
Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models

 and
and
Abstract
:1. Introduction
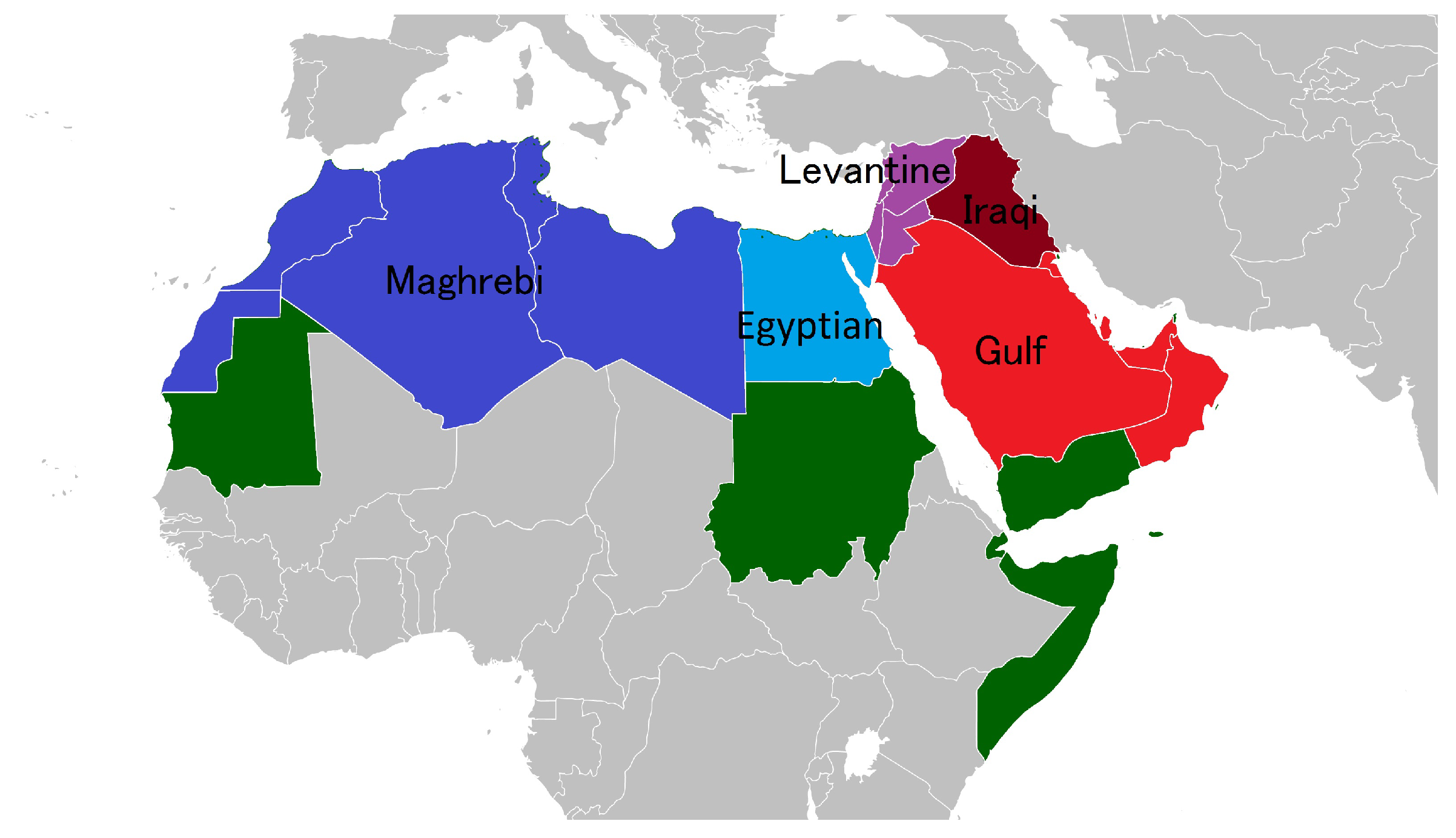
- Egyptian (EGY): An Egyptian dialect spoken in Egypt and is also commonly spoken because of the historical influence of Egyptian media.
