
A Comprehensive Analysis of Clustering Public Utility Bus Passenger’s Behavior during the COVID-19 Pandemic: Utilization of Machine Learning with Metaheuristic Algorithm

 , and
, and 
Abstract
:1. Introduction
2. Literature Review
2.1. Features Affecting the PUB Passengers’ Behaviors
2.2. Feature Selection
2.2.1. Filter Method—Correlation
2.2.2. Filter Method—Univariate Selection
2.2.3. Wrapper Method—Backward Elimination
2.2.4. Wrapper Method—Recursive Feature Elimination
2.2.5. Embedded Method—LASSO
2.2.6. Stepwise Regression
2.3. K-Means Clustering
2.4. Particle Swarm Optimization
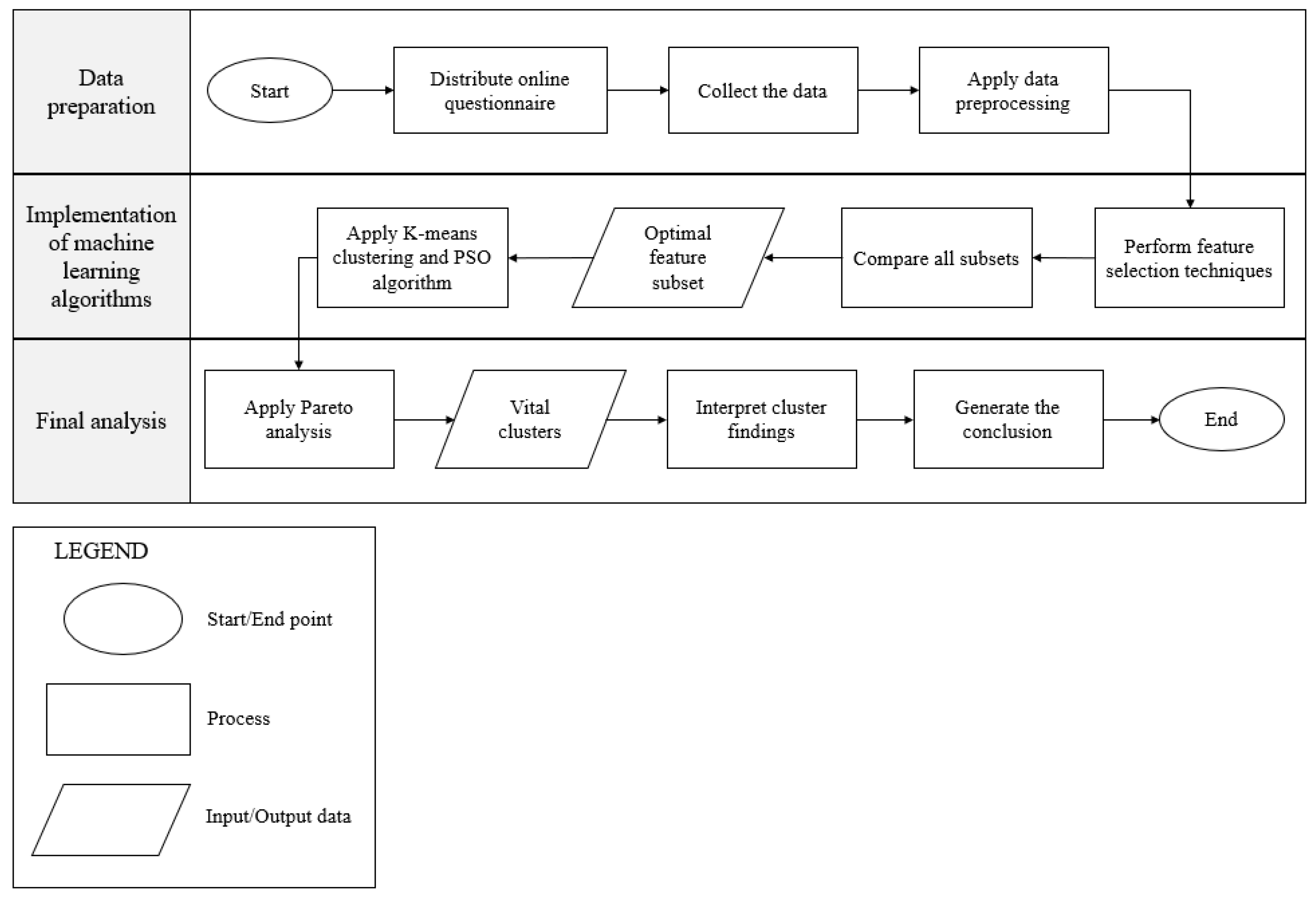
3. Methodology
3.1. Data Collection and Preparation
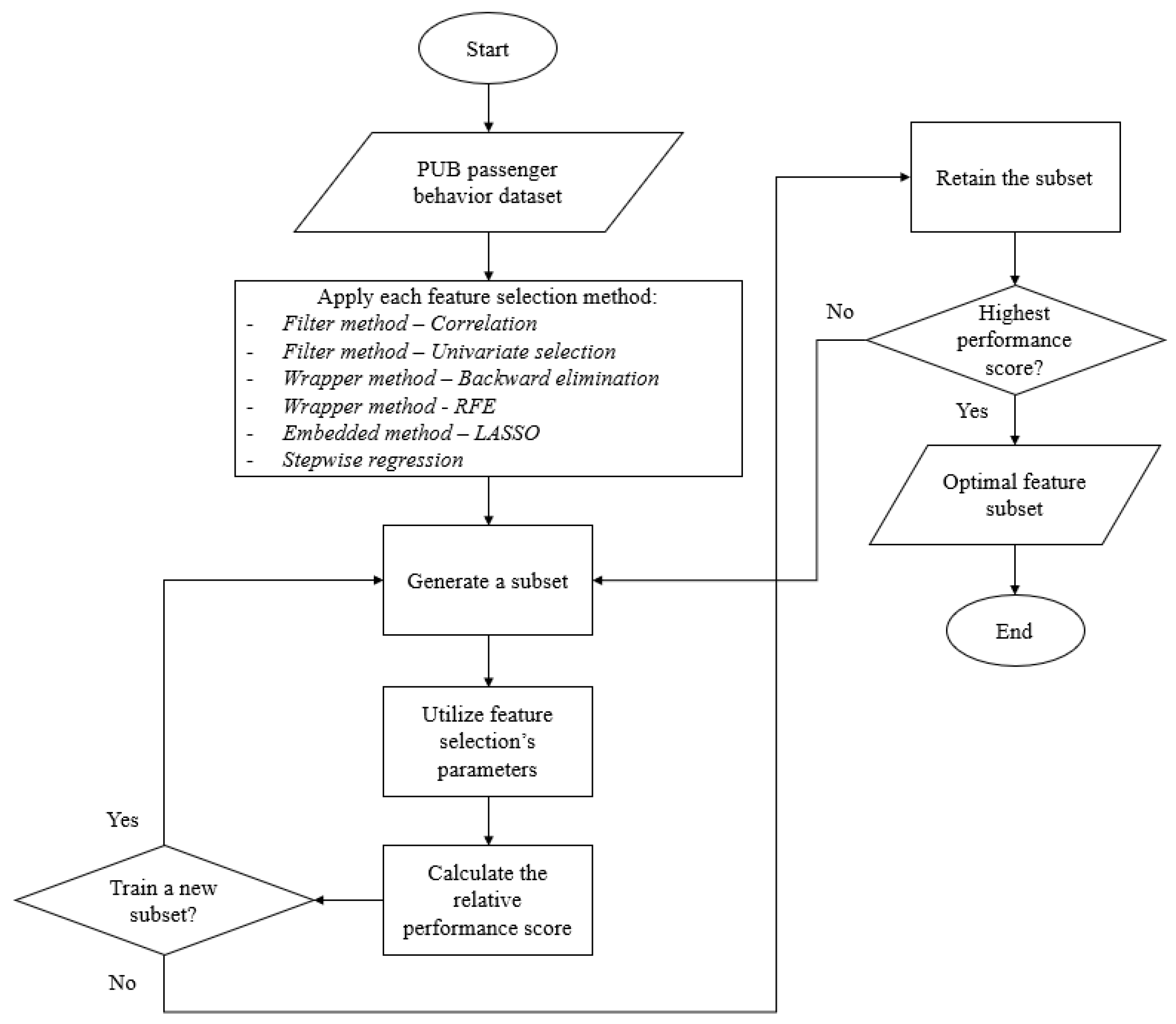
3.2. Feature Selection
3.2.1. Filter Method—Correlation
3.2.2. Filter Method—Univariate Selection
3.2.3. Wrapper Method—Backward Elimination
3.2.4. Wrapper Method—Recursive Feature Elimination
3.2.5. Wrapper Method—Embedded Method—LASSO
3.2.6. Stepwise Regression
3.3. K-Means Clustering and PSO Algorithm
4. Results and Discussion
4.1. Feature Selection
4.2. K-Means and PSO Algorithms
4.3. Clustering Summary
4.4. Managerial Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mayo, F.L.; Taboada, E.B. Ranking Factors Affecting Public Transport Mode Choice of Commuters in an Urban City of a Developing Country Using Analytic Hierarchy Process: The Case of Metro Cebu, Philippines. Transp. Res. Interdiscip. Perspect. 2020, 4, 100078. [Google Scholar] [CrossRef]
- Guillen, M.D.; Ishida, H.; Okamoto, N. Is the Use of Informal Public Transport Modes in Developing Countries Habitual? an Empirical Study in Davao City, Philippines. Transp. Policy 2013, 26, 31–42. [Google Scholar] [CrossRef]
- Dela Peña, K. Sensible Public Transport: A Post-Pandemic Dream. Available online: https://newsinfo.inquirer.net/1507740/sensible-public-transport-a-post-pandemic-dream (accessed on 10 January 2022).
