
Identifying and Characterizing the Propagation Scale of COVID-19 Situational Information on Twitter: A Hybrid Text Analytic Approach

 , , , , and
, , , , and 
Abstract
:1. Introduction
- 1.
- RQ1. How to identify and classify the situational information on Twitter?
- 2.
- RQ2. What will be the features with which to predict the propagation scale of these types of information and what will be the predictability nature of those features?
- 3.
- RQ3. How the results of the propagation scale of situational information can assist the relevant authorities in decision making?
- 1.
- The dataset is collected and the situational information identified from COVID-19 Twitter data.
- 2.
- A novel framework is proposed combining machine learning and LIWC lexicon to characterize the propagation scale of situational information.
- 3.
- Each and every aspect of the framework is analyzed with different evaluations of the information scale in the Results and Discussion section.
2. Related Work
2.1. Social Media in Situational Information
2.2. Twitter during Natural Disasters
2.3. Propagation of Crisis Information in Social Media
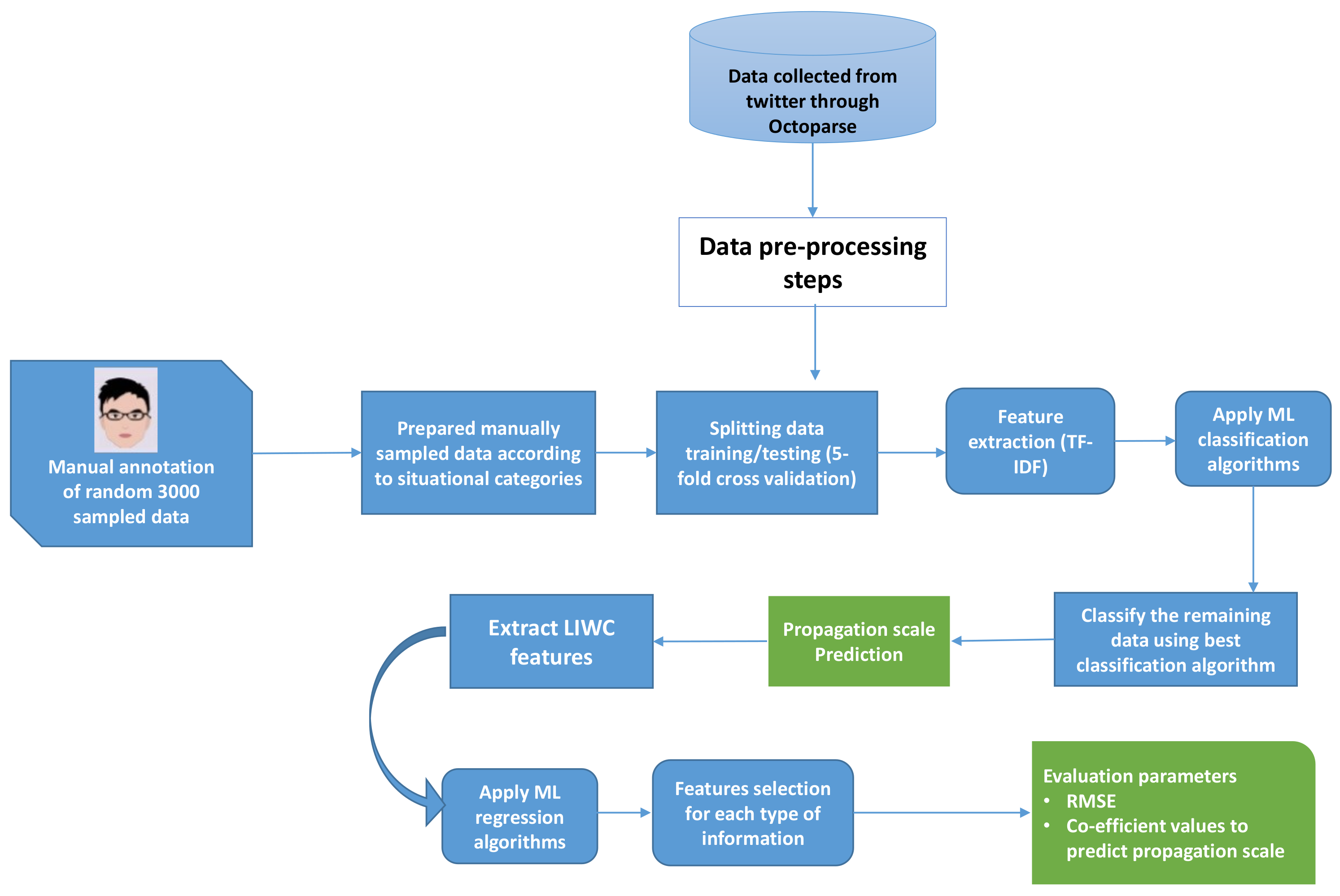
3. Proposed Framework
- 1.