- Gulf (GLF): A dialect spoken mostly in Saudi Arabia, the United Arab Emirates, Kuwait, Oman, Bahrain, and Qatar.
- Iraqi: The widely-spoken Arabic dialect by the people of Iraq.
- Levantine (LEV): A dialect spoken mainly by people from the Levant (in other words, people of Palestine, Jordan, Lebanon, and Syria).
- Maghrebi: A dialect of Arabic spoken in North Africa, except Egypt.
2. Related Work
3. Arabic Dialect Identification Model
3.1. The Feature Extractor
3.2. The Classifier System
3.2.1. Logistic Regression (LR)
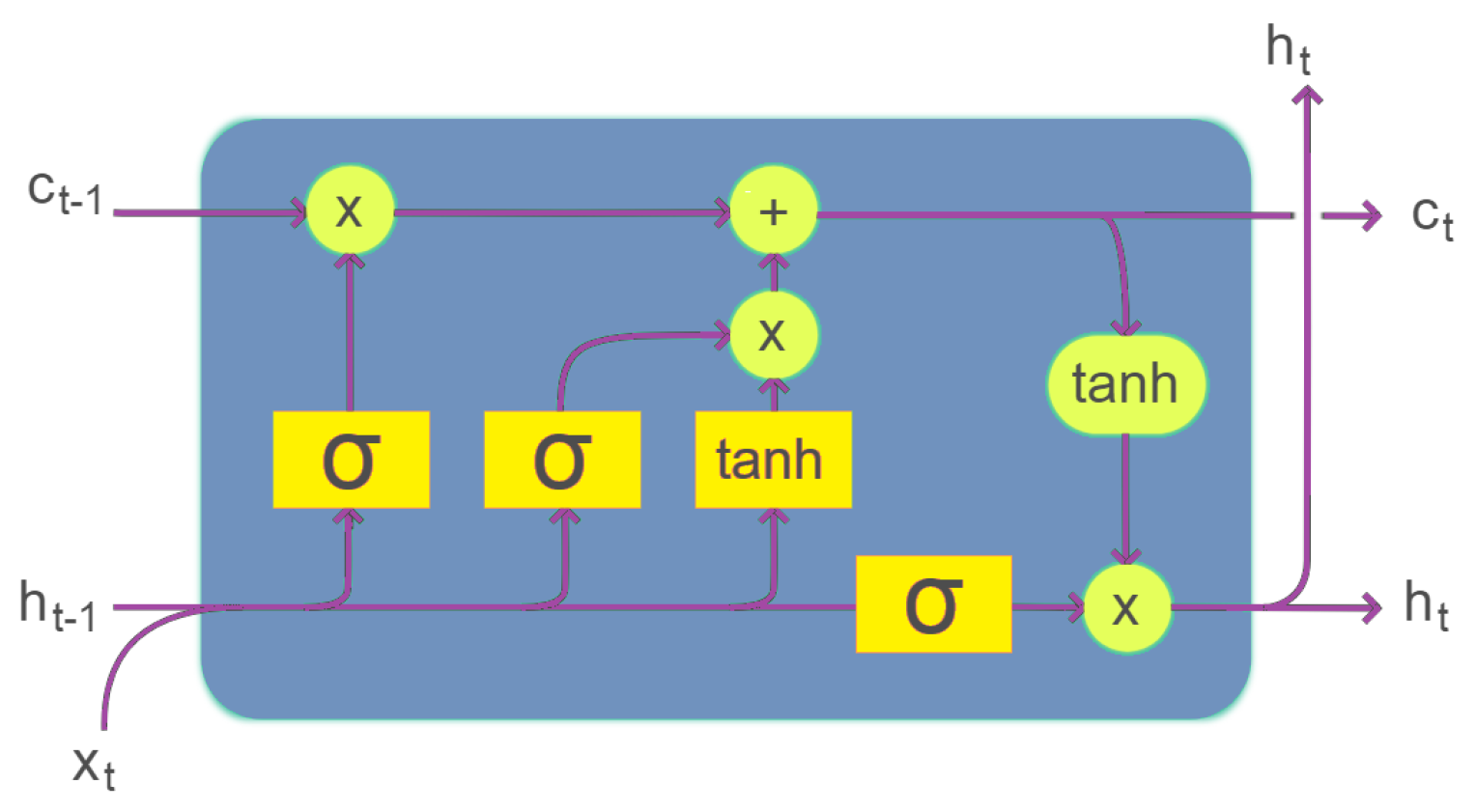
3.2.2. LSTM and BiLSTM
- Embedding Layer: Each word represented with 300 dimensions;
- Sequence length 30 time stamp;
- Dropout rate = 0.8;
- L2 norm of regularization;
- Relu activation;
- Dense Layer: 4 units with a softmax activation function.