- Philippine Statistics Authority. Highlights of the Philippine Population 2020 Census of Population and Housing (2020 CPH). Available online: https://psa.gov.ph/content/highlights-philippine-population-2020-census-population-and-housing-2020-cph (accessed on 10 January 2022).
- Abadilla, E.V. DOTR Issues Level 3 Directive to Buses & Puvs. Manila Bulletin. Available online: https://mb.com.ph/2022/01/03/dotr-level3-directive-to-buses-puvs/ (accessed on 10 January 2022).
- Cahigas, M.M.; Prasetyo, Y.T.; Persada, S.F.; Ong, A.K.; Nadlifatin, R. Understanding the Perceived Behavior of Public Utility Bus Passengers during the Era of COVID-19 Pandemic in the Philippines: Application of Social Exchange Theory and Theory of Planned Behavior. Res. Transp. Bus. Manag. 2022, 45, 100840. [Google Scholar] [CrossRef]
- Tsai, C.-F. Feature Selection in Bankruptcy Prediction. Knowl. Based Syst. 2009, 22, 120–127. [Google Scholar] [CrossRef]
- Budak, A.; Sarvari, P.A. Profit Margin Prediction in Sustainable Road Freight Transportation Using Machine Learning. J. Clean. Prod. 2021, 314, 127990. [Google Scholar] [CrossRef]
- Chou, S.-Y.; Dewabharata, A.; Bayu, Y.C.; Cheng, R.-G.; Zulvia, F.E. An Automatic Energy Saving Strategy for a Water Dispenser Based on User Behavior. Adv. Eng. Inform. 2022, 51, 101503. [Google Scholar] [CrossRef]
- Rose, S.; Nickolas, S.; Sangeetha, S. A Recursive Ensemble-Based Feature Selection for Multi-Output Models to Discover Patterns among the Soil Nutrients. Chemom. Intell. Lab. Syst. 2021, 208, 104221. [Google Scholar] [CrossRef]
- Joshi, C.; Ranjan, R.K.; Bharti, V. A Fuzzy Logic Based Feature Engineering Approach for Botnet Detection Using Ann. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 6872–6882. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations; Project Euclid: Durham, NC, USA, 1966. [Google Scholar]
- Jain, A.K. Data Clustering: 50 Years beyond K-Means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Kuo, R.J.; Rizki, M.; Zulvia, F.E.; Khasanah, A.U. Integration of Growing Self-Organizing Map and Bee Colony Optimization Algorithm for Part Clustering. Comput. Ind. Eng. 2018, 120, 251–265. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science (MHS’95), Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Sahab, M.G.; Toropov, V.V.; Gandomi, A.H. A Review on Traditional and Modern Structural Optimization. In Metaheuristic Applications in Structures and Infrastructures; Elsevier: London, UK; Waltham, MA, USA, 2013; pp. 25–47. [Google Scholar]
- Bommert, A.; Welchowski, T.; Schmid, M.; Rahnenführer, J. Benchmark of Filter Methods for Feature Selection in High-Dimensional Gene Expression Survival Data. Brief. Bioinform. 2021, 23, bbab354. [Google Scholar] [CrossRef] [PubMed]
- Matharaarachchi, S.; Domaratzki, M.; Muthukumarana, S. Assessing Feature Selection Method Performance with Class Imbalance Data. Mach. Learn. Appl. 2021, 6, 100170. [Google Scholar] [CrossRef]
- Anderson, T.K. Kernel Density Estimation and K-Means Clustering to Profile Road Accident Hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef] [PubMed]
- Fotouhi, A.; Montazeri-Gh, M. Tehran Driving Cycle Development Using the K-Means Clustering Method. Tehran Driv. Cycle Dev. Using K Means Clust. Method. Sci. Iran. 2013, 20, 286–293. [Google Scholar]
- Kechagiopoulos, P.N.; Beligiannis, G.N. Solving the Urban Transit Routing Problem Using a Particle Swarm Optimization Based Algorithm. Appl. Soft Comput. 2014, 21, 654–676. [Google Scholar] [CrossRef]
- Zhong, S.; Zhou, L.; Ma, S.; Jia, N.; Zhang, L.; Yao, B. The Optimization of Bus Rapid Transit Route Based on an Improved Particle Swarm Optimization. Transp. Lett. 2016, 10, 257–268. [Google Scholar] [CrossRef]
- Li, N.; Yang, L.; Li, X.; Li, X.; Tu, J.; Cheung, S.C.P. Multi-Objective Optimization for Designing of High-Speed Train Cabin Ventilation System Using Particle Swarm Optimization and Multi-Fidelity Kriging. Build. Environ. 2019, 155, 161–174. [Google Scholar] [CrossRef]
- Li, X.; Li, D.; Hu, X.; Yan, Z.; Wang, Y. Optimizing Train Frequencies and Train Routing with Simultaneous Passenger Assignment in High-Speed Railway Network. Comput. Ind. Eng. 2020, 148, 106650. [Google Scholar] [CrossRef]
- Ittamalla, R.; Srinivas Kumar, D.V. Determinants of Holistic Passenger Experience in Public Transportation: Scale Development and Validation. J. Retail. Consum. Serv. 2021, 61, 102564. [Google Scholar] [CrossRef]