- Collecting the COVID-19-related datasets consisting of tweets.
- 2.
- Applying pre-processing steps to remove noisy data.
- 3.
- Manually annotating the random 3000 tweets by different annotators according to different situational information categories.
- 4.
- Feature extraction through TF-IDF, as machine learning classifiers need data in the form of feature vectors.
- 5.
- Applying supervised machine learning classifiers and obtaining accuracy scores to check the classification performance of different classifiers.
- 6.
- Choosing the classifiers with the highest classification accuracy score to label the remaining data.
- 7.
- Extracting content, user-related linguistic and cognitive features to predict the propagation scale.
- 8.
- Applying Machine learning regression algorithms to predict the retweeted amount of every situational information separately.
- 9.
- Presenting the results to analyze the propagation scale through ML regression algorithms evaluation parameters such as co-efficient values of all features.
3.1. Data Collection and Description
3.2. Data Pre-Processing
3.2.1. Tokenization and Lemmatization
3.2.2. TF-IDF (Term Frequency—Inverse Document Frequency)
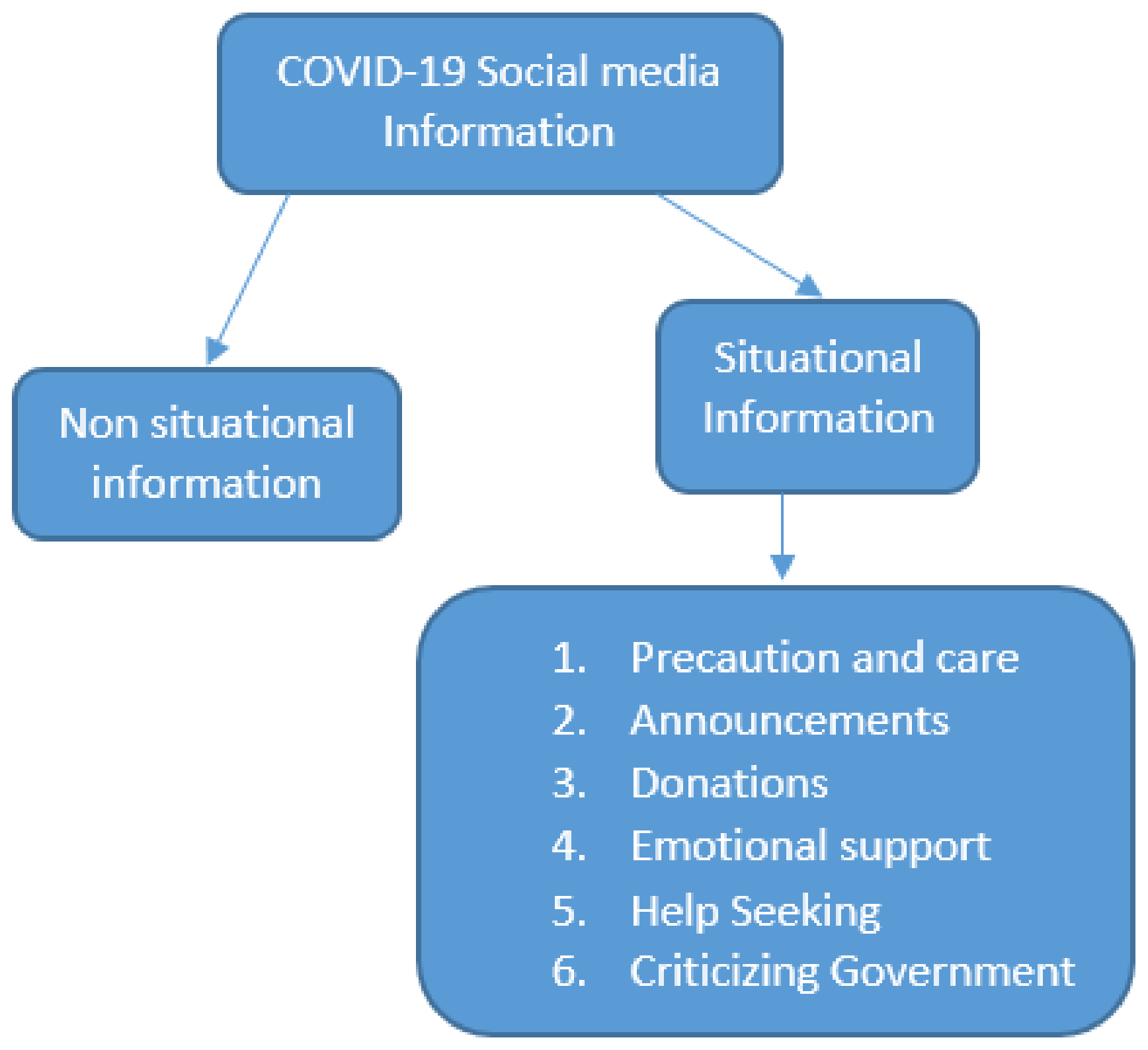
3.2.3. Annotation and Classification of Situational Information
3.2.4. Machine Learning Classifiers
4. Situational Information Propagation Level Prediction
- 1.
- Emotional-related features: effect, positive emotion (posemo), negative emotion (negemo), anxiety (anx), anger and sadness (sad) words in the posts.
- 2.
- Perception type features: perception, seeing, hearing and feeling in the posts.
- 3.
- Affiliation type features: driving, affiliation, achievements, power, rewards and risk in the posts.
- 4.
- Cognitive processes features: certainty(certain) and differentiation(diff).
- 5.
- User-related features: if users are verified or not, followers (log) amount, following (log) amount and NearState.
- 6.
- Content-related features: length of the post (word count), number of retweets (log) and likes on the posts.
5. Discussion
6. Implications
6.1. Theoretical Implications
6.2. Practical Implications