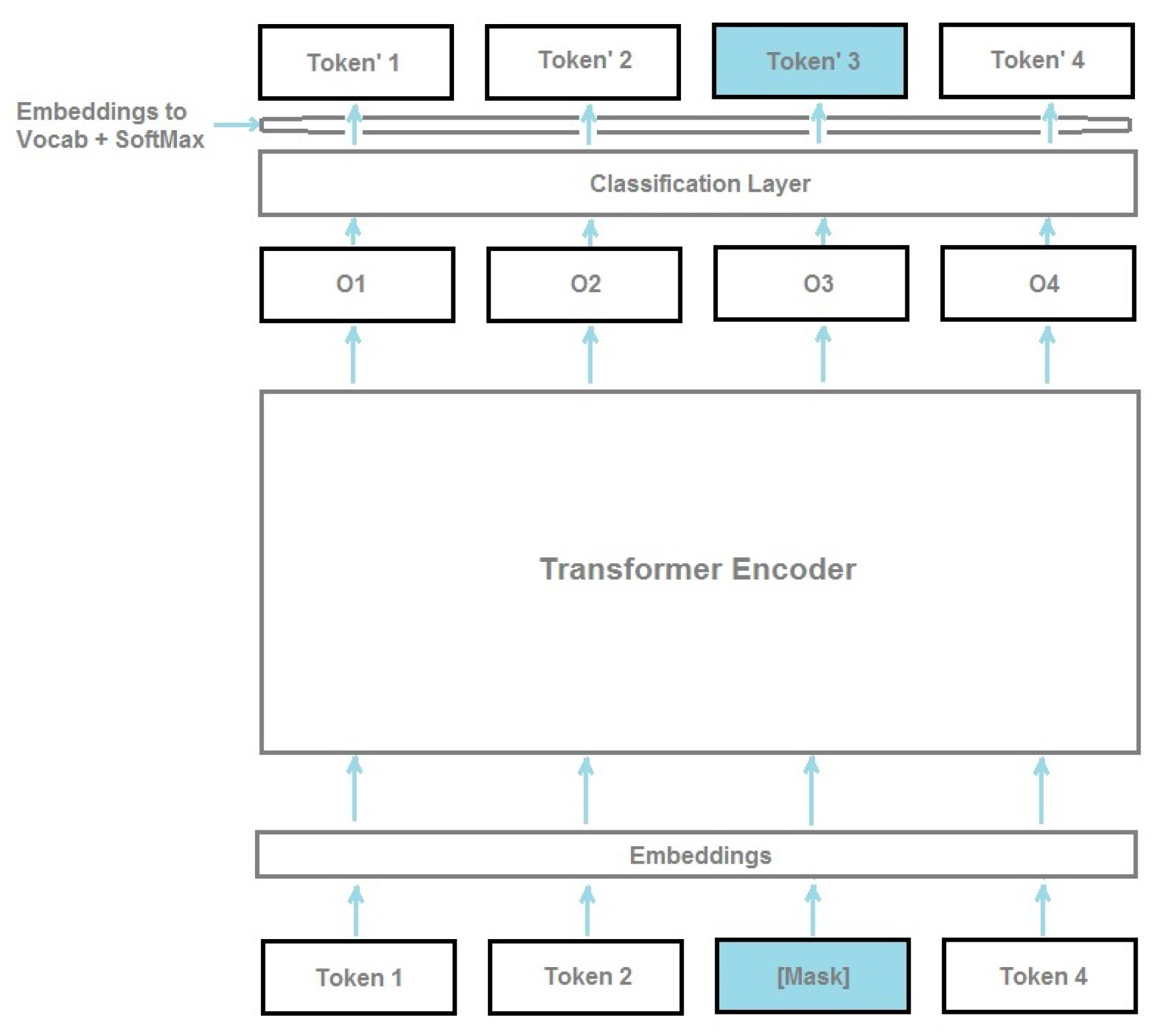
3.2.3. BERT Model
- ArabicBERT
- Hidden size: 768;
- Num attention heads: 12;
- Num hidden layers: 12;
- Vocab size: 32,000.
