
Abstract
The implementation of lockdowns has been a key policy to curb the spread of COVID-19 and to keep under control the number of infections. However, quantitatively predicting in advance the effects of lockdowns based on their stringency and duration is a complex task, in turn making it difficult for governments to design effective strategies to stop the disease. Leveraging a novel mathematical “hybrid” approach, we propose a new epidemic model that is able to predict the future number of active cases and deaths when lockdowns with different stringency levels or durations are enforced. The key observation is that lockdown-induced modifications of social habits may not be captured by traditional mean-field compartmental models because these models assume uniformity of social interactions among the population, which fails during lockdown. Our model is able to capture the abrupt social habit changes caused by lockdowns. The results are validated on the data of Israel and Germany by predicting past lockdowns and providing predictions in alternative lockdown scenarios (different stringency and duration). The findings show that our model can effectively support the design of lockdown strategies by stringency and duration, and quantitatively forecast the course of the epidemic during lockdown.
Similar content being viewed by others


Introduction
By the 2nd of January 2020, forty-one hospital cases of infection by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) were confirmed in Wuhan1. By the 11th of March 2020, the coronavirus disease 2019 (COVID-19) that SARS-CoV-2 causes in humans was declared a global pandemic by WHO2. A relatively high infectivity3,4, combined with a substantial fraction of the cases requiring hospital admission and intensive care5,6, makes COVID-19 a threat to the public health. In the absence of effective treatments, capable of preventing a severe and potentially fatal evolution of the disease in humans, and while a vaccine is not widely available, governments around the world are implementing social distancing measures to curb the proliferation of the epidemic7, thus containing the number of complications and deaths. The most drastic of these measures is the implementation of nation-wide lockdowns. Lockdowns have successfully curbed the spread of the disease8,9 and prevented national health services from being overwhelmed by an otherwise unbearably large number of severe infections. Even though since December 2020 vaccination campaigns have started in several countries, it is still unclear when the roll-out will guarantee that a sufficient percentage of the population is vaccinated. Moreover, while vaccines proved to be effective against most new variants10, the Delta variant has shown a moderate resistance to vaccines11. This has made governments cautious about lifting social distancing policies, which as of July 2021 are still enforced in the vast majority of the countries12,13,14.
Mathematical models of epidemics play a crucial role in tackling the proliferation of the disease by predicting the future course of the epidemic and by supporting governmental plans including restrictions on movements, testing, contact tracing and vaccine roll-out. The most popular models are the mean-field compartmental models15,16,17,18. The population is split in multiple, mutually exclusive compartments. Each of these compartments represents a stage of the disease, with individuals moving from a compartment to another as the disease progresses. Several compartmental models have been developed for COVID-19. Cooper et al. designed19 a SIR (Susceptible, Infected and Recovered) model to investigate the spread of the disease in a number of communities, whereas Kyrychko et al. modelled20 the outbreak in Ukraine in a SEIR (Susceptible, Exposed, Infected and Recovered)-type fashion. Kucharski et al. considered21 a stochastic SEIR model to study the spread of infections in and originating from Wuhan, while Davies et al. investigated22 the UK epidemic using a stochastic SEIR-like model stratified by age groups. Giordano et al. proposed23 a compartmental model in which the infected individuals are differentiated both by disease severity and diagnosis stage. Ndaïrou et al. introduced24 a compartmental model with a focus on super-spreader individuals. Della Rossa et al. investigated25 the impact of Italian inter-regional infections by modelling the whole country population as a network of compartmental models. As far as the effects of radical non-pharmaceutical interventions such as lockdowns is concerned, Flaxman et al. proposed26 a model that estimates, backwards from observed deaths, the disease transmission and studied the implications of lockdown timing. Oraby et al. considered27 a continuous-time Markov chain compartmental model and focused on the effect of lockdowns on the hospitalisations. Other mean-field models28,29 explicitly take into account the lockdown effects by changing the model structure when lockdowns are introduced or lifted, but the approaches remain compartmental.
Model
A core, simplifying, assumption of mean-field compartmental models is that all individuals in the population have the same degree of interaction with everyone else. This assumption is violated when a lockdown is in place, because while a minority of individuals (e.g. essential workers) has a high degree of social interactions, the majority limits their contacts to the members of their own household. In other words, on the day in which a lockdown is enforced, the population undergoes an abrupt change in its dynamic behaviour, which undermines the assumption on which traditional mean-field compartmental models are grounded30. The FL-Hybrid (Free-to-Lockdown Hybrid) epidemic model that we propose in this paper overcomes this fundamental limitation, in that it is able to model the instantaneous creation and destruction of these two categories of individuals characterised by different levels of social interaction. The FL-Hybrid model exploits a hybrid mathematical framework31 that allows modelling the interaction between discrete events (e.g. governments introducing lockdowns) on continuous-time dynamics (e.g. compartmental models). The relevance of the FL-Hybrid model that we introduce is not only due to addressing mathematically the sudden change of social behaviour caused by a lockdown. The importance of this new model also lies in the fact that it provides the policymakers with a tool to assess the impact of a past lockdown on the course of the epidemic as well as to plan for potentially new lockdowns, should the cases be on a sharp rise in the future. In fact, a parameter that the model allows tuning is the stringency of the lockdown, i.e. the percentage of population effectively constrained in their own household. Different stringency levels are reflected in real life by, for instance, what type and how many workers are considered essential, thus being allowed to move freely, but also how strictly the rules are enforced and, therefore, how many individuals are expected to abide by them. A second parameter that the model allows tuning is the duration of the lockdown, which may be crucial to evaluate the optimal time to lift it, thus avoiding a new surge in cases as well as preventing an overly prolonged paralysis of the economy. Apart from stringency and duration, which are parameters for the policymakers to design, the rest of the model parameters can be estimated from analysis of the available data, specifically the number of active COVID-19 infections in a given country, the cumulative number of deaths, and the cumulative number of recoveries. The interactions between the free phase and the lockdown phase and, within these, among the sub-models and their inner compartments are shown in Fig. 1. The mathematical formulation of the FL-Hybrid model is provided in the following section. A detailed discussion of the model considerations, assumptions and parameters is provided in the “Methods”.