- Atombo, C.; Dzigbordi Wemegah, T. Indicators for Commuter’s Satisfaction and Usage of High Occupancy Public Bus Transport Service in Ghana. Transp. Res. Interdiscip. Perspect. 2021, 11, 100458. [Google Scholar] [CrossRef]
- Tiglao, N.C.; De Veyra, J.M.; Tolentino, N.J.; Tacderas, M.A. The Perception of Service Quality among Paratransit Users in Metro Manila Using Structural Equations Modelling (SEM) Approach. Res. Transp. Econ. 2020, 83, 100955. [Google Scholar] [CrossRef]
- Chen, M.-C.; Hsu, C.-L.; Huang, C.-H. Applying the Kano Model to Investigate the Quality of Transportation Services at Mega Events. J. Retail. Consum. Serv. 2021, 60, 102442. [Google Scholar] [CrossRef]
- Quy Nguyen-Phuoc, D.; Ngoc Su, D.; Nguyen, T.; Vo, N.S.; Thi Phuong Tran, A.; Johnson, L.W. The Roles of Physical and Social Environments on the Behavioural Intention of Passengers to Reuse and Recommend Bus Systems. Travel Behav. Soc. 2022, 27, 162–172. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, S.; Sun, W.; Chen, C.-L. Exploring the Physical and Mental Health of High-Speed Rail Commuters: Suzhou-Shanghai Inter-City Commuting. J. Transp. Health 2020, 18, 100902. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, M.; Liu, Y.; Ye, R.; Gao, X.; Ma, L. Public Transport Equity in Shenyang: Using Structural Equation Modelling. Res. Transp. Bus. Manag. 2022, 42, 100555. [Google Scholar] [CrossRef]
- Deveci, M.; Öner, S.C.; Canıtez, F.; Öner, M. Evaluation of Service Quality in Public Bus Transportation Using Interval-Valued Intuitionistic Fuzzy QFD Methodology. Res. Transp. Bus. Manag. 2019, 33, 100387. [Google Scholar] [CrossRef]
- Shen, W.; Xiao, W.; Wang, X. Passenger Satisfaction Evaluation Model for Urban Rail Transit: A Structural Equation Modeling Based on Partial Least Squares. Transp. Policy 2016, 46, 20–31. [Google Scholar] [CrossRef]
- Xue, Y.; Zhong, M.; Xue, L.; Zhang, B.; Tu, H.; Tan, C.; Kong, Q.; Guan, H. Simulation Analysis of Bus Passenger Boarding and Alighting Behavior Based on Cellular Automata. Sustainability 2022, 14, 2429. [Google Scholar] [CrossRef]
- Rasoolimanesh, S.M.; Jaafar, M.; Kock, N.; Ramayah, T. A Revised Framework of Social Exchange Theory to Investigate the Factors Influencing Residents’ Perceptions. Tour. Manag. Perspect. 2015, 16, 335–345. [Google Scholar] [CrossRef]
- Turner, M.; Kwon, S.-H.; O’Donnell, M. State Effectiveness and Crises in East and Southeast Asia: The Case of COVID-19. Sustainability 2022, 14, 7216. [Google Scholar] [CrossRef]
- Chuenyindee, T.; Ong, A.K.; Ramos, J.P.; Prasetyo, Y.T.; Nadlifatin, R.; Kurata, Y.B.; Sittiwatethanasiri, T. Public Utility Vehicle Service Quality and Customer Satisfaction in the Philippines during the COVID-19 Pandemic. Util. Policy 2022, 75, 101336. [Google Scholar] [CrossRef] [PubMed]
- Cahigas, M.M.; Prasetyo, Y.T.; Alexander, J.; Sutapa, P.L.; Wiratama, S.; Arvin, V.; Nadlifatin, R.; Persada, S.F. Factors Affecting Visiting Behavior to Bali during the Covid-19 Pandemic: An Extended Theory of Planned Behavior Approach. Sustainability 2022, 14, 10424. [Google Scholar] [CrossRef]
- Thomas, F.M.F.; Charlton, S.G.; Lewis, I.; Nandavar, S. Commuting before and after COVID-19. Transp. Res. Interdiscip. Perspect. 2021, 11, 100423. [Google Scholar] [CrossRef] [PubMed]
- Strielkowski, W.; Zenchenko, S.; Tarasova, A.; Radyukova, Y. Management of Smart and Sustainable Cities in the Post-COVID-19 Era: Lessons and Implications. Sustainability 2022, 14, 7267. [Google Scholar] [CrossRef]
- Borhan, M.N.; Ibrahim, A.N.; Miskeen, M.A. Extending the Theory of Planned Behaviour to Predict the Intention to Take the New High-Speed Rail for Intercity Travel in Libya: Assessment of the Influence of Novelty Seeking, Trust and External Influence. Transp. Res. Part A Policy Pract. 2019, 130, 373–384. [Google Scholar] [CrossRef]
- Fallah Zavareh, M.; Mehdizadeh, M.; Nordfjærn, T. Demand for Mitigating the Risk of COVID-19 Infection in Public Transport: The Role of Social Trust and Fatalistic Beliefs. Transp. Res. Part F Traffic Psychol. Behav. 2022, 84, 348–362. [Google Scholar] [CrossRef]
- Restuputri, D.P.; Indriani, T.R.; Masudin, I. The Effect of Logistic Service Quality on Customer Satisfaction and Loyalty Using Kansei Engineering during the COVID-19 Pandemic. Cogent Bus. Manag. 2021, 8, 1906492. [Google Scholar] [CrossRef]