- AraBERT
- Hidden size: 768;
- Num attention heads: 12;
- Num hidden layers: 12;
- Vocab size: 64,000.
- MARBERT
- Hidden size: 768;
- Num attention heads: 12;
- Num hidden layers: 12;
- Vocab size: 100,000.
4. Experiments and Discussion
4.1. Embeddings Types
- AraBERT embeddings: This type uses the encodings of subwords used by the AraBERT model.
- ArabicBERT embeddings: Similarly, this type utilizes the subwords encodings of the ArabicBERT model.
- MARBERT embeddings: These are the encodings used by the MARBERT model.
- Twitter-City embeddings: 300-dimensional word vectors proposed in [39].
- AOC-based embeddings: These embeddings are extracted from a continuous bag of words model described in [13] to generate 300-dimensional word vectors.
- Random embeddings: These embeddings are generated by randomly initializing the input layer.
4.2. AOC-Based Results
4.3. COVID-19 Twitter Data Results
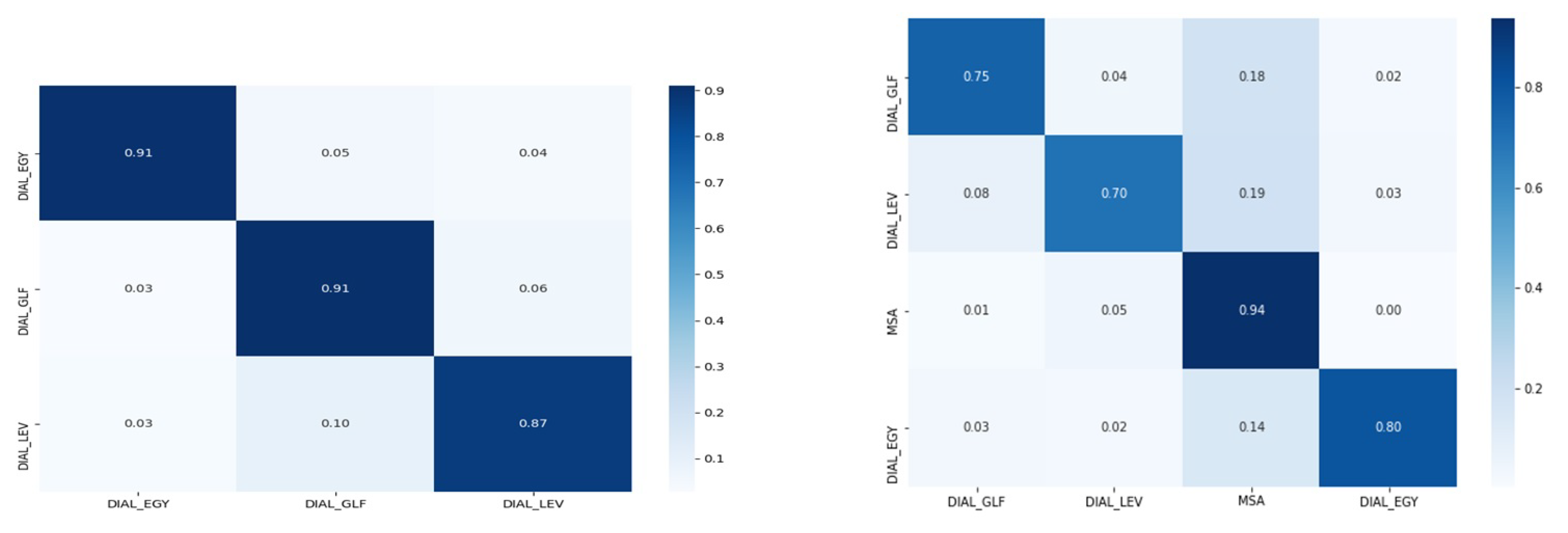
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Corona Virus Disease 2019 (COVID-19): Situation Report; World Health Organization: Geneva, Switzerland, 2020; Volume 83. [Google Scholar]
- World Health Organization. COVID-19 Weekly Epidemiological Update; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake shakes twitter users: Real-time event detection by social sensors. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 851–860. [Google Scholar]
- Palen, L.; Hughes, A.L. Social media in disaster communication. In Handbook of Disaster Research; Springer: Berlin/Heidelberg, Germany, 2018; pp. 497–518. [Google Scholar]
- Karami, A.; Shah, V.; Vaezi, R.; Bansal, A. Twitter speaks: A case of national disaster situational awareness. J. Inf. Sci. 2020, 46, 313–324. [Google Scholar] [CrossRef] [Green Version]
- Hariharan, K.; Lobo, A.; Deshmukh, S. Hybrid Approach for Effective Disaster Management Using Twitter Data and Image-Based Analysis. In Proceedings of the 2021 International Conference on Communication information and Computing Technology (ICCICT), Mumbai, India, 25–27 June 2021. [Google Scholar]
- Addawood, A. Coronavirus: Public Arabic Twitter Data Set. 2020. Available online: https://openreview.net/forum?id=ZxjFAfD0pSy (accessed on 22 November 2021).
- Imène, G.; Azouaou, F. Arabic dialect identification with an unsupervised learning (based on a lexicon) application case: Algerian dialect. In Proceedings of the 2016 IEEE Intl Conference on Computational Science and Engineering (CSE) and IEEE Intl Conference on Embedded and Ubiquitous Computing (EUC) and 15th Intl Symposium on Distributed Computing and Applications for Business Engineering (DCABES), Paris, France, 24–26 August 2016. [Google Scholar]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar] [CrossRef]