The FL-Hybrid model. Graphical scheme illustrating the switching between the free and lockdown phases of the FL-Hybrid (Free-to-Lockdown Hybrid) model, as well as the interactions between the sub-models operating within them. The SUDER (Susceptible, Undetected or Undiagnosed Infected, Detected or Diagnosed Infected, Extinct and Recovered) sub-model describes the epidemic dynamics within the whole population in the free phase and within the fraction of the population not isolating during a lockdown. The HP (Household Partitions) sub-model describes the epidemic dynamics within the fraction of population isolating in their own household during a lockdown. Specifically, \(H_i\) denotes the number of households with i undetected infected. The dashed magenta line represents the potential introduction of infections in isolating households from rare but unavoidable external contacts with individuals in the SUDER-sub-model.
Mathematical formulation
The FL-Hybrid (Free-to-Lockdown Hybrid) model is a hybrid dynamical model31 switching between two modes, which we call phases: the free phase and the lockdown phase. Both the free phase and the lockdown phase of the model are described by sets of ordinary differential equations and represent the so-called flow of the hybrid model. The switching action (i.e. the so-called jump set of the hybrid model) corresponds to the government’s action of enforcing or lifting a lockdown.
The free phase models the evolution of the epidemic when the entire population is allowed to move freely and no strict policy requiring the individuals to stay at home and avoid contacts with others is enforced. This phase typically occurs at the beginning of the epidemic or after a period of lockdown, when social distancing measures are relaxed as a result of a drop in number of diagnosed infections. In this phase the assumption of traditional compartmental models is verified, therefore the free phase is described by a sub-model that is a variation of a standard SIR model. We refer to this classical model as SUDER, in which the population is partitioned in five disease stages: S, susceptible; U, undetected or undiagnosed infected; D, detected or diagnosed infected; E, extinct (dead); R, recovered.
The lockdown phase models the evolution of the epidemic when a lockdown is imposed. The population is divided into two categories, which we call the free population and the lockdown population. The free population is a minority that maintains a high number of interactions with other individuals. For example, this is the case of key workers, who are partially exempt from isolation to carry out essential jobs, but also takes into account that some individuals do not comply with the regulations. Thus, the dynamics of the epidemic in the free population is still accurately described by the SUDER sub-model. On the other hand, the lockdown population is assumed to have a drastically reduced number of social interactions. This population is split into households, which are for simplicity assumed to be of fixed size of three members (the rationale of this number is explained in the “Methods”). The dynamics of the epidemic among these individuals is described by the HP, i.e. Household Partitions, sub-model. In the HP sub-model the household, rather than the individual, is the fundamental unit and represents a small group of individuals who often come in contact with each other, but rarely interacts with the rest of the population. Hence, a household with zero infected individuals at the start of the lockdown will most likely keep this status until the end of the lockdown. Susceptible members in a household might still be infected from external contacts, but the probability of this happening is low. Instead, if one or multiple infected individuals are present in the household, then the HP sub-model describes the spread of the disease among the household members, who then, if infected, go through the usual U, D, E, and R stages of infection.
The detailed mathematical description of the free phase and lockdown phase of the model is provided in the forthcoming sections. The switching between these phases and the full discussion of the modelling assumptions is provided in the “Methods”.
Free phase
In the free phase the epidemic evolves according to a standard compartmental sub-model which we call SUDER sub-model. The SUDER sub-model is a dynamical model consisting of six ordinary differential equations. Each equation characterises the change over time of the proportions of population experiencing a specific stage of the disease. This model describes the dynamics of the epidemic when no lockdown measures are introduced. The system of equations is given by
where S (Susceptible), U (infected Undetected), D (infected Detected), E (Extinct), \(R_u\) (undetected Recovered), and \(R_d\) (detected Recovered) are the proportions of the population at each stage of the disease, while the Greek letters represent the parameters of the model and are positive numbers. In particular,
-
\(\beta \) is the disease transmission rate from an undetected infected person to a susceptible person. This is the probability that an undetected person transmits the infection to a susceptible person multiplied by the average number of contacts per person. This parameter is dependent both on the infectivity of the disease and on the number of close contacts between individuals. Therefore this parameter is reduced when social distancing measures are implemented.