- Ajzen, I. The Theory of Planned Behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Cahigas, M.M.; Prasetyo, Y.T.; Persada, S.F.; Nadlifatin, R. Examining Filipinos’ Intention to Revisit Siargao after Super Typhoon Rai 2021 (Odette): An Extension of the Theory of Planned Behavior Approach. Int. J. Disaster Risk Reduct. 2023, 84, 103455. [Google Scholar] [CrossRef]
- Lee, J.; Baig, F.; Pervez, A. Impacts of COVID-19 on Individuals’ Mobility Behavior in Pakistan Based on Self-Reported Responses. J. Transp. Health 2021, 22, 101228. [Google Scholar] [CrossRef]
- van Wee, B.; Witlox, F. COVID-19 and Its Long-Term Effects on Activity Participation and Travel Behaviour: A Multiperspective View. J. Transp. Geogr. 2021, 95, 103144. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Gu, H.; Gu, S.; You, H. Individual Motivation and Social Influence: A Study of Telemedicine Adoption in China Based on Social Cognitive Theory. Health Policy Technol. 2021, 10, 100525. [Google Scholar] [CrossRef]
- Krettenauer, T.; Lefebvre, J.P. Beyond Subjective and Personal: Endorsing pro-Environmental Norms as Moral Norms. J. Environ. Psychol. 2021, 76, 101644. [Google Scholar] [CrossRef]
- Cahigas, M.M.; Prasetyo, Y.T.; Persada, S.F.; Nadlifatin, R. Filipinos’ Intention to Participate in 2022 Leyte Landslide Response Volunteer Opportunities: The Role of Understanding the 2022 Leyte Landslide, Social Capital, Altruistic Concern, and Theory of Planned Behavior. Int. J. Disaster Risk Reduct. 2023, 84, 103485. [Google Scholar] [CrossRef]
- Shaaban, K.; Maher, A. Using the Theory of Planned Behavior to Predict the Use of an Upcoming Public Transportation Service in Qatar. Case Stud. Transp. Policy 2020, 8, 484–491. [Google Scholar] [CrossRef]
- Gao, Y.; Chen, X.; Shan, X.; Fu, Z. Active Commuting among Junior High School Students in a Chinese Medium-Sized City: Application of the Theory of Planned Behavior. Transp. Res. Part F Traffic Psychol. Behav. 2018, 56, 46–53. [Google Scholar] [CrossRef]
- Granados-López, D.; Suárez-García, A.; Díez-Mediavilla, M.; Alonso-Tristán, C. Feature selection for CIE Standard Sky Classification. Sol. Energy 2021, 218, 95–107. [Google Scholar] [CrossRef]
- Xiong, C.; Yang, M.; Kozar, R.; Zhang, L. Integrating transportation data with Emergency Medical Service Records to improve triage decision of high-risk trauma patients. J. Transp. Health 2021, 22, 101106. [Google Scholar] [CrossRef]
- Liu, Y.; Lyu, C.; Liu, Z.; Cao, J. Exploring a large-scale multi-modal transportation recommendation system. Transp. Res. Part C Emerg. Technol. 2021, 126, 103070. [Google Scholar] [CrossRef]
- Soares, E.F.d.S.; Campos, C.A.V.; Lucena, S.C.d. Online Travel Mode Detection Method Using Automated Machine Learning and Feature Engineering. Future Gener. Comput. Syst. 2019, 101, 1201–1212. [Google Scholar] [CrossRef]
- Rodríguez-Sanz, Á.; Fernández de Marcos, A.; Pérez-Castán, J.A.; Comendador, F.G.; Arnaldo Valdés, R.; París Loreiro, Á. Queue Behavioural Patterns for Passengers at Airport Terminals: A Machine Learning Approach. J. Air Transp. Manag. 2021, 90, 101940. [Google Scholar] [CrossRef]
- Yang, J.; Ma, J. Compressive Sensing-Enhanced Feature Selection and Its Application in Travel Mode Choice Prediction. Appl. Soft Comput. 2019, 75, 537–547. [Google Scholar] [CrossRef]
- Thabtah, F.; Kamalov, F.; Hammoud, S.; Shahamiri, S.R. Least Loss: A Simplified Filter Method for Feature Selection. Inf. Sci. 2020, 534, 1–15. [Google Scholar] [CrossRef]
- Cekik, R.; Uysal, A.K. A Novel Filter Feature Selection Method Using Rough Set for Short Text Data. Expert Syst. Appl. 2020, 160, 113691. [Google Scholar] [CrossRef]
- Labani, M.; Moradi, P.; Ahmadizar, F.; Jalili, M. A Novel Multivariate Filter Method for Feature Selection in Text Classification Problems. Eng. Appl. Artif. Intell. 2018, 70, 25–37. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for Feature Subset Selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Żogała-Siudem, B.; Jaroszewicz, S. Fast Stepwise Regression Based on Multidimensional Indexes. Inf. Sci. 2021, 549, 288–309. [Google Scholar] [CrossRef]
- Eltved, M.; Breyer, N.; Ingvardson, J.B.; Nielsen, O.A. Impacts of Long-Term Service Disruptions on Passenger Travel Behaviour: A Smart Card Analysis from the Greater Copenhagen Area. Transp. Res. Part C Emerg. Technol. 2021, 131, 103198. [Google Scholar] [CrossRef]