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thakur, N.; Han, C.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Ullah, M.A.; Marium, S.M.; Begum, S.A.; Dipa, N.S. An algorithm and method for sentiment analysis using the text and emoticon. ICT Express 2020, 6, 357–360. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Mehmood, A.; Ullah, S.; On, B.; Aslam, W.; Choi, G.S. COVID-19 Future Forecasting Using Supervised Machine Learning Models. IEEE Access 2020, 8, 101489–101499. [Google Scholar] [CrossRef]
- Adel, M.; Kotb, A.; Farag, O.; Darweesh, M.S.; Mostafa, H. Breast Cancer Diagnosis Using Image Processing and Machine Learning for Elastography Images. In Proceedings of the 2019 8th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Kisi, O.; Cimen, M. Precipitation Forecasting by Using Wavelet-Support Vector Machine Conjunction Model. Eng. Appl. Artif. Intell. 2012, 25, 783–792. [Google Scholar] [CrossRef]
- Wu, J.T.; Leung, K.; Leung, G.M. Nowcasting and forecasting the potential domestic and international spread of the 2019-nCoV outbreak originating in Wuhan, China: A modelling study. Lancet 2020, 395, 689–697. [Google Scholar] [CrossRef] [Green Version]
- Burnap, P.; Williams, M.L.; Sloan, L.; Rana, O.; Housley, W.; Edwards, A.; Knight, V.; Procter, R.; Voss, A. Tweeting the terror: Modelling the social media reaction to the Woolwich terrorist attack. Soc. Netw. Anal. Min. 2014, 4, 206. [Google Scholar] [CrossRef] [Green Version]
- Vieweg, S.; Hughes, A.L.; Starbird, K.; Palen, L. Microblogging during Two Natural Hazards Events: What Twitter May Contribute to Situational Awareness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1079–1088. [Google Scholar] [CrossRef]
- Jarwar, M.A.; Abbasi, R.A.; Mushtaq, M.; Maqbool, O.; Aljohani, N.R.; Daud, A.; Alowibdi, J.S.; Cano, J.R.; García, S.; Chong, I. CommuniMents: A framework for detecting community based sentiments for events. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2017, 13, 87–108. [Google Scholar] [CrossRef]
- Martínez-Rojas, M.; del Carmen Pardo-Ferreira, M.; Rubio-Romero, J.C. Twitter as a tool for the management and analysis of emergency situations: A systematic literature review. Int. J. Inf. Manag. 2018, 43, 196–208. [Google Scholar] [CrossRef]
- Mukkamala, A.; Beck, R. The Role of Social Media for Collective Behavior Development in Response to Natural Disasters. Research Papers. AIS e Library. 2018. p. 109. Available online: https://aisel.aisnet.org/ecis2018_rp/109 (accessed on 20 April 2020).