-
\(\delta \) is the probability rate of detection, i.e. the probability that an undetected infected person becomes detected after any form of diagnosis. This parameter increases as the scale and efficiency of mass testing and contact tracing policies are improved.
-
\(\rho \) and \(\sigma \) are the probability rates of recovery of undetected and detected infected people, respectively. Undetected people are generally asymptomatic or develop very mild symptoms, compared to detected people who might develop life-threatening conditions. Therefore, \(\rho \) is generally higher than \(\sigma \).
-
\(\theta \) is the mortality rate of detected people and is lowered by more effective treatments.
Lockdown phase
In the lockdown phase the epidemic evolves according to the interaction of two sub-models, one for the free population and one for the lockdown population. This interaction results in a system of twenty-two ordinary differential equations.
Among the free population the epidemic evolves according to the SUDER sub-model, therefore six out of twenty-two equations are analogous to the ones previously introduced and are given by
where both the Latin and Greek letters have the same interpretations as in (1) and the subscript f specifies that the quantities characterise the free population while a lockdown is enforced.
The remaining sixteen equations describe the evolution of the epidemic among the lockdown population and constitute the so-called HP (for Household Partitions) sub-model . This sub-model aims at considerably simplifying the complex dynamics of people isolating in lockdown, while at the same time capturing the fundamental behaviour of the progression of the disease. The core of the HP sub-model is the household, which is a unit composed of 3 individuals. The assumption on the fixed number of individuals is justified in the “Methods”. The equations model the spread of the disease among members of the same household who are observing the lockdown measure, but also the fact that households do not isolate perfectly and new infections can be introduced in a household when its members get in contact with infected people from the free population. Let \(H_i\) denote the number of households with i undetected infected, with \(i=0,1,2,3\). Then the equations describing their dynamics are given by
where \(\beta _h\) denotes the probability rate that an infected household member infects another susceptible person within the household. This parameter depends on the level of interaction between members of the same household, and increases as household members interact more. \(\rho _h\) denotes the probability rate that an undetected household member recovers before infecting other people within the household. Again, this depends on the level of household members’ interaction, but decreases as members interact more. \(\delta _h\) denotes the probability rate that an undetected household member becomes detected before infecting other members. This rate depends on the efficiency of testing policies. \(\beta _{fh}\) denotes the disease transmission rate from an undetected person in the free population to a susceptible person in a infection-free household. This parameter depends on the level of exposure of susceptible members in a household to the free population, and decreases as social distancing measures are tightened.
Let T be the total population, which is considered to be constant. We now define the quantities \(U_i = iH_i/T\) for \(i=1,2,3\), which represent the portions of undetected infected people living in households of type \(H_i\). Analogously, we define the quantities \(D_i\), \(E_i\), \(R_{u,i}\) and \(R_{d,i}\). The set of sixteen equations representing the HP sub-model is then given by
where \(\sigma _h\) denotes the probability rate of recovery of a detected infected household member. \(\theta _h\) denotes the mortality rate of a detected infected household member.
Equations (2) and (4) together describe the lockdown phase of the FL-Hybrid model.
The parameters of the model, both in its free and lockdown phases, are estimated using the official data provided by the national health authorities. In particular, we consider the time histories of the total number of COVID-19 diagnosed cases, deaths and recoveries. We then obtain the time history of the COVID-19 active cases by subtracting the deaths and recoveries from the diagnosed cases. The model parameters are then chosen so as to minimise the weighted mean squared errors between the model-predicted time histories of the active cases, deaths and recoveries and the real ones. The model parameters can be periodically updated to reflect the changes in factors like the stringency of social distancing measures, the effectiveness of testing and contact tracing regimes and the efficacy of treatments. These changes might alter the infection, detection, mortality and recovery rates, thus justifying this parameter updating procedure.
Results and discussion
To illustrate the effectiveness of our model we present two case studies, namely the evolution of the COVID-19 epidemics in Israel and Germany.

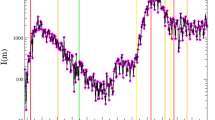
Predicted epidemic evolution under different lockdown stringency. Evolution of the COVID-19 epidemic in Israel and Germany as predicted by our model, based on available government data. (a) Actual evolution and model predictions of the active cases of infections in Israel by lockdown stringency. (b) Actual evolution and model predictions of the deaths in Israel by lockdown stringency. (c) Actual evolution and model predictions of the active cases of infections in Germany by lockdown stringency. (d) Actual evolution and model predictions of the deaths in Germany by lockdown stringency.