- Abdul-Mageed, M. Subjectivity and Sentiment Analysis of Arabic as a Morophologically-Rich Language. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, 2015. [Google Scholar]
- Abdul-Mageed, M.; Buffone, A.; Peng, H.; Eichstaedt, J.C.; Ungar, L.H. Recognizing pathogenic empathy in social media. In ICWSM; Springer: Berlin/Heidelberg, Germany, 2017; pp. 448–451. [Google Scholar]
- Zaidan, O.F.; Callison-Burch, C. The arabic online commentary dataset: An annotated dataset of informal Arabic with high dialectal content. In Proceedings of the ACL, Portland, OR, USA, 19–24 June 2011; pp. 37–41. [Google Scholar]
- Elaraby, M.; Abdul-Mageed, M. Deep models for Arabic dialect identification on benchmarked data. In Proceedings of the Fifth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2018), Santa Fe, NM, USA, 20 August 2018. [Google Scholar]
- Belinkov, Y.; Glass, J. A character-level convolutional neural network for distinguishing similar languages and dialects. arXiv 2016, arXiv:1609.07568. [Google Scholar]
- Shon, S.; Ali, A.; Glass, J. Mit-qcri arabic dialect identification system for the 2017 multi-genre broadcast challenge. arXiv 2017, arXiv:1709.00387. [Google Scholar]
- Shon, S.; Ali, A.; Glass, J. Convolutional neural networks and language embeddings for end-to-end dialect recognition. arXiv 2018, arXiv:1803.04567. [Google Scholar]
- Elfardy, H.; Diab, M. Sentence level dialect identification in Arabic. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; Volume 2, pp. 456–461. [Google Scholar]
- Elfardy, H.; Al-Badrashiny, M.; Diab, M. Aida: Identifying code switching in informal arabic text. In Proceedings of the First Workshop on Computational Approaches to Code Switching, Doha, Qatar, 25 October 2014; pp. 94–101. [Google Scholar]
- Zaidan, O.F.; Callison-Burch, C. Arabic dialect identification. Comput. Linguist. 2014, 40, 171–202. [Google Scholar] [CrossRef] [Green Version]
- Cotterell, R.; Callison-Burch, C. A multi-dialect, multi-genre corpus of informal written arabic. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 241–245. [Google Scholar]
- Darwish, K.; Sajjad, H.; Mubarak, H. Verifiably effective arabic dialect identification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1465–1468. [Google Scholar]
- Mousa, A. Deep Identification of Arabic Dialects. Informatics Institute. Bachelor’s Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2021. [Google Scholar]
- Elfardy, H.; Al-Badrashiny, M.; Diab, M. Code switch point detection in Arabic. In International Conference on Application of Natural Language to Information Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 412–416. [Google Scholar]