- Li, Q.; Liu, R.; Zhao, J.; Liu, H.-C. Passenger Satisfaction Evaluation of Public Transport Using Alternative Queuing Method under Hesitant Linguistic Environment. J. Intell. Transp. Syst. 2021, 26, 330–342. [Google Scholar] [CrossRef]
- Shen, C.; Sun, Y.; Bai, Z.; Cui, H. Real-Time Customized Bus Routes Design with Optimal Passenger and Vehicle Matching Based on Column Generation Algorithm. Phys. A Stat. Mech. Its Appl. 2021, 571, 125836. [Google Scholar] [CrossRef]
- Kuo, R.J.; Nugroho, Y.; Zulvia, F.E. Application of Particle Swarm Optimization Algorithm for Adjusting Project Contingencies and Response Strategies under Budgetary Constraints. Comput. Ind. Eng. 2019, 135, 254–264. [Google Scholar] [CrossRef]
- Peng, Y.; Li, T.; Bao, C.; Zhang, J.; Xie, G.; Zhang, H. Performance Analysis and Multi-Objective Optimization of Bionic Dendritic Furcal Energy-Absorbing Structures for Trains. Int. J. Mech. Sci. 2023, 246, 108145. [Google Scholar] [CrossRef]
- Xiao, G.; Juan, Z.; Gao, J. Travel Mode Detection Based on Neural Networks and Particle Swarm Optimization. Information 2015, 6, 522–535. [Google Scholar] [CrossRef]
- German, J.D.; Redi, A.A.; Ong, A.K.; Prasetyo, Y.T.; Sumera, V.L. Predicting Factors Affecting Preparedness of Volcanic Eruption for a Sustainable Community: A Case Study in the Philippines. Sustainability 2022, 14, 11329. [Google Scholar] [CrossRef]
- Voss, D.S. Multicollinearity. In Encyclopedia of Social Measurement; Elsevier: Amsterdam, The Netherlands, 2005; pp. 759–770. [Google Scholar]
- Ryan, L.; Kuhn, S.; Colreavy-Donnely, S.; Caraffini, F. Particle Swarm Optimisation in Practice: Multiple Applications in a Digital Microscope System. Appl. Sci. 2022, 12, 7827. [Google Scholar] [CrossRef]
- Xu, G.; Cui, Q.; Shi, X.; Ge, H.; Zhan, Z.-H.; Lee, H.P.; Liang, Y.; Tai, R.; Wu, C. Particle Swarm Optimization Based on Dimensional Learning Strategy. Swarm Evol. Comput. 2019, 45, 33–51. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J.; Piotrowska, A.E. Population Size in Particle Swarm Optimization. Swarm Evol. Comput. 2020, 58, 100718. [Google Scholar] [CrossRef]
- Kuo, R.J.; Potti, Y.; Zulvia, F.E. Application of metaheuristic based Fuzzy K-modes algorithm to supplier clustering. Comput. Ind. Eng. 2018, 120, 298–307. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | Country | Public Transport Mode | Purpose of the Study | Methodology |
|---|---|---|---|---|---|
| Xiong et al. [54] | 2021 | USA | Emergency vehicle | Optimization of emergency vehicle flow for elderly patients | Feature selection (general) and decision tree model |
| Liu et al. [55] | 2021 | China | Bus, train, car, taxi, and bicycle | Improvement of the multi-modal transportation system in China | Feature selection (proposed and embedded method), bipartite graph, and post-processing algorithm (proposed) |
| Soares et al. [56] | 2019 | USA | Car, train, and bus | Enhancement of the travel modes’ location accuracy and reduction of unnecessary costs | Feature engineering (principal component analysis) and automated machine learning (AutoSklearn) |
| Rodríguez-Sanz et al. [57] | 2021 | Spain | Aviation | Prediction of airport passengers’ queuing behavior at check-in desks and security controls | Random forest, feature analysis (proposed), and machine learning (simulation) |
| Yang and Ma [58] | 2019 | Sydney, Australia | Car, train, and bus | The identification of the most optimal public transport mode choice | Feature selection (Laplacian score, ReliefF, SimbaLinear, mutual information quotient, Genetic Programming, Dynamic Relevance, and Joint Mutual Information Maximization approach) and compressive sensing-based feature selection algorithm |
| Fotouhi and Montazeri-Gh [20] | 2013 | Tehran, Iran | Car | The enhancement of traffic conditions by evaluating driving patterns | Feature extraction (proposed) and K-means clustering |
| Anderson [19] | 2009 | London, England | General | Mitigation of road accidents to promote safety and security | Kernel Density Estimation and K-means clustering |
| Eltved et al. [65] | 2021 | Greater Copenhagen, Denmark | Train | Investigation of passenger behavior before and after the train station closure | K-means algorithm |
| Li et al. [66] | 2021 | Train | Shanghai, China | The effectiveness of passenger satisfaction assessment on train transit lines | K-means clustering and operation research (double hierarchy hesitant linguistic term sets (DHHLTSs) and alternative queuing method (AQM)) |