Stringency
We first illustrate the effect of changing the strength of lockdown policies on the number of active cases and deaths. We define the active cases of infection at any given time as the difference between the cumulative number of diagnosed infections and the sum of cumulative deaths and recoveries. Figure 2a,b show the change in the number of active cases and deaths as a result of changing the stringency of a lockdown in Israel. We focus on the nation-wide lockdown imposed for thirty days, between 18/09/2020 and 18/10/2020 (days 183 and 213 since the start of the epidemic). The data is compatible with our model prediction that about 65% of the population stayed at home. As shown in Figure 2a a more stringent lockdown would have resulted in an earlier and lower peak of active infections. A less stringent lockdown would have resulted in a peak of active cases of about 0.9413% of the population. The beneficial effects of stricter lockdown policies is also evident on the number of deaths, as shown in Figure 2b. Figure 2c,d show an analogous behaviour when a change in lockdown stringency is considered in relation to the national lockdown imposed in Germany between 23/03/2020 and 12/05/2020 (days 23–73 since the beginning of the outbreak), lasting 50 days. Our model suggests that the government data on active cases and deaths are compatible with 80% of the population isolating within their own household. In Figure 2c a milder lockdown produces a lower and flatter curve of active cases while the latter results in a much higher peak, just slightly less than double the actually diagnosed cases. Figure 2d shows that a milder lockdown would have caused five times as many deaths as a stricter one. While our model suggests that the lockdown is an extremely effective way to curb the spread of the infection among the population, thus confirming previous findings7,9, additionally it allows making two types of assessment. Firstly, it is possible to infer how large the proportion of population actually isolating is. This enables policymakers to evaluate, for example, whether the isolation rules are enforced in an adequate way or if the number of workers considered essential can be increased or must be reduced. Secondly, our model helps to quantify the lockdown effectiveness by predicting potential outcomes, in terms of number of active cases and deaths, when a lockdown is implemented with different levels of strength. Figure 2 shows that even milder forms of lockdown (i.e. making sure that about half of the population is isolating) help to make the curve of active infections flatter, compared to the case of no restrictions, thus avoiding an extremely large number of infections and deaths.

Predicted epidemic evolution under different lockdown durations. Evolution of the COVID-19 epidemic in Israel and Germany as predicted by our model, based on available government data. (a) Actual evolution and model predictions of the active cases of infections in Israel by lockdown duration. (b) Actual evolution and model predictions of the deaths in Israel by lockdown duration. (c) Actual evolution and model predictions of the active cases of infections in Germany by lockdown duration. (d) Actual evolution and model predictions of the deaths in Germany by lockdown duration.
Duration
Having assessed the effects of lockdown stringency on predicted number of infections and deaths, we now consider the implications of different lockdown durations. Figure 3a,b illustrates this for the case study of the lockdown imposed in Israel between 18/09/2020 and 18/10/2020. While the lockdown in Israel lasted thirty days in this instance, we consider alternative scenarios in which a lockdown with the same stringency is lifted later or earlier, and we show our model predictions on a window of thirty days after the lockdown end. As of day 260, a 50-day lockdown would have achieved a tenfold reduction in the number of active cases with respect to the actual thirty-day lockdown. In Fig. 3c,d we show the same for the German nation-wide lockdown between 23/03/2020 and 12/05/2020, considering hypothetical scenarios in which the lockdown would have lasted 40 or 70 days, instead of the actual 50 days, and predicting the course of the epidemic in a 20-day window after the lockdown. While the 40-day German lockdown scenarios produce trends similar to the Israeli case, it is interesting to observe that prolonging the lockdown for twenty more days would not have had as considerable benefits as if Israel had increased the duration of its lockdown. The number of active cases does experience a further drop when the lockdown is longer, while the rise of the number of deaths does appear to slow down. However, these positive outcomes are not as considerable as those produced by a longer lockdown in Israel (which was shorter to begin with). Ultimately, our model suggests that a lockdown duration of about 50 days yields the most benefits, as confirmed by the fact that, had Israel enforced this duration, the additional decrease of active cases and, consequently, of deaths would have been significant. Longer lockdowns might not yield substantial improvements, yet they might be deeply damaging from a social or economic point of view.

Predicted epidemic evolution during the second lockdown. Evolution of the COVID-19 epidemic in Israel and Germany during a second national lockdowns as predicted by our model, based on available government data. The prediction of the evolution during the second lockdown (enforced at the start of the second “wave”) is performed assuming no data from the future course of the epidemic is available at the start of the lockdown. (a) Actual evolution and model prediction of the active cases of infections in Israel throughout the epidemic. (b) Actual evolution and model predictions of the deaths in Israel throughout the epidemic. (c) Actual evolution and model predictions of the active cases of infections in Germany throughout the epidemic. (d) Actual evolution and model predictions of the deaths in Germany throughout the epidemic.