- Yan, L.L.; Pedraza-Martinez, A.J. Social Media for Disaster Management: Operational Value of the Social Conversation. Prod. Oper. Manag. 2019, 28, 2514–2532. [Google Scholar] [CrossRef]
- Rudra, K.; Ghosh, S.; Ganguly, N.; Goyal, P.; Ghosh, S. Extracting Situational Information from Microblogs during Disaster Events: A Classification-Summarization Approach. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management CIKM ’15, Melbourne, Australia, 18–23 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 583–592. [Google Scholar] [CrossRef]
- Vieweg, S.E. Situational Awareness in Mass Emergency: A Behavioral and Linguistic Analysis of Microblogged Communications. Ph.D. Thesis, University of Colorado, Boulder, CO, USA, 2012. [Google Scholar]
- Li, L.; Zhang, Q.; Wang, X.; Zhang, J.; Wang, T.; Gao, T.; Duan, W.; Tsoi, K.K.; Wang, F. Characterizing the Propagation of Situational Information in Social Media During COVID-19 Epidemic: A Case Study on Weibo. IEEE Trans. Comput. Soc. Syst. 2020, 7, 556–562. [Google Scholar] [CrossRef]
- Li, L.; Zhang, Q.; Tian, J.; Wang, H. Characterizing information propagation patterns in emergencies: A case study with Yiliang Earthquake. Int. J. Inf. Manag. 2018, 38, 34–41. [Google Scholar] [CrossRef]
- Zahra, K.; Imran, M.; Ostermann, F.O. Automatic identification of eyewitness messages on twitter during disasters. Inf. Process. Manag. 2020, 57, 102107. [Google Scholar] [CrossRef]
- Alkouz, B.; Aghbari, Z.A.; Abawajy, J.H. Tweetluenza: Predicting flu trends from twitter data. Big Data Min. Anal. 2019, 2, 273–287. [Google Scholar] [CrossRef] [Green Version]
- Ruz, G.A.; Henríquez, P.A.; Mascareño, A. Sentiment analysis of Twitter data during critical events through Bayesian networks classifiers. Future Gener. Comput. Syst. 2020, 106, 92–104. [Google Scholar] [CrossRef]
- Kaufhold, M.A.; Bayer, M.; Reuter, C. Rapid relevance classification of social media posts in disasters and emergencies: A system and evaluation featuring active, incremental and online learning. Inf. Process. Manag. 2020, 57, 102132. [Google Scholar] [CrossRef]
- Saleem, H.M.; Xu, Y.; Ruths, D. Novel Situational Information in Mass Emergencies: What does Twitter Provide? Procedia Eng. 2014, 78, 155–164. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Extracting information nuggets from disaster—Related messages in social media. In Proceedings of the ISCRAM 10th International Conference on Information Systems for Crisis Response and Management, Baden-Baden, Germany, 12–15 May 2013; Karlsruher Institut fur Technologie: Karlsruhe, Germany, 2013; pp. 791–801. [Google Scholar]
- Fan, C.; Jiang, Y.; Yang, Y.; Zhang, C.; Mostafavi, A. Crowd or Hubs: Information diffusion patterns in online social networks in disasters. Int. J. Disaster Risk Reduct. 2020, 46, 101498. [Google Scholar] [CrossRef]
- Takahashi, B.; Tandoc, E.C.; Carmichael, C. Communicating on Twitter during a disaster: An analysis of tweets during Typhoon Haiyan in the Philippines. Comput. Hum. Behav. 2015, 50, 392–398. [Google Scholar] [CrossRef]
- Bhuvana, N.; Arul Aram, I. Facebook and Whatsapp as disaster management tools during the Chennai (India) floods of 2015. Int. J. Disaster Risk Reduct. 2019, 39, 101135. [Google Scholar] [CrossRef]