| Shen et al. [67] | 2021 | China | Bus | Customization of the bus boarding system to determine the appropriate bus stop and destination points | K-means clustering |
| Zhong et al. [22] | 2016 | Dalian, China | Bus | Proposal of new bus transit routes to increase bus efficiency and meet passenger demands | Particle swarm optimization |
| Kechagiopoulos and Beligiannis [21] | 2014 | Switzerland | Bus | Centered on the road problems affecting users of public and private transportation modes | Particle swarm optimization |
| Peng et al. [69] | 2023 | China | Train | Proposal of hybrid optimization decision systems in assessing the structural design of railroad vehicles | VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR), multiple objective particle swarm optimization-crowding distance (MOPSO-CD), and evolutionary algorithm and repetitive VIKOR |
| Li et al. [24] | 2020 | China | Train | Evaluation of three primary high-speed rail networks and passenger assignments for each rail section | Bi-level multi-objective mixed integer nonlinear programming model and particle swarm optimization |
| Xiao et al. [70] | 2015 | Shanghai, China | Bike, bus, and car | Increasing the travel mode detection accuracy in Global Positioning System | Particle swarm optimization and neural network |
| Parameter | Value | Note |
|---|---|---|
| N | 20, 30, 40 | References: Xu et al. [74]; Piotrowski et al. [75] |
| w | 0.6, 0.9 | References: Xu et al. [74]; Piotrowski et al. [75] |
| c1 | 1, 2 | References: Xu et al. [74]; Piotrowski et al. [75] |
| c2 | 1, 2 | References: Xu et al. [74]; Piotrowski et al. [75] |
| M | 23 | Supplementary Materials: PSO Initialization Equations |
| T | 200 | Measured through simulations and supported by Kuo et al. [68] |
| r | 10 | Reference: Ryan et al. [73] |
| Number | Feature | Correlation (R) Value |
|---|---|---|
| 1 | TR3 | 0.5373 |
| 2 | AT2 | 0.5674 |
| 3 | SN1 | 0.5040 |
| 4 | PBC2 | 0.5885 |
| 5 | PBC5 | 0.5564 |
| 6 | IU1 | 0.6588 |
| 7 | IU3 | 0.6403 |
| Number | Feature | Chi-Square | p-Value |
|---|---|---|---|
| 1 | IU2 | 88.9751 | 0.0043 |
| 2 | IU5 | 88.6177 | 0.0046 |
| 3 | IU6 | 81.3142 | 0.0189 |
| Number | Feature | p-Value |
|---|---|---|
| 1 | AC3 | ≤0.05 |
| 2 | AC7 | ≤0.05 |
| 3 | EB2 | ≤0.05 |
| 4 | CM6 | ≤0.05 |
| 5 | TR4 | ≤0.05 |
| 6 | SN5 | ≤0.05 |
| 7 | PBC1 | ≤0.05 |
| 8 | PBC3 | ≤0.05 |
| 9 | PBC5 | ≤0.05 |
| 10 | IU2 | ≤0.05 |
| 11 | IU3 | ≤0.05 |
| 12 | IU5 | ≤0.05 |
| 13 | IU6 | ≤0.05 |
| Training Size | Test Size | Optimal Number | Features | RFE Accuracy |
|---|---|---|---|---|
| 90% | 10% | 26 | AC3, AC7, SA3, SA6, EB1, EB2, EB4, CM3, CM6, TR3, TR4, TR5, AT5, AT6, SN3, SN5, PBC1, PBC2, PBC3, PBC4, PBC5, IU1, IU2, IU3, IU5, IU6 | 0.7100 |
| 80% | 20% | 7 | CM6, TR4, PBC3, PBC5, IU2, IU5, IU6 | 0.6436 |
| 70% | 30% | 10 | AC3, CM6, TR4, SN5, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.6375 |
| 60% | 40% | 13 | AC3, AC7, CM6, TR4, AT6, SN5, PBC1, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.6560 |
| 50% | 50% | 8 | CM6, TR4, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.6095 |
| 40% | 60% | 9 | CM6, TR4, SN5, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.6004 |
| 30% | 70% | 8 | CM6, TR4, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.5259 |
| 20% | 80% | 8 | CM6, TR4, PBC3, PBC5, IU2, IU3, IU5, IU6 | 0.4817 |
| 10% | 90% | 3 | TR4, PBC3, IU6 | 0.5299 |
| Number | Feature | p-Value |
|---|---|---|
| 1 | AC3 | 0.0007 |
| 2 | EB1 | 0.0117 |
| 3 | EB2 | 0.0413 |
| 4 | CM6 | 0.0367 |
| 5 | TR4 | 0.0031 |
| 6 | PBC3 | 0.0165 |
| 7 | PBC5 | 0.0001 |
| 8 | IU2 | 0.0005 |
| 9 | IU6 | 0.0018 |
| Feature Selection Method | Optimal Features | Determining Factor |
|---|---|---|
| Filter Method—Correlation | 7—TR3, AT2, SN1, PBC2, PBC5, IU1, IU3 | R cutoff = 0.5 |
| Filter Method—Univariate Selection | 3—IU2, IU5, IU6 | p-value cutoff = 0.05 |
| Wrapper Method—Backward Elimination | 13—AC3, AC7, EB2, CM6, TR4, SN5, PBC1, PBC3, PBC5, IU2, IU3, IU5, IU6 | p-value cutoff = 0.05 |
| Wrapper Method—Recursive Feature Elimination (90:10) | 26—AC3, AC7, SA3, SA6, EB1, EB2, EB4, CM3, CM6, TR3, TR4, TR5, AT5, AT6, SN3, SN5, PBC1, PBC2, PBC3, PBC4, PBC5, IU1, IU2, IU3, IU5, IU6 | RFE accuracy = 0.7100 |
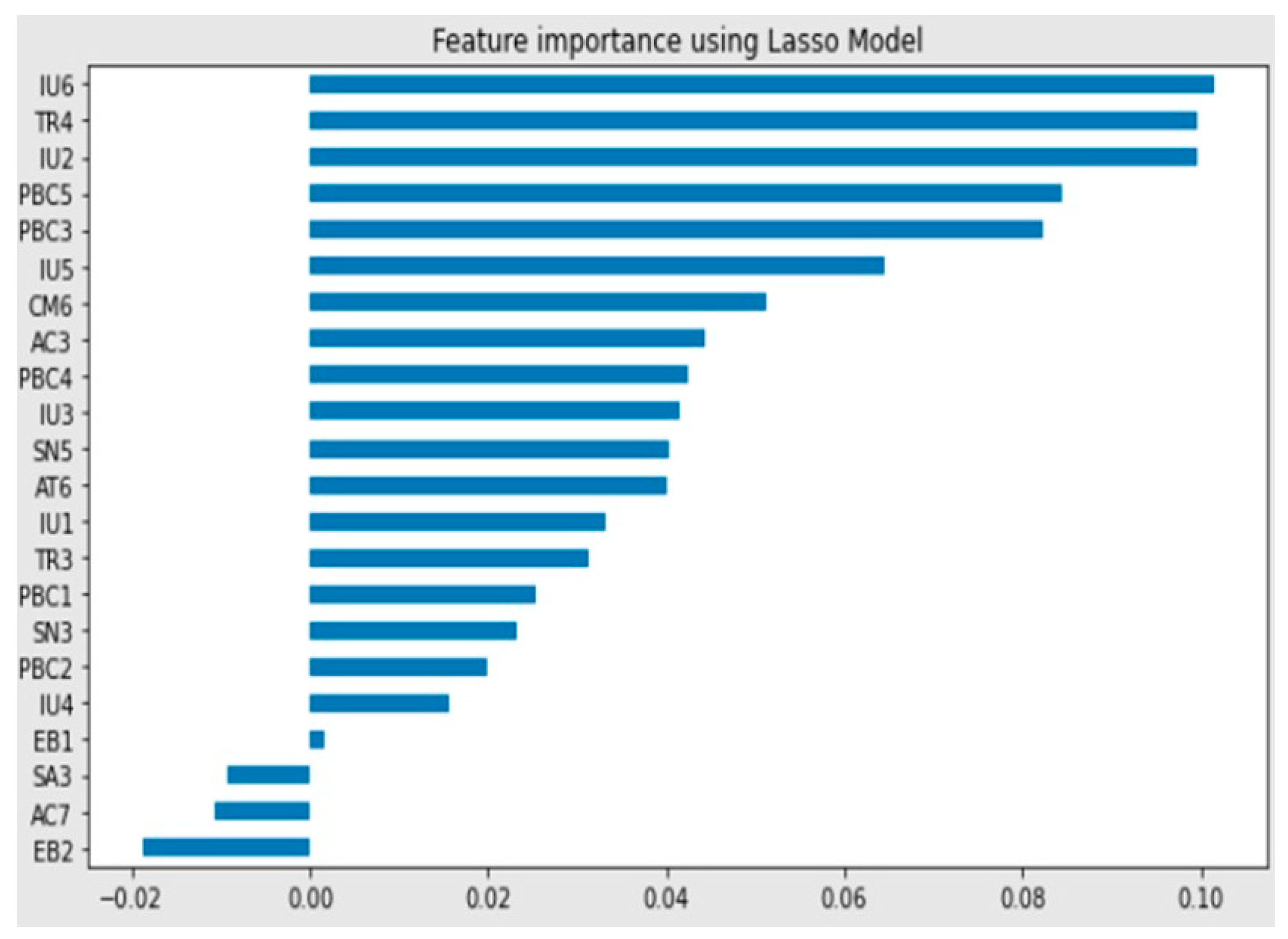
| Embedded Method—LASSO | 22—IU6, TR4, IU2, PBC5, PBC3, IU5, CM6, AC3, PBC4, IU3, SN5, AT6, IU1, TR3, PBC1, SN3, PBC2, IU4, EB1, SA3, AC7, EB2 | Lasso alpha = 0.0218Lasso regression score = 0.7134 |
