journal of Environmental Research and Public Health. 2021; 18(11):5713. https://doi.org/10.3390/ijerph18115713
Chicago/Turabian StyleOcagli, Honoria, Danila Azzolina, Giulia Lorenzoni, Silvia Gallipoli, Matteo Martinato, Aslihan S. Acar, Paola Berchialla, Dario Gregori, and on behalf of the INCIDENT Study Group. 2021. "Using Social Networks to Estimate the Number of COVID-19 Cases: The Incident (Hidden COVID-19 Cases Network Estimation) Study Protocol" International Journal of Environmental Research and Public Health 18, no. 11: 5713. https://doi.org/10.3390/ijerph18115713