Subsequent lockdown
At last, Fig. 4 demonstrates that our model is able to predict the evolution of a new lockdown only based on data from previous lockdowns. This kind of prediction is different from the previous ones we presented, in that we no longer provide alternative scenarios in which different types of lockdown are implemented. Instead, here we suppose to be at the start of the second lockdown, and we assume that no data is available from the future course of the epidemic. The model is able to reasonably predict the number of active cases and infections in a future time window by leveraging the data collected in the first lockdown. This is a powerful tool that enables policymakers to design the lockdown in order to achieve, for instance, a desired peak of the active cases or to limit the total number of deaths. In Fig. 4a,b we consider the second Israeli national lockdown starting on 27/12/2020 (day 283 of the epidemic). In our model we set a 60% lockdown stringency—instead of the first lockdown’s 65%—to predict the course of the epidemic in the first 15 days of the second lockdown. This is compatible with the fact that in the first days this lockdown was milder than the previous one32. Based on data from the previous lockdown, our model is able to predict that the future peak of the active cases of infections would be about 0.9% of the population. The future increase of the total number of deaths is also accurately reproduced. Figure 4c,d illustrate analogous findings for the second lockdown in Germany, starting on 02/11/2020 (day 247 of the epidemic). This second lockdown is less stringent than the first one32, which is compatible with a 70% stringency in our model, instead of the first lockdown’s 80%. Moreover, the drastically increased testing capacity also reduced the case fatality rate of coronavirus33. Using data collected in the first lockdown and adjusting for a smaller case fatality rate, we predict the course of the epidemic for the first 15 days of lockdown. Our model successfully predicts that the peak of the active cases is approximately at 0.37% of the total population, and is able to provide consistent forecasts of the future trends of deaths. It is important to remark that these predictions of the future course of the epidemic are to be considered an initial and provisional guess of the future trends. When real data is available, this should be used to assess the effectiveness of the lockdown and, by feeding it back to the model, produce improved future predictions. The motivations, findings and implications of our model are summarised in Table 1.
Methods
In this section we describe the switching between the free and lockdown phases of the FL-Hybrid model and discuss the underlying modelling assumptions and justifications.
Switching between phases
When the FL-Hybrid model switches between the free phase and the lockdown phase (and vice versa), some conditions on the variables need to be enforced in order to guarantee consistency.
When a lockdown starts, the FL-Hybrid model switches from the free phase to the lockdown phase. To guarantee consistency, the population that is split among the SUDER sub-model compartments in the free phase needs to be distributed among the compartments of the lockdown phase. To do so, we first define the lockdown percentage L, which is the percentage of the susceptible and undetected population which will become the lockdown population. Denote by \({\bar{t}}\) the moment at which the switching between free phase and lockdown phase occurs. Then at the switching the lockdown population will be \(L( S({\bar{t}}) + U({\bar{t}}))\). Note that we exclude that detected, extinct or recovered people are part of the lockdown population. This assumption makes the analysis of the model simpler without compromising its accuracy. In fact, the population in D is assumed to be perfectly isolated and the population in E, \(R_u\), and \(R_d\) is not infectious anymore. Therefore these variables do not play an active role in the dynamics of the epidemic, although they still play a fundamental role in tracking the impact of the disease. Distributing these portions of population among the households would have very little impact on the evolution of the epidemic among the lockdown population, and for simplicity they can be considered part of the free population. The free population is therefore \((1-L)(S({\bar{t}}) + U({\bar{t}})) + D({\bar{t}}) + E({\bar{t}}) + R_u({\bar{t}}) + R_d({\bar{t}})\). Consequently, the initial conditions for the SUDER sub-model of the free population in the lockdown phase are \(S_f({\bar{t}}) = (1-L)S({\bar{t}})\), \(U_f({\bar{t}}) = (1-L)U({\bar{t}})\), \(D_f({\bar{t}}) = D({\bar{t}})\), \(E_f({\bar{t}}) = E({\bar{t}})\), \(R_{u,f}(\bar{t}) = R_u({\bar{t}})\), \(R_{d,f}({\bar{t}}) = R_d({\bar{t}})\). As far as the lockdown population is concerned, this has to be split appropriately into households. The total number of households is given by
Let \(a_i\) be the proportion of households with i undetected infected at the beginning of the lockdown, i.e. \(H_i = a_i N\), for \(i=0,1,2,3\). The initial conditions of the HP sub-model is then
Note that the coefficients \(a_i\) are constrained in [0, 1] and must satisfy the system of equations
where the first equation comes from the fact that the coefficients \(a_i\) are fractions which must sum to 1 and the second equation ensures consistency in the number of undetected people in lockdown. In fact the total number of undetected infected in the lockdown population is given by \(H_1 + 2H_2 + 3H_3 = (a_1 + 2a_2 + 3a_3)N\) and this number must equal \(LU({\bar{t}})T\). By the definition of N and rearranging the terms, the second equation in (7) is obtained.
At the end of the lockdown, the lockdown population mixes again with the free population, thus starting a new free phase, the dynamics of which is described only by the SUDER sub-model. If the switching between lockdown phase and free phase happens at time \({\hat{t}}\), the initial conditions of this sub-model are easily obtained as follows
Besides the lockdown percentage, another feature that the model lets the user modify is the lockdown duration, i.e. the number of days between the lockdown is enforced and lifted. In terms of the mathematical model, the lockdown duration is the amount of time that the FL-Hybrid model spends in the lockdwown phase.
The parameters of the model have been identified using a nonlinear grey box model in MATLAB. The best fitting parameters have been calculated by solving a weighted nonlinear least-squares problem. This least-squares problem was solved using the MATLAB Optimization Toolbox based on the conditions and constraints we discussed above (e.g. an initial guess and a tuning range for each parameter, a matrix of weights and an estimation window length). Parameters are usually updated every 20–40 days. The initial guesses of parameters for each subsequent estimation were set to be equal to the values of the parameters before the update. See the section “Code availability” for details.