| Stepwise Regression | 9—AC3, EB1, EB2, CM6, TR4, PBC3, PBC5, IU2, IU6 | p-value cutoff = 0.05 |
| Feature Selection | Advantage | Disadvantage |
|---|---|---|
| Filter method’s correlation | Easy computational approach Applied multicollinearity concept Non-complex data could be maximized better Found significant internal features (TR, AT, SN, PBC, IU) | Resulted in premature convergence Produced low R-values Lacked distinct parameters to support the significance of external features (AC, SA, EB, CM) |
| Filter method’s univariate selection | Simple mathematical process Better used for problems requiring only one significant factor influencing the target variable | Prone to overfitting Could not identify subfeatures redundancy, resulting in a highly concentrated result Highly dependent on the target variable Produced the least number of features with unpromising p-values |
| Wrapper method’s backward elimination | More appropriate for grouped features instead of individual features | Failed to identify p-values of the features individually Attitude and safety features were not found significant Extensive computation |
| Wrapper method’s recursive feature elimination | Applied multiple recursion until the stopping criteria were met Flexible parameters Eliminated weak features first, ensuring that the most important features were retained Produced a balanced feature subset since all features had corresponding subfeatures | Needed a higher training size to generate an optimal number of features coinciding with a good accuracy score Extensive computation |
| Embedded method’s LASSO regression | Could process complex model Determined the relationships between features and target variables in two directions (positive and negative) Produced a balanced feature subset since all features had corresponding subfeatures | Too dependent on the target variable Lacked a fixed alpha value Prone to bias due to unstable parameters |
| Stepwise regression | Uncomplicated computation Enforced both adding and removing of features into/from the model | Too focused on the first optimal model as it could not assess multiple optimal solutions with varying features Lacked distinct parameters to support the significance of SA, AT, and SN |
| Parameter | N | w | c1 | c2 |
|---|---|---|---|---|
| 1 | 20 | 0.6 | 1 | 1 |
| 2 | 30 | 0.6 | 1 | 1 |
| 3 | 40 | 0.6 | 1 | 1 |
| 4 | 20 | 0.9 | 1 | 1 |
| 5 | 30 | 0.9 | 1 | 1 |
| 6 | 40 | 0.9 | 1 | 1 |
| 7 | 20 | 0.6 | 2 | 2 |
| 8 | 30 | 0.6 | 2 | 2 |
| 9 | 40 | 0.6 | 2 | 2 |
| 10 | 20 | 0.9 | 2 | 2 |
| 11 | 30 | 0.9 | 2 | 2 |
| 12 | 40 | 0.9 | 2 | 2 |
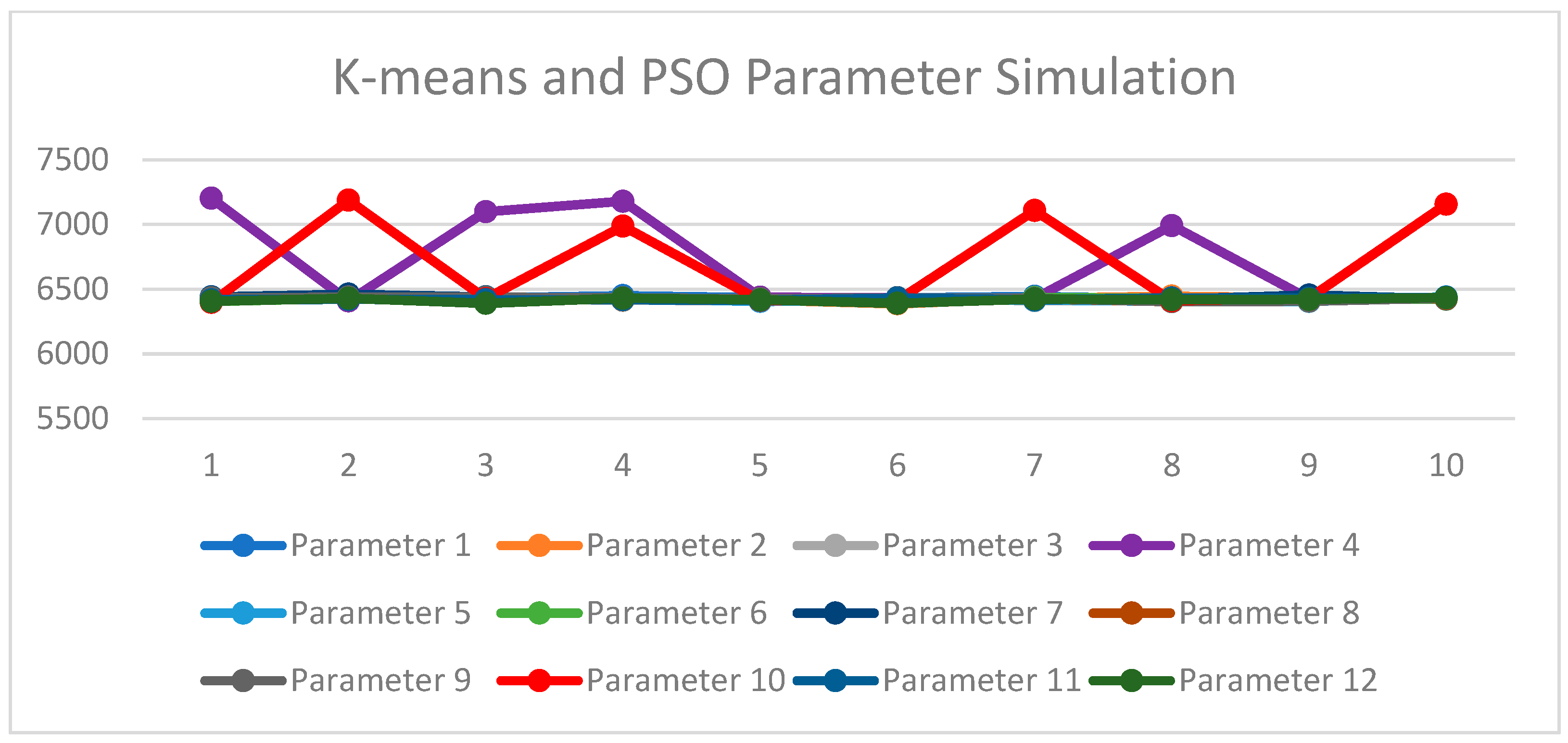
| Gbest Descriptive Statistics | Value | Parameter |
|---|---|---|
| Lowest mean | 6415.86 | 12 |
| Highest mean | 6702.46 | 4 |
| Lowest standard deviation | 7.82 | 11 |
| Highest standard deviation | 362.59 | 10 |
| Minimum among all runs | 6387.30 | 2 |
| Maximum among all runs | 7202.90 | 4 |
| Parameter 12 | Value |
| N | 40 |
| w | 0.9 |
| c1 | 2 |
| c2 | 2 |
| No. of Runs | Gbest Fitness |
| 1 | 6406.10 |
| 2 | 6429.10 |
| 3 | 6389.80 |
| 4 | 6430.40 |
| 5 | 6417.00 |
| 6 | 6389.70 |
| 7 | 6423.80 |
| 8 | 6417.80 |
| 9 | 6420.70 |
| 10 | 6434.20 |
| Mean | 6415.86 |
| Standard Deviation | 15.89 |
| Minimum | 6389.70 |
| Maximum | 6434.20 |
| Algorithm | Advantage | Disadvantage |
| K-means clustering | The simplest machine learning algorithm Could be used for either supervised or non-supervised learning | Weak fundamental due to the presence of random initial centroid Could only process 3 parameters based on the standard model settings Generated very poor SSE mean (7049.09) and standard deviation (126.22) |
| Particle Swarm Optimization (PSO) | Consisted of multiple iterations and would only stop if the termination condition was satisfied Stored multiple optimal solutions with varying gbest fitness values | Lacked initial clustered data, which would prompt randomization Time-consuming trial and error method to find the best parameters Needed human intervention to ensure that premature convergence at pbest was eliminated |
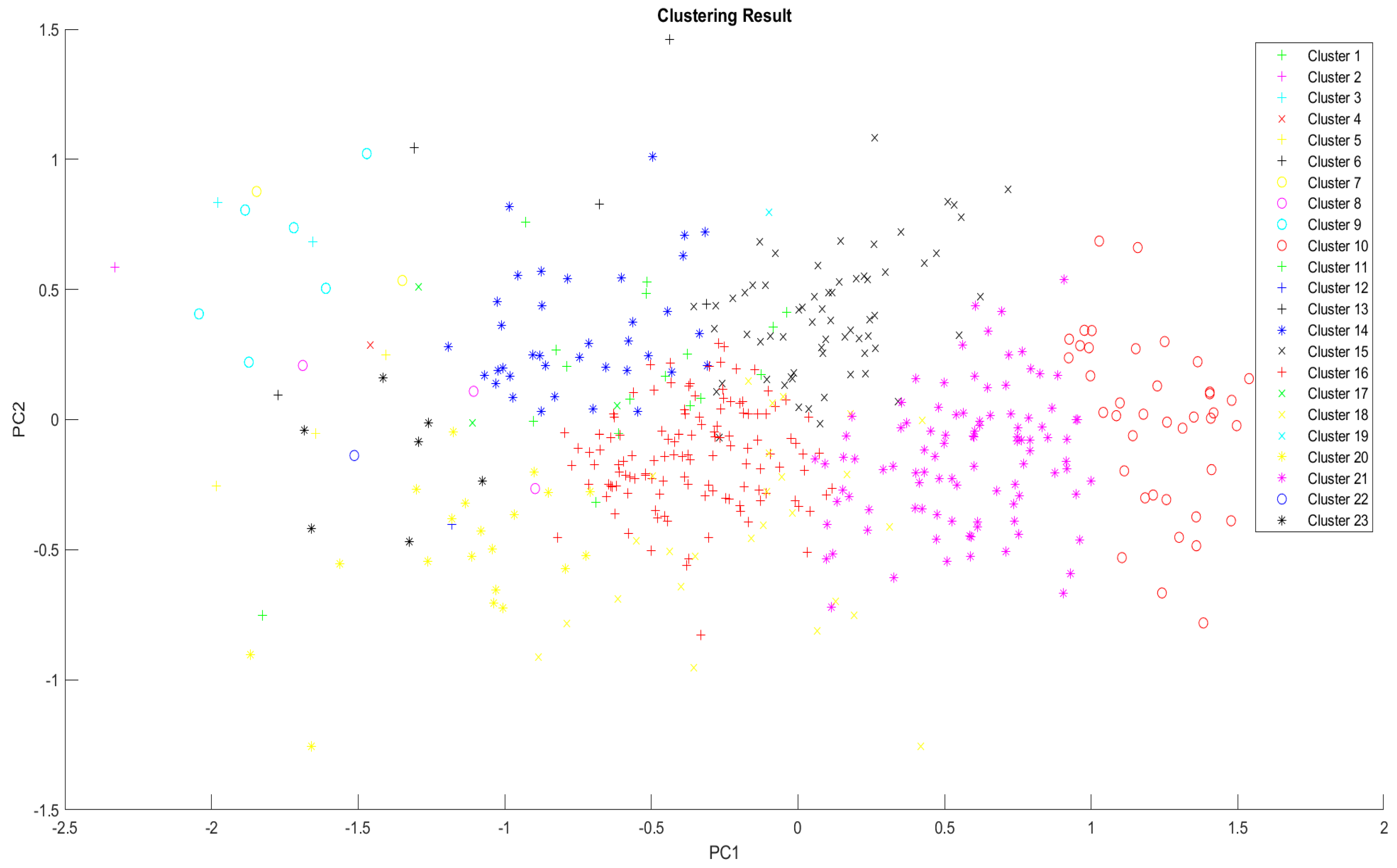
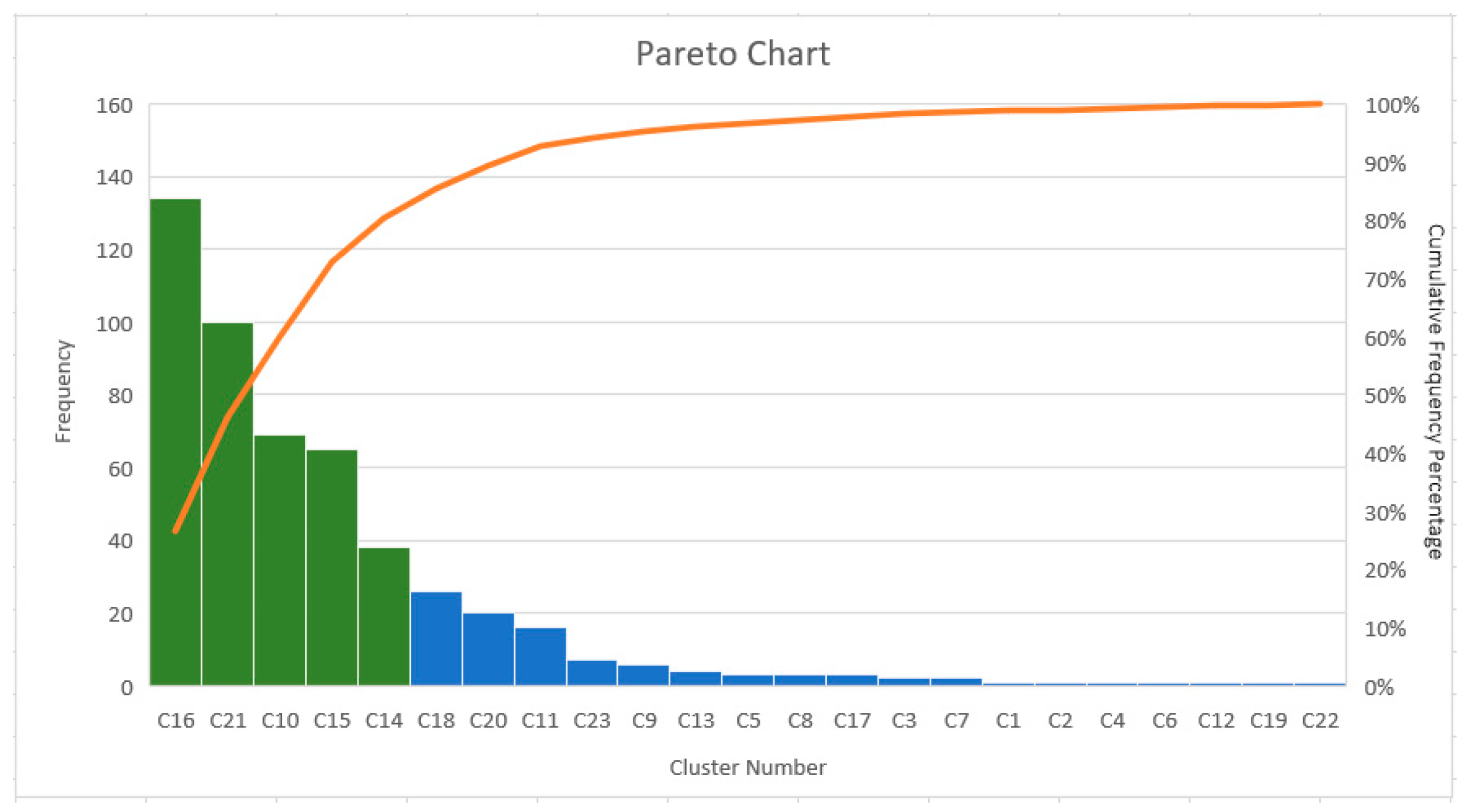