- Karami, A.; Shah, V.; Vaezi, R.; Bansal, A. Twitter speaks: A case of national disaster situational awareness. J. Inf. Sci. 2020, 46, 313–324. [Google Scholar] [CrossRef] [Green Version]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. Can. J. Emerg. Med. 2020, 22, 418–421. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Luo, J.; Li, C.; Wang, X.; Zhao, Z. Detecting and Analyzing Influenza Epidemics with Social Media in China. In Advances in Knowledge Discovery and Data Mining; Tseng, V.S., Ho, T.B., Zhou, Z.H., Chen, A.L.P., Kao, H.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 90–101. [Google Scholar]
- Vera-Burgos, C.M.; Griffin Padgett, D.R. Using Twitter for crisis communications in a natural disaster: Hurricane Harvey. Heliyon 2020, 6, e04804. [Google Scholar] [CrossRef] [PubMed]
- Eligüzel, N.; Çetinkaya, C.; Dereli, T. Comparison of different machine learning techniques on location extraction by utilizing geo-tagged tweets: A case study. Adv. Eng. Inform. 2020, 46, 101151. [Google Scholar] [CrossRef]
- Kagashe, I.; Yan, Z.; Suheryani, I. Enhancing Seasonal Influenza Surveillance: Topic Analysis of Widely Used Medicinal Drugs Using Twitter Data. J. Med. Internet Res. 2017, 19, e315. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Agrawal, A.; Choudhary, A. Forecasting Influenza Levels Using Real-Time Social Media Streams. In Proceedings of the IEEE International Conference on Healthcare Informatics (ICHI), Park City, UT, USA, 23–26 August 2017; pp. 409–414. [Google Scholar] [CrossRef]
- Jenhani, F.; Gouider, M.S.; Said, L.B. Hybrid System for Information Extraction from Social Media Text: Drug Abuse Case Study. Procedia Comput. Sci. 2019, 159, 688–697. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef]
- Hagen, L.; Neely, S.; Scharf, R.; Keller, T.E. Social Media Use for Crisis and Emergency Risk Communications During the Zika Health Crisis. Digit. Gov. Res. Pract. 2020, 1. [Google Scholar] [CrossRef]
- Romascanu, A.; Ker, H.; Sieber, R.; Greenidge, S.; Lumley, S.; Bush, D.; Morgan, S.; Zhao, R.; Brunila, M. Using deep learning and social network analysis to understand and manage extreme flooding. J. Contingencies Crisis Manag. 2020, 28, 251–261. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. A deep multi-modal neural network for informative Twitter content classification during emergencies. Ann. Oper. Res. 2020, 1–32. [Google Scholar] [CrossRef]
- Madichetty, S.; Sridevi, M. A Neural-Based Approach for Detecting the Situational Information From Twitter During Disaster. IEEE Trans. Comput. Soc. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Dong, R.; Li, L.; Zhang, Q.; Cai, G. Information Diffusion on Social Media During Natural Disasters. IEEE Trans. Comput. Soc. Syst. 2018, 5, 265–276. [Google Scholar] [CrossRef]
- Tsur, O.; Rappoport, A. What’s in a hashtag? Content based prediction of the spread of ideas in microblogging communities. In In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 643–652. [Google Scholar]
- Hofer, M.; Aubert, V. Perceived bridging and bonding social capital on Twitter: Differentiating between followers and followees. Comput. Hum. Behav. 2013, 29, 2134–2142. [Google Scholar] [CrossRef]