- Pasha, A.; Al-Badrashiny, M.; Diab, M.T.; El Kholy, A.; Eskander, R.; Habash, N. Madamira: A fast, comprehensive tool for morphological analysis and disambiguation of arabic. In Proceedings of the Lrec, Reykjavik, Iceland, 26–31 May 2014; pp. 1094–1101. [Google Scholar]
- Ragab, A.; Seelawi, H.; Samir, M.; Mattar, A.; Al-Bataineh, H.; Zaghloul, M.; Mustafa, A.; Talafha, B.; Freihat, A.A.; Al-Natsheh, H. Mawdoo3 AI at MADAR Shared Task: Arabic Fine-Grained Dialect Identification with Ensemble Learning. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019; pp. 244–248. [Google Scholar]
- Althobaiti, J.M. Automatic Arabic dialect identification systems for written texts: A survey. arXiv 2020, arXiv:2009.12622. [Google Scholar]
- Ghoul, D.; Lejeune, G. MICHAEL: Mining Character-level Patterns for Arabic Dialect Identification (MADAR Challenge). In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019; pp. 229–233. [Google Scholar]
- Přibáň, P.; Taylor, S. ZCU-NLP at MADAR 2019: Recognizing Arabic Dialects. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019; pp. 208–213. [Google Scholar]
- Harrat, S.; Meftouh, K.; Abidi, K.; Smaïli, K. Automatic identification methods on a corpus of twenty five fine-grained arabic dialects. In International Conference on Arabic Language Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 79–92. [Google Scholar]
- Huang, F. Improved arabic dialect classification with social media data. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2118–2126. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf-idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based model for Arabic language understanding. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 9–15. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Safaya, A.; Abdullatif, M.; Yuret, D. Kuisail at semeval-2020 task 12: Bert-cnn for offensive speech identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 2054–2059. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E. ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic. arXiv 2020, arXiv:2101.01785. [Google Scholar]
- Abdul-Mageed, M.; Alhuzali, H.; Elaraby, M. You tweet what you speak: A city level dataset of arabic dialects. In Proceedings of the LREC, Miyazaki, Japan, 7–12 May 2018; pp. 3653–3659. [Google Scholar]
- Clement, J. Countries with Most Twitter Users 2020. 2020. Available online: https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (accessed on 22 November 2021).
- Puri-Mirza, A. Saudi Arabia: Number of Internet Users 2023. 2019. Available online: https://www.statista.com/statistics/462959/internet-users-saudi-arabia/ (accessed on 22 November 2021).