Discussion on modelling assumptions
Before we discuss the modelling assumptions, it is useful to remark that both the SUDER sub-model and the HP sub-model are mean-field models. This implies that the models themselves do not capture the infection transmission and evolution in a case-by-case fashion, but rather describe the averaged dynamics of the epidemic. In this sense, the parameters of the sub-models are to be meant as average rates over the fraction of population (i.e. free or lockdown population) described by the sub-models. Carefully choosing the parameters enables making high-precision predictions of the future trends.
In the SUDER and HP sub-models we make the following simplifying assumptions.
-
The birth rate and mortality rate are assumed to be negligible and thus the total population T is considered to be constant in the model. This is a standard assumption for compartmental models.
-
Detected people are properly isolated and do not transmit the infection to susceptible people, i.e. the number of contacts which detected people have is zero. Therefore, the disease transmission rate from detected infected to susceptible is assumed to be zero. In reality, perfect quarantining does not happen, therefore this rate, although very low, is not zero and depends on a country’s specific policy on detecting and isolating infected individuals. The sub-models might be easily extended to have a non-zero transmission rate from detected infected to susceptible.
-
No undetected people will die from the disease, as the development of life-threatening symptoms would lead to a diagnosis before death occurs. This is not always accurate, especially at the beginning of the epidemic when low detection rates and the inability of health services to cope with the high number of cases might lead to official sources under-reporting the number of casualties34. The sub-models might be extended by adding an additional compartment for deaths from the undetected stage.
-
A recovered person will not become susceptible of re-infections. A prior SARS-Cov-2 infection has been found to be associated to an 83% lower risk of infection, thus justifying this simplifying assumption while still making highly accurate predictions in a period which is equal to the duration of the immunological memory35,36. Re-infections might be introduced in the sub-models by allowing a flow from the R compartments to the S compartment at a given immunity loss rate.
In the HP sub-model we make a number of additional assumptions aimed at considerably simplifying the intricate household dynamics, yet without compromising the sub-model prediction accuracy.
-
The household size is fixed and consists of three members. While in most countries the average household size is generally a number between two and four, (3.1 for Israel and 2.1 for Germany in 201937), our HP sub-model requires an integer size. We selected 3 for both countries in order to simplify the theoretical development, but the equations can be easily adapted to have an integer household size as close as possible to a country’s average household size. Note that, although the number of 3 is quite accurate for Israel, yet it also produces accurate results for Germany. The main limitation of using the average household size is that this simplification relies on a normal distribution which ensures that the approximation is valid. In the cases in which this assumption does not hold, several possible changes can be implemented to maintain the validity of the model. For instance, outliers can be excluded from the dataset (e.g., the percentage of household with 6 or more members is only 0.76% for Germany37). Another approach is to blend multiple HP sub-models which have different household sizes according to the real distribution. Considering households of different sizes is allowed by our model, but it would cause an increase in the number of HP sub-model equations, with minimal benefits in terms of prediction accuracy. Another possible solution is still to use a fixed household size but evaluate the predictions of the model within a 95% confidence interval or a Bayesian credible interval.
-
The coefficients \(a_i\) are selected arbitrarily, yet reasonably, in order to satisfy the constraints in (7) and the constraint \(a_i \in [0,1]\). Note that since the constraints in (7) are a system of two equations in four unknowns, once two of the coefficients, for example \(a_0\) and \(a_1\), are arbitrarily chosen, the remaining ones, i.e. \(a_2\) and \(a_3\), are known functions of the first two. Also note that the bounds on \(a_2\in [0,1]\) and \(a_3\in [0,1]\) provide constraints on the values that \(a_0\) and \(a_1\) can assume. The combination of these constraints limits, in fact, the arbitrariness of the choice. For instance, the coefficient \(a_0\) is constrained to a large value in the range [0, 1]. This is consistent with the fact that, as the infected individuals are a small percentage of the population, the vast majority of the households at the beginning of the lockdown will have no undetected members. Additionally, note that the HP sub-model has very low sensitivity over these coefficients. Changing these coefficients does not produce inaccurate predictions as long as the sub-model parameters—inferred from the official data—are suitably updated.
-
Within the same household, all undetected infected members are diagnosed at once. This assumption is motivated by the fact that if one member of the household tests positive for the infection, it is very likely that the rest of the household will get tested and diagnosed if infected. This process is based on the assumption that sufficient medical resources are available. Thus, it may not be an accurate assumption at the early stage of a vast pandemic when the health system may be overloaded.
-
If infected household members are diagnosed, to avoid spread of the infection the household as a whole will self isolate, as well as its members individually. This prevents new household members from being infected from the outside, and vice versa, and also stops the infection from spreading within the same household.
-
All the cases within the same household will evolve in the same way, i.e. they all either recover or die. Obviously this is not always the case in real circumstances, but, as previously mentioned, this mean-field assumption considerably simplifies the model—making it a simple yet powerful instrument—while still producing good averaged descriptions of the epidemic evolution.
-
The households of individuals belonging to the free population are assumed to be part of the free population as well. These include, for instance, the households of key workers. The rationale is that, although the families of the key workers keep isolating at home, they are still virtually in contact with the rest of the free population through the key workers. This explains why official data is compatible with relatively high percentages of free population in the lockdown phase of our model.