- Stern, M.J.; Adams, A.E.; Elsasser, S. Digital inequality and place: The effects of technological diffusion on Internet proficiency and usage across rural, suburban, and urban counties. Sociol. Inq. 2009, 79, 391–417. [Google Scholar] [CrossRef]
- Lima, A.C.E.; de Castro, L.N.; Corchado, J.M. A polarity analysis framework for Twitter messages. Appl. Math. Comput. 2015, 270, 756–767. [Google Scholar] [CrossRef]
- Kaur, S.; Kaul, P.; Zadeh, P.M. Monitoring the Dynamics of Emotions during COVID-19 Using Twitter Data. Procedia Comput. Sci. 2020, 177, 423–430. [Google Scholar] [CrossRef]
- Chen, S.; Mao, J.; Li, G.; Ma, C.; Cao, Y. Uncovering sentiment and retweet patterns of disaster-related tweets from a spatiotemporal perspective—A case study of Hurricane Harvey. Telemat. Inform. 2020, 47, 101326. [Google Scholar] [CrossRef]
- Fan, C.; Esparza, M.; Dargin, J.; Wu, F.; Oztekin, B.; Mostafavi, A. Spatial biases in crowdsourced data: Social media content attention concentrates on populous areas in disasters. Comput. Environ. Urban Syst. 2020, 83, 101514. [Google Scholar] [CrossRef]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, K.; Tutubalina, E.; Chowell, G. A large-scale COVID-19 Twitter chatter dataset for open scientific research—An international collaboration. arXiv 2020, arXiv:2004.03688. [Google Scholar]
- Chen, E.; Lerman, K.; Ferrara, E. Tracking social media discourse about the covid-19 pandemic: Development of a public coronavirus twitter data set. JMIR Public Health Surveill. 2020, 6, e19273. [Google Scholar] [CrossRef]
- Bilal, M.; Israr, H.; Shahid, M.; Khan, A. Sentiment classification of Roman-Urdu opinions using Naïve Bayesian, Decision Tree and KNN classification techniques. J. King Saud Univ. Comput. Inf. Sci. 2016, 28, 330–344. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Jin, R.; Zhou, Z.H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Elhadad, M.K.; Badran, K.M.; Salama, G.I. A novel approach for ontology-based feature vector generation for web text document classification. Int. J. Softw. Innov. (IJSI) 2018, 6, 1–10. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic Inquiry and Word Count: LIWC 2001; Lawrence Erlbaum Association: Mahway, NJ, USA, 2001; Volume 71. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Li, L.; Wang, Z.; Zhang, Q.; Wen, H. Effect of anger, anxiety, and sadness on the propagation scale of social media posts after natural disasters. Inf. Process. Manag. 2020, 57, 102313. [Google Scholar] [CrossRef]
- Suh, B.; Hong, L.; Pirolli, P.; Chi, E.H. Want to be Retweeted? Large Scale Analytics on Factors Impacting Retweet in Twitter Network. In In Proceedings of the 2010 IEEE Second International Conference on Social Computing, Minneapolis, MN, USA, 20–22 August 2010; pp. 177–184. [Google Scholar] [CrossRef]
- Li, C.; Yi, J.; Lv, Y.; Duan, P. A hybrid learning method for the data-driven design of linguistic dynamic systems. IEEE/CAA J. Autom. Sin. 2019, 6, 1487–1498. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Names and Definitions | Manual Label | Counts |
| Precautions and care: precautions from the public healthcare authorities to explain the pace of the epidemic, such the need to pay attention to different aspects of the containment measure, such as going out much less, using sanitizers to wash hands, wearing masks in public and responding to the government announcements. | 0 | 199 |