- Mourtada, R.; Salem, F. Citizen engagement and public services in the arab world: The potential of social media. In Arab Social Media Report Series, 6th ed.; Mohammed Bin Rashid School of Government, SSRN: Dubai, United Arab Emirates, 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variety | MSA | EGY | GLF | LEV | ALL |
|---|---|---|---|---|---|
| Train | 50,845 | 10,022 | 16,593 | 9081 | 86,541 |
| Dev | 6357 | 1253 | 2075 | 1136 | 10,821 |
| Test | 6353 | 1252 | 2073 | 1133 | 10,812 |
| Embeddings Level | Embeddings Type | Model | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|---|
| Word (unigrams, bigrams, trigrams) | TFIDF | Logistic Regression | 0.7647 | 0.6723 | 0.7019 | 0.7703 |
| Word (unigrams) | TFIDF | Logistic Regression | 0.7949 | 0.667 | 0.712 | 0.7829 |
| Word (1k unigrams) | TFIDF | Logistic Regression | 0.7785 | 0.6635 | 0.7036 | 0.7756 |
| Word (5k unigrams) | TFIDF | Logistic Regression | 0.7972 | 0.6766 | 0.7199 | 0.7879 |
| Word (10k unigrams) | TFIDF | Logistic Regression | 0.7992 | 0.6727 | 0.7175 | 0.7861 |
| Word (20k unigrams) | TFIDF | Logistic Regression | 0.7986 | 0.6693 | 0.7149 | 0.7847 |
| Word (unigrams) | Random Embeddings | BiLSTM | 0.7783 | 0.7179 | 0.7389 | 0.7952 |
| Word (unigrams) | AOC Embeddings | BiLSTM | 0.778 | 0.7038 | 0.7309 | 0.7947 |
| Word (unigrams) | Twitter Embeddings | BiLSTM | 0.8046 | 0.7632 | 0.7811 | 0.8344 |
| Word (unigrams) | Random Embeddings | Attention BiLSTM | 0.7814 | 0.7097 | 0.7344 | 0.7932 |
| Word (unigrams) | AOC Embeddings | Attention BiLSTM | 0.78 | 0.6842 | 0.7189 | 0.7871 |
| Word (unigrams) | Twitter Embeddings | Attention BiLSTM | 0.8001 | 0.7577 | 0.7748 | 0.8278 |
| Subword | AraBERT Embeddings | AraBERT | 0.8086 | 0.7564 | 0.7777 | 0.8364 |
| Subword | ArabicBERT Embeddings | ArabicBERT | 0.8132 | 0.7677 | 0.787 | 0.8396 |
| Subword | MARBERT Embeddings | MARBERT | 0.8402 | 0.8000 | 0.8157 | 0.8586 |
| Embeddings Level | Embeddings Type | Model | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|---|
| Word (unigrams) | TFIDF | Logistic Regression | 0.87 | 0.83 | 0.85 | 0.853 |
| Word (1k unigrams) | TFIDF | Logistic Regression | 0.86 | 0.82 | 0.84 | 0.8423 |
| Word (5k unigrams) | TFIDF | Logistic Regression | 0.87 | 0.83 | 0.85 | 0.8553 |
| Word (10k unigrams) | TFIDF | Logistic Regression | 0.88 | 0.84 | 0.85 | 0.8568 |
| Word (20k unigrams) | TFIDF | Logistic Regression | 0.87 | 0.83 | 0.85 | 0.8548 |
| Word (unigrams, bigrams, trigrams) | TFIDF | Logistic Regression | 0.83 | 0.82 | 0.83 | 0.8315 |
| Word (unigrams) | Random Embeddings | BiLSTM | 0.8703 | 0.8531 | 0.8605 | 0.8659 |
| Word (unigrams) | AOC Embeddings | BiLSTM | 0.8522 | 0.8393 | 0.8449 | 0.8513 |