| Combined K-means clustering and PSO | Processed 12 parameters with varying N, w, c1, and c2 A total of 10 parameters yielded consistent gbest results Produced a significantly lower gbest (6415.86) and standard deviation (7.82) compared to the results of K-means Generated 23 cluster groups with feature and demographic similarities among PUB passengers | Computationally extensive due to multiple parameter combinations The combination needed higher N, w, c1, and c2 values |
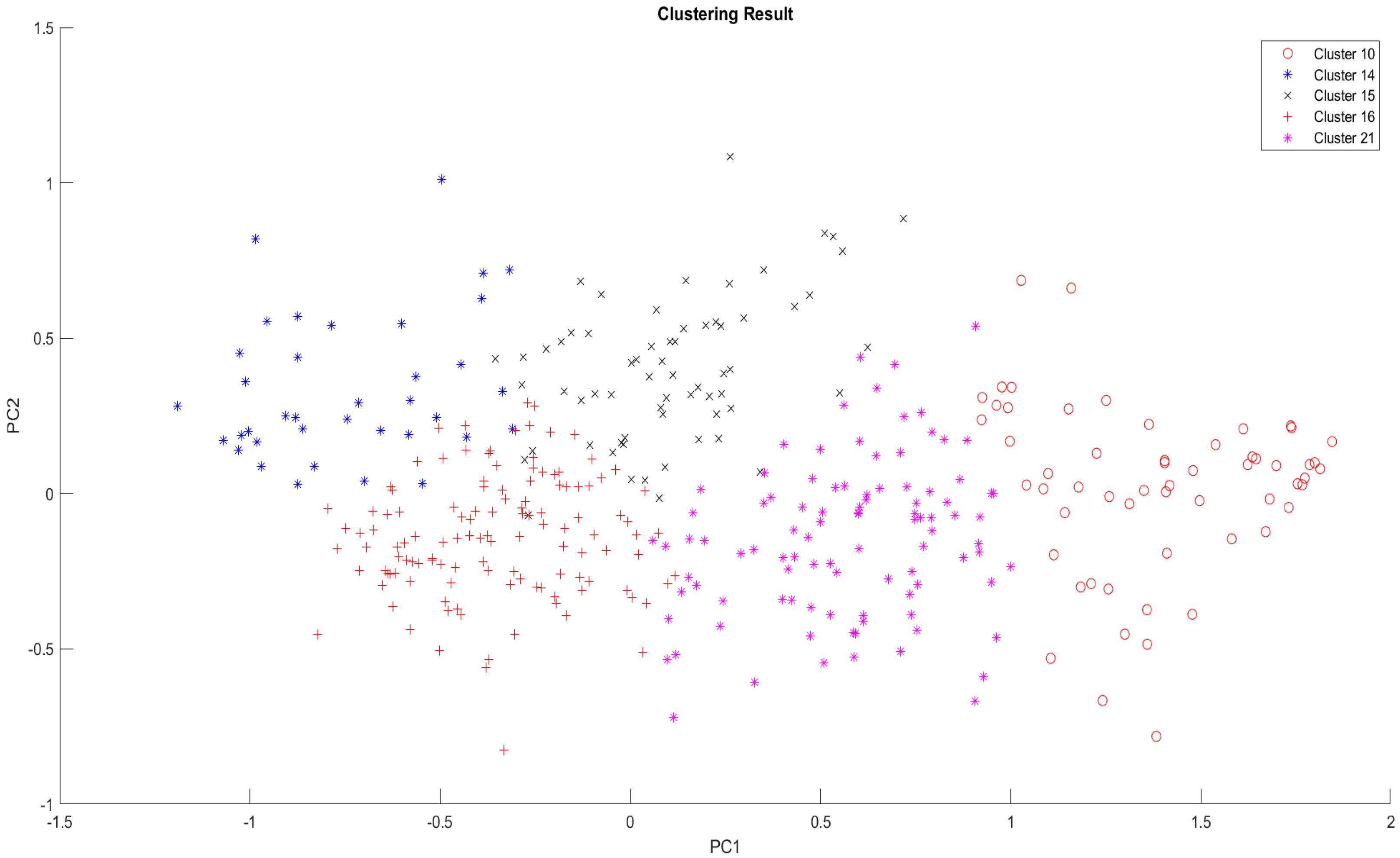
| Cluster | Clustered Demographic | Strategies | Corresponding Features Requiring Improvement |
|---|---|---|---|
| 16 | • All age ranges (≤17 to ≥55 years old) • Dominated by high school levels, college students, and unemployed individuals • Most PUB passengers preferred the least PUB allowances and expenses | The PUB stakeholders must enhance the PUB system services according to all 26 features’ characteristics. There should be adequate numbers of PUB on the road, especially in the daytime. The bus stops should have a reasonable distance. Crimes must not be feasible inside the bus; whereby, drivers/operators shall inspect the belongings of passengers or the PUB companies can install metal detectors. PUB fares should be affordable. The drivers and operators shall ensure that COVID-19-mandated protocols are implemented and strictly followed. Furthermore, the PUB stakeholders should improve the public-sharing comfortability experience by ensuring that PUBs are reliable; thus, regular PUB maintenance shall be checked by the PUB companies, drivers, and operators. | AC3, AC7, SA3, SA6, EB1, EB2, EB4, CM3, CM6, TR3, TR4, TR5, AT5, AT6, SN3, SN5, PBC1, PBC2, PBC3, PBC4, PBC5, IU1, IU2, IU3, IU5, and IU6 |
| 21 | • ≤17 to 54 years old • Dominated by college students, bachelor’s degree holders, and unemployed individuals • Most PUB passengers preferred the least PUB allowances and expenses | The PUB stakeholders must improve the public-sharing comfortability experience and ensure that the PUB fare increase is mitigated. | SA6 and EB2 |
| 10 | • ≤17 to 44 years old and ≥55 years old • Dominated by high school levels, college students, and unemployed individuals • Most PUB passengers preferred the least PUB allowances and expenses | Since most passengers extremely agreed with the services provided by 26 features, there are no improvements needed. Instead, the PUB stakeholders must maintain the current PUB system. | N/A |
| 15 | • ≤17 years old to 44 years old • Dominated by college students, high school students, and full-time employees • Most PUB passengers preferred the least PUB allowances and expenses | The PUB stakeholders must ensure that crimes are not feasible inside the bus. PUB fares must be maintained at the lowest cost. Passengers should feel comfort and convenience when riding the PUB despite the pandemic. | SA3, EB2, TR5, AT5, AT6, SN3, SN5, PBC2, PBC3, IU1, IU2, IU3, IU5, and IU6 |
| 14 | • ≤17 years old to 44 years old • Dominated by bachelor’s degree holders, college students, and full-time employees • Most PUB passengers preferred the least, high, and mid (in chronological order) PUB allowances | The PUB stakeholders must ensure that bus stops have reasonable distance, crimes are not feasible inside the bus, and PUB fares are affordable. They should also improve the public-sharing comfortability experience by ensuring that PUBs are reliable. Moreover, the drivers and operators shall ensure that COVID-19-mandated protocols are implemented and strictly followed. | AC7, SA3, SA6, EB1, CM3, CM6, TR3, TR5, AT5, AT6, SN3, SN5, PBC2, PBC3, IU1, IU2, IU3, IU5, and IU6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cahigas, M.M.L.; Zulvia, F.E.; Ong, A.K.S.; Prasetyo, Y.T. A Comprehensive Analysis of Clustering Public Utility Bus Passenger’s Behavior during the COVID-19 Pandemic: Utilization of Machine Learning with Metaheuristic Algorithm. Sustainability 2023, 15, 7410. https://doi.org/10.3390/su15097410
Cahigas MML, Zulvia FE, Ong AKS, Prasetyo YT. A Comprehensive Analysis of Clustering Public Utility Bus Passenger’s Behavior during the COVID-19 Pandemic: Utilization of Machine Learning with Metaheuristic Algorithm. Sustainability. 2023; 15(9):7410. https://doi.org/10.3390/su15097410
Chicago/Turabian StyleCahigas, Maela Madel L., Ferani E. Zulvia, Ardvin Kester S. Ong, and Yogi Tri Prasetyo. 2023. "A Comprehensive Analysis of Clustering Public Utility Bus Passenger’s Behavior during the COVID-19 Pandemic: Utilization of Machine Learning with Metaheuristic Algorithm" Sustainability 15, no. 9: 7410. https://doi.org/10.3390/su15097410