| Announcements or Measures: pandemic announcements such as hospital conditions, the number of cases (recovered, infected or dead), measures taken by health departments, medical equipment reserves and the city and state wise tally of cases. | 1 | 946 |
| Donated money, goods or services: donations from governments, government-relevant authorities who want to donate goods, money, or services for pandemic prevention and control, healthcare NGO- and health- related volunteer services announcements of donations are also include in this category. | 2 | 63 |
| Emotional support to victims: shows of sympathy by public medical teams and health organizations who are supporting people in the US. | 3 | 199 |
| Help Seeking: (a) medical institutions, public health care authorities, individuals, etc. seeking support such as demanding human resources in the form of medical workers and individuals seeking medical aid kits, virus test kits etc. (b) Patients want emotional support such as those seeking comfort and who express depression, etc. | 4 | 279 |
| Criticizing authorities: criticizing or questioning the government on their performance in handling the pandemic so far, questioning the government’s initiatives or criticizing members of the public who mislead others such as blind supporters of specific political parties, etc. | 5 | 763 |
| Non Situational Information: information that does not fall into any of the above stated and defined categories is classified as non situational information. | 6 | 551 |
| Name of Algorithm | Mean Accuracy | F1 | Precision | Recall |
| SVM | 67% | 69% | 69% | 66% |
| SVM (linear kernel) | 70% | 69% | 71% | 68% |
| SVM (radial basis kernel) | 77% | 76% | 77% | 73% |
| SVM (Sigmoid Kernel) | 57% | 59% | 62% | 59% |
| Random Forest | 56% | 61% | 63% | 60% |
| Multinomial Naïve Bayes | 55% | 57% | 60% | 56% |
| K-nearest neighbor | 54% | 56% | 59% | 55% |
| Logistic Regression Classifier | 56% | 57% | 60% | 55% |
| Types | Tweets Frequency | Verified Frequency | Follower Frequency | Following Frequency | RT Frequency | Like Frequency |
| Type 0: Precaution and Care | 6120 | 610 (9.96%) | 9,104,201 (2266) | 6.131831e +08 (190,183. 549) | 139,431 (51.955) | 440,375 (167) |
| Type 1: Announcements or Measures | 33,830 | 4660 (12.1%) | 79,371,572 (5171) | 6.418501e +09 (262,889 0.172) | 1,701,310 (103.765) | 6,172,700 (313) |
| Type 2: Donations | 4720 | 535 (11.33%) | 7,316,652 (4159) | 5.059554e +08 (159,384 0.823) | 187,212 (87.31) | 631,910 (267) |
| Type 3: Emotional support | 4120 | 459 (11.14%) | 4,549,173 (3863) | 7.197526e +08 (390,513 0.864) | 257,310 (127.86) | 1,071,331 (497) |
| Type 4: Help Seeking | 2217 | 229 (10.33%) | 3,325,963 (4221) | 2.318969e +03 (170,904 0.651) | 247,310 (213.146) | 968,137 (771) |
| Type 5: Criticizing the Government | 7561 | 529 (7.00%) | 9,833,219 (3746) | 6.758479e +03 (180,936. 129) | 210,221 (170.531) | 1,193,404 (278) |
| Type 6: Non Situational Information | 9763 | 1397 (14.1%) | 13,713,097 (3831) | 12.938331e +08 (260,121. 006043) | 893,071 (177.34) | 2,479,301 (810) |
| Features | Type 0 | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 |
| affect | 4.91 | 3.54 | 3.72 | 3.67 | 4.48 | 4.78 |
| posemo | 1.88 | 1.8 | 1.94 | 1.81 | 3.04 | 1.92 |
| negemo | 1.94 | 1.72 | 1.84 | 1.91 | 2.89 | 3.05 |