-
When a susceptible person in an isolating household is infected by an individual outside of the household, it is assumed that this happens only by contact with an infected individual in the free population and not from other households. Introducing also inter-household infections is feasible, but the rate would be very low. This is due to the definition of the household unit as a group of individuals with high degree of isolation with respect to the free people. It has been noted in early testings of the model that such a low inter-household rate does not produce significant differences in the predictions. Consequently, such a change would just over-complicate the HP sub-model while yielding negligible benefits from the point of view of its dynamic properties.
To conclude this section, we discuss the meaning and practical implications of the lockdown percentage L in the lockdown phase. This number, which in our model is defined as the fraction of susceptible and undetected individuals isolating in their own household, should not be considered as an absolute measure of the fraction of population isolating in reality. Instead, once the baseline lockdown percentage is identified by fitting the model with the official data, the model allows the user to assess the outcome of more or less stringent lockdowns by increasing or reducing L relative to the baseline.
Effective reproduction number
In both the free phase and lockdown phase, the epidemic grows if the time derivative of the undetected population is higher than zero. For the free phase, this corresponds to
which in turn is equivalent to
The term \(R_t^f\) is the effective reproduction number of the epidemic in the free phase provided by the model, while the basic reproduction number is
In the lockdown phase the epidemic grows when \({\dot{U}}_f + {\dot{U}}_1 + {\dot{U}}_2 + {\dot{U}}_3 > 0\). Using the expressions of these derivatives given in Eqs. (2) and (4) and rearranging we obtain
where \(R_t^\ell \) is the effective reproduction number in the lockdown phase. We now want to show that, at the start of the lockdown, the effective reproduction number can be expressed as a function of the lockdown percentage L. Let \({\bar{t}}\) be the time at which the lockdown is enforced and let \({\bar{S}} = S({\bar{t}})\) and \({\bar{U}} = U({\bar{t}})\) be the portion of susceptible and undetected population at the beginning of the lockdown. Then using the initial conditions \(S_f({\bar{t}}) = (1-L){\bar{S}}\), \(U_f({\bar{t}}) = (1-L){\bar{U}}\), defining \(a = a_1 + 2a_2 + 3a_3\) and using (5), (6), and (7), the effective reproduction number resulting from the introduction of the lockdown can be expressed as a function of L as
By defining \(\eta = \beta _h(a_1 + 2a_2)/a\), \(\xi = \beta _{fh}\left( a_0 + \frac{2}{3}a_1 + \frac{1}{3}a_2\right) /a\) and \(\nu = \sum _{i=1}^3 \left( \frac{\rho _h}{i} + i\,\delta _h\right) a_i/a\), the previous expression reduces to
Note that if \(L = 0\), i.e. no lockdown is imposed, the expression of the effective reproduction number in (14) becomes the same as in (10), i.e. \(R_{{\bar{t}}}^{\ell }(0) = R_{{\bar{t}}}^f\) and the effective reproduction number of the free phase is retrieved.
Data availability
Official epidemiological data was gathered from the COVID-19 Data Repository by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University. The repository is available at https://github.com/CSSEGISandData/COVID-19.
Code availability
The code is available at https://github.com/alberto-mellone/FL-Hybrid-model.
References
Huang, C. et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 395, 497–506 (2020).
WHO Director-General’s opening remarks at the media briefing on COVID-19–11 March 2020 (2020). https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020 (Accessed 7 July 2021).
Guan, W. et al. Clinical characteristics of coronavirus disease 2019 in China. N. Engl. J. Med. 382, 1708–1720 (2020).
Cao, W. & Li, T. COVID-19: Towards understanding of pathogenesis. Cell Res. 30, 367–369 (2020).
Knock, E. S. et al. Report 41: The 2020 SARS-CoV-2 Epidemic in England: Key Epidemiological Drivers and Impact of Interventions. Tech. Rep. (Imperial College COVID-19 response team, 2020).
Richardson, S. et al. Presenting characteristics, comorbidities, and outcomes among 5700 patients hospitalized with COVID-19 in the New York City area. JAMA 323, 2052–2059 (2020).
Haug, N. et al. Ranking the effectiveness of worldwide COVID-19 government interventions. Nat. Hum. Behav. 4, 1303–1312 (2020).
Hsiang, S. et al. The effect of large-scale anti-contagion policies on the COVID-19 pandemic. Nature 584, 262–267 (2020).
Alfano, V. & Ercolano, S. The efficacy of lockdown against COVID-19: A cross-country panel analysis. Appl. Health Econ. Health Policy 18, 509–517 (2020).
Vaidyanathan, G. Coronavirus variants are spreading in India—What scientists know so far. Nature 593, 321–322 (2021).
Callaway, E. Delta coronavirus variant: Scientists brace for impact. Nature 595, 17–18 (2021).
Buchholz, K. Europe Stays in Lockdown Mode (2021). https://www.statista.com/chart/23330/coronavirus-restrictions-europe-map. (Accessed 7 July 2021).
Wang, C. et al. Covid-19 in early 2021: Current status and looking forward. Signal Transduct. Target. Ther. 6, 1–14 (2021).
Willyard, C. COVID and schools: The evidence for reopening safely. Nature 595, 164–167 (2021).