| Word (unigrams) | Twitter Embeddings | BiLSTM | 0.8742 | 0.8669 | 0.8703 | 0.876 |
| Word (unigrams) | Random Embeddings | Attention BiLSTM | 0.8568 | 0.8507 | 0.8533 | 0.8577 |
| Word (unigrams) | AOC Embeddings | Attention BiLSTM | 0.847 | 0.8375 | 0.8418 | 0.8473 |
| Word (unigrams) | Twitter Embeddings | Attention BiLSTM | 0.8792 | 0.8697 | 0.874 | 0.8793 |
| Word (unigrams) | Random Embeddings | Self Attention | 0.8325 | 0.8147 | 0.8221 | 0.8294 |
| Word (unigrams) | Twitter Embeddings | Self Attention | 0.8467 | 0.8221 | 0.832 | 0.8423 |
| Word (unigrams) | AOC Embeddings | Self Attention | 0.824 | 0.7935 | 0.8048 | 0.8158 |
| Word (unigrams) | Random Embeddings | Transformer Encoder | 0.8619 | 0.8536 | 0.8574 | 0.8585 |
| Word (unigrams) | Twitter Embeddings | Transformer Encoder | 0.8563 | 0.8462 | 0.8507 | 0.8573 |
| Word (unigrams) | AOC Embeddings | Transformer Encoder | 0.803 | 0.7753 | 0.7857 | 0.7995 |
| Subword | AraBERT Embeddings | AraBERT | 0.8802 | 0.8613 | 0.8692 | 0.8749 |
| Subword | ArabicBERT Embeddings | ArabicBERT | 0.8852 | 0.8654 | 0.8739 | 0.8739 |
| Subword | MARBERT Embeddings | MARBERT | 0.9039 | 0.8993 | 0.9011 | 0.9045 |
| Dropout Rate | Batch Size | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| 0.0 | 16 | 0.8198 | 0.7611 | 0.7872 | 0.8424 |
| 0.3 | 16 | 0.8166 | 0.7679 | 0.7882 | 0.8391 |
| 0.5 | 16 | 0.8204 | 0.7638 | 0.7889 | 0.8429 |
| 0.8 | 16 | 0.8173 | 0.7584 | 0.7844 | 0.8396 |
| 0.5 | 24 | 0.8454 | 0.8026 | 0.8177 | 0.8578 |
| 0.5 | 32 | 0.8504 | 0.7946 | 0.8156 | 0.8588 |
| 0.5 | 48 | 0.8423 | 0.7938 | 0.8053 | 0.8503 |
| 0.5 | 64 | 0.8338 | 0.8020 | 0.8066 | 0.8500 |
| 0.5 | 84 | 0.8511 | 0.8014 | 0.8203 | 0.8617 |
| Region | Number of Tweets | Accuracy |
|---|---|---|
| MSA | 1,373,869 | 97.7% |
| Gulf | 222,083 | 97.6% |
| Egyptian | 139,143 | 92.8% |
| Levantine | 34,037 | 99.6% |
| Total | 1,769,132 | 97.36% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Essam, N.; Moussa, A.M.; Elsayed, K.M.; Abdou, S.; Rashwan, M.; Khatoon, S.; Hasan, M.M.; Asif, A.; Alshamari, M.A. Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models. Appl. Sci. 2021, 11, 11328. https://doi.org/10.3390/app112311328
Essam N, Moussa AM, Elsayed KM, Abdou S, Rashwan M, Khatoon S, Hasan MM, Asif A, Alshamari MA. Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models. Applied Sciences. 2021; 11(23):11328. https://doi.org/10.3390/app112311328
Chicago/Turabian StyleEssam, Nader, Abdullah M. Moussa, Khaled M. Elsayed, Sherif Abdou, Mohsen Rashwan, Shaheen Khatoon, Md. Maruf Hasan, Amna Asif, and Majed A. Alshamari. 2021. "Location Analysis for Arabic COVID-19 Twitter Data Using Enhanced Dialect Identification Models" Applied Sciences 11, no. 23: 11328. https://doi.org/10.3390/app112311328