| anx | 0.3 | 0.26 | 0.27 | 0.26 | 0.28 | 0.31 |
| anger | 0.6 | 0.6 | 0.59 | 0.6 | 0.67 | 0.77 |
| sad | 0.34 | 0.31 | 0.35 | 0.33 | 0.38 | 0.34 |
| certain | 1.03 | 0.99 | 1.08 | 0.94 | 1.04 | 0.99 |
| differ | 1.58 | 1.56 | 1.58 | 1.7 | 1.93 | 1.69 |
| percept | 1.34 | 1.38 | 1.34 | 1.34 | 1.21 | 1.43 |
| see | 0.58 | 0.64 | 0.66 | 0.59 | 0.56 | 0.69 |
| hear | 0.5 | 0.48 | 0.45 | 0.49 | 0.41 | 0.51 |
| feel | 0.21 | 0.19 | 0.15 | 0.21 | 0.18 | 0.17 |
| affiliation | 1.4 | 1.39 | 1.46 | 1.5 | 1.72 | 1.56 |
| achieve | 1.09 | 1.06 | 1.26 | 1.22 | 1.16 | 1.04 |
| power | 2.67 | 2.53 | 2.64 | 2.7 | 2.66 | 2.86 |
| reward | 0.84 | 0.78 | 0.73 | 0.77 | 0.82 | 0.8 |
| risk | 0.74 | 0.68 | 0.73 | 0.69 | 0.78 | 0.73 |
| drives | 6.14 | 5.82 | 6.07 | 6.16 | 6.47 | 6.29 |
| Likes | 7.13 | 5.43 | 5.04 | 7.73 | 2.46 | 7.31 |
| Verified | 0.123 | 0.33 | 0.210 | 0.188 | 0.18 | 0.16 |
| Followers (Log) | 11.837 | 9.621 | 10.765 | 10.213 | 10.341 | 9.321 |
| Following (Log) | 14.312 | 16.21 | 14.212 | 13.211 | 15.122 | 16.623 |
| Near State | 0.039 | 0.036 | 0.049 | 0.036 | 0.049 | 0.058 |
| length | 107.3 | 102.12 | 83.2 | 69.53 | 78.2 | 83.4 |
| RMSE | Type 0 | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 |
| Linear Regression | 6.85 | 3.87 | 2.20 | 6.29 | 1.86 | 1.56 |
| Negative Binomial Regression | 0.62 | 0.67 | 0.80 | 0.74 | 0.77 | 0.72 |
| Features | Type 0 | Type 1 | Type 2 | Type 3 | Type 4 | Type 5 |
| affect | −6.939 | −3.608 | ||||
| posemo | 0.11 | 1.943 | 1.776 | 1.11 | ||
| negemo | −0.11 | −2.842 | 2.63 | |||
| anx | −2.082 | −1.11 | ||||
| anger | −1.249 | −1.804 | −2.35 | |||
| sad | 2.350 | |||||
| certain | 2.673 | −1.388 | ||||
| differ | −2.984 | 0.776 | ||||
| percept | 0.318 | 0.163 | ||||
| see | −4.441 | −1.11 | −1.11 | 1.44 | ||
| hear | −3.331 | 1.99 | ||||
| feel | −1.943 | −1.11 | 1.44 | |||
| affiliation | 1.527 | −3.469 | −1.18 | |||
| achieve | −1.35 | −4.09 | ||||
| power | 1.55 | |||||
| reward | −3.469 | |||||
| risk | −1.735 | −4.30 | ||||
| drives | −1.665 | 1.457 | 1.41 | |||
| Likes (Log) | 2.43 | 2.123 | 3.668 | 1.1 | 3.571 | 1.107 |
| Verified (Log) | −1.443 | 2.789 | −1.499 | 6.27 | 2.054 | −5.829 |
| Followers (Log) | 0.34 | 0.07 | 0.72 | 0.51 | 0.07 | 0.001 |
| Following (Log) | 2.00 | 2.00 | 2.000 | |||
| Near State | 0.28 | 0.48 | 0.49 | 0.27 | 0.22 | |
| length | 2.041 | 9.481 | 2.12 | 4.31 | 9.853 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wahid, J.A.; Shi, L.; Gao, Y.; Yang, B.; Tao, Y.; Wei, L.; Hussain, S. Identifying and Characterizing the Propagation Scale of COVID-19 Situational Information on Twitter: A Hybrid Text Analytic Approach. Appl. Sci. 2021, 11, 6526. https://doi.org/10.3390/app11146526
Wahid JA, Shi L, Gao Y, Yang B, Tao Y, Wei L, Hussain S. Identifying and Characterizing the Propagation Scale of COVID-19 Situational Information on Twitter: A Hybrid Text Analytic Approach. Applied Sciences. 2021; 11(14):6526. https://doi.org/10.3390/app11146526
Chicago/Turabian StyleWahid, Junaid Abdul, Lei Shi, Yufei Gao, Bei Yang, Yongcai Tao, Lin Wei, and Shabir Hussain. 2021. "Identifying and Characterizing the Propagation Scale of COVID-19 Situational Information on Twitter: A Hybrid Text Analytic Approach" Applied Sciences 11, no. 14: 6526. https://doi.org/10.3390/app11146526