Anirudh, A. Mathematical modeling and the transmission dynamics in predicting the covid-19-what next in combating the pandemic. Infect. Dis. Model. 5, 366–374 (2020).
Adiga, A. et al. Mathematical models for covid-19 pandemic: A comparative analysis. J. Indian Inst. Sci. 100, 793–807 (2020).
Mohamadou, Y., Halidou, A. & Kapen, P. T. A review of mathematical modeling, artificial intelligence and datasets used in the study, prediction and management of covid-19. Appl. Intell. 50, 3913–3925 (2020).
Abou-Ismail, A. Compartmental models of the covid-19 pandemic for physicians and physician-scientists. SN Compr. Clin. Med. 2, 852–858 (2020).
Cooper, I., Mondal, A. & Antonopoulos, C. G. A SIR model assumption for the spread of COVID-19 in different communities. Chaos Solitons Fract. 139, 110057 (2020).
Kyrychko, Y. N., Blyuss, K. B. & Brovchenko, I. Mathematical modelling of the dynamics and containment of COVID-19 in Ukraine. Sci. Rep. 10, 19662 (2020).
Kucharski, A. J. et al. Early dynamics of transmission and control of COVID-19: A mathematical modelling study. Lancet Infect. Dis. 20, 553–558 (2020).
Davies, N. G. et al. Effects of non-pharmaceutical interventions on COVID-19 cases, deaths, and demand for hospital services in the UK: A modelling study. Lancet Public Health 5, e375–e385 (2020).
Giordano, G. et al. Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat. Med. 26, 1–6 (2020).
Ndaïrou, F., Area, I., Nieto, J. J. & Torres, D. F. Mathematical modeling of COVID-19 transmission dynamics with a case study of Wuhan. Chaos Solitons Fract. 135, 109846 (2020).
Della Rossa, F. et al. A network model of Italy shows that intermittent regional strategies can alleviate the COVID-19 epidemic. Nat. Commun. 11, 1–9 (2020).
Flaxman, S. et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature 584, 257–261 (2020).
Oraby, T. et al. Modeling the effect of lockdown timing as a COVID-19 control measure in countries with differing social contacts. Sci. Rep. 11, 1–13 (2021).
Lalwani, S., Sahni, G., Mewara, B. & Kumar, R. Predicting optimal lockdown period with parametric approach using three-phase maturation SIRD model for COVID-19 pandemic. Chaos Solitons Fract. 138, 109939 (2020).
Sardar, T., Nadim, S. S., Rana, S. & Chattopadhyay, J. Assessment of lockdown effect in some states and overall India: A predictive mathematical study on COVID-19 outbreak. Chaos Solitons Fract. 139, 110078 (2020).
Kishore, N. et al. Lockdowns result in changes in human mobility which may impact the epidemiologic dynamics of SARS-COV-2. Sci. Rep. 11, 1–12 (2021).
Goedel, R., Sanfelice, R. G. & Teel, A. R. Hybrid Dynamical Systems: Modeling, Stability, and Robustness (Princeton University Press, Princeton***, 2012).
University of Oxford—Blavatnik School of Government. COVID-19 Government Response Tracker (2020). https://www.bsg.ox.ac.uk/research/research-projects/covid-19-government-response-tracker (Accessed 7 July 2021).
Dimpfl, T., Sönksen, J., Bechmann, I. & Grammig, J. Estimation of the SARS-CoV-2 infection fatality rate in Germany. medRxiv [Preprint] (2021). https://www.medrxiv.org/content/10.1101/2021.01.26.21250507v1 (Accessed 7 July 2021).
Modi, C., Böhm, V., Ferraro, S., Stein, G. & Seljak, U. Estimating covid-19 mortality in Italy early in the covid-19 pandemic. Nat. Commun. 12, 1–9 (2021).
Hall, V. et al. Do antibody positive healthcare workers have lower SARS-CoV-2 infection rates than antibody negative healthcare workers? Large multi-centre prospective cohort study (the SIREN study), England: June to November 2020. medRxiv [Preprint] (2021). https://www.medrxiv.org/content/10.1101/2021.01.13.21249642v1 (Accessed 7 July 2021).
Public Health England - Research and analysis Information on COVID-19 reinfection surveillance in England (2021). https://www.gov.uk/government/publications/national-covid-19-reinfection-surveillance/information-on-covid-19-reinfection-surveillance-in-england (Accessed 7 July 2021).
United Nations—Department of Economic and Social Affairs. Household Size & Composition (2019). https://population.un.org/Household (Accessed 7 July 2021).
Author information
Authors and Affiliations
Contributions
G.S. conceived the modelling framework, planned and provided oversight for all aspects of the study. Z.G. formulated the initial mathematical model, which was refined by G.S. and A.M. A.M. and Z.G. extracted the data, wrote the code and performed fitting and simulations. Z.G. prepared the figures of the manuscript and A.M. wrote the first draft of the manuscript. All authors contributed to subsequent revisions and provided essential intellectual input into all aspects of this study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mellone, A., Gong, Z. & Scarciotti, G. Modelling, prediction and design of COVID-19 lockdowns by stringency and duration. Sci Rep 11, 15708 (2021). https://doi.org/10.1038/s41598-021-95163-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-95163-8
This article is cited